
json序列化模块
json模块
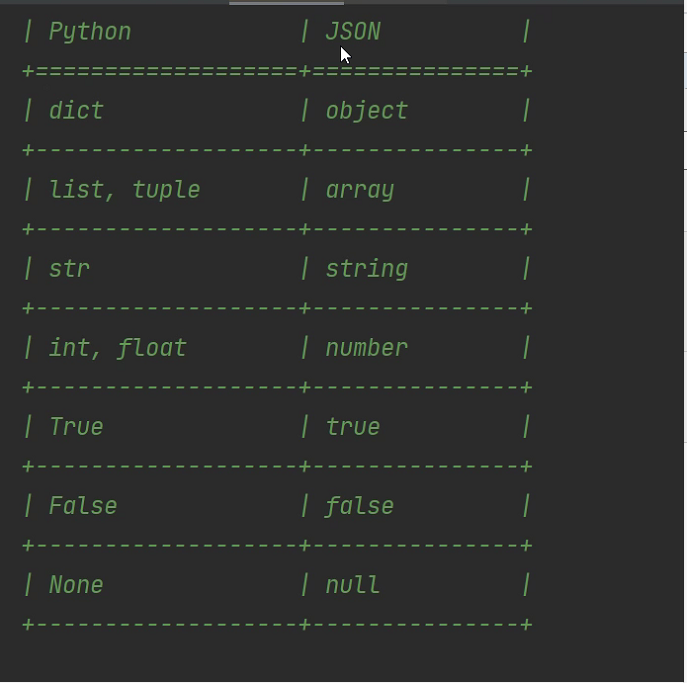
json格式数据:跨语言传输
暂且可以简单的理解为
序列化就是将其他数据类型转换成字符串过程
json.dumps()
反序列化就是将字符串转换成其他数据类型
json.loads()
1.json.dumps()
将python其他数据转换成json格式字符串(序列化)
{"username": "jason", "pwd": 123}
使用json.dumps()方法写入文件的字典为字典形式不过每个元素都是双引号引起来的
import json d = {'username': 'jason', 'pwd': 123} res = json.dumps(d) print(res,type(res)) # {"username": "jason", "pwd": 123} # 将字典d写入文件(str方法转换成字符串类型) with open(r'a.txt','w',encoding='utf8') as f: f.write(str(d)) # 将字典d写入文件(json方法序列化字典) with open(r'a.txt','w',encoding='utf8') as f: res = json.dumps(d) # 序列化成json格式字符串 f.write(res) # 带中文的需要修改参数 写入文件可显示中文(本质还是序列化) d1 = {'username': 'tony好帅哦 我好喜欢', 'pwd': 123,'hobby':[11,22,33]} print(json.dumps(d1,ensure_ascii=False))
2.json.loads()
将json格式字符串转成当前语言对应的某个数据类型(反序列化)
{'username': 'jason', 'pwd': 123} <class 'dict'>
使用json.dumps()方法写入文件的字典再使用json.loads()方法读出来还是字典形式并且可以直接使用,而以str写进文件的字典在取出dict字典化不能直接用
import json d = {'username': 'jason', 'pwd': 123} res = json.loads(res) print(res,type(res)) # {'username': 'jason', 'pwd': 123} <class 'dict'> bytes_data = b'{"username": "jason", "pwd": 123}' bytes_str = bytes_data.decode('utf8') bytes_dict = json.loads(bytes_str) print(bytes_dict,type(bytes_dict)) # 将字典d取出来(dict方法转换成字典类型) with open(r'a.txt','r',encoding='utf8') as f: data = f.read() print(dict(data)) # 将字典d取出来(json方法反序列化字典) with open(r'a.txt','r',encoding='utf8') as f: data = f.read() res1 = json.loads(data) print(res1,type(res1))
3.json.dump()
将python其他数据转换成json格式字符串(序列化) 区别于json.dumps()方法json.dump()直接转换和写入一步到位
import json d1 = {'username': 'tony', 'pwd': 123,'hobby':[11,22,33]} with open(r'a.txt', 'w', encoding='utf8') as f: json.dump(d1, f)
4.json.load()
将json格式字符串转成当前语言对应的某个数据类型(反序列化) 区别于json.loads()方法json.load()直接转换和读取一步到位
import json d1 = {'username': 'tony', 'pwd': 123,'hobby':[11,22,33]} with open(r'a.txt','r',encoding='utf8') as f: res = json.load(f) print(res,type(res))
# 字典写入文件 读出字典可以正常使用
5.json.JSONEncoder
并不是所有的数据类型都支持序列化
查看支持的数据类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号