使用Python + Selenium破解滑块验证码
在前面一篇博客《使用 Python + Selenium 打造浏览器爬虫》中,我介绍了 Selenium 的基本用法和爬虫开发过程中经常使用的一些小技巧,利用这些写出一个浏览器爬虫已经完全没有问题了。看了前一篇博客,可能有人会有疑惑,浏览器爬虫的优势感觉并不比传统爬虫多多少啊,特别是通过遍历页面元素来获取爬虫数据的方式和传统爬虫解析 HTML 文档结构的方式如出一辙。为了体现浏览器爬虫的优越性,我特意准备了这篇博客,来看看如果要破解滑块验证码,浏览器爬虫比传统爬虫要容易多少。
一、滑块验证码简述
有爬虫,自然就有反爬虫,就像病毒和杀毒软件一样,有攻就有防,两者彼此推进发展。反爬技术历经多年,从最简单的检测 UserAgent 或者 Referrer 等头部,到限制访问频率封 IP 等手段,到关键路径的行为识别,到前端页面的混淆和加密,到目前最流行的验证码技术,可以说,为了防止网络上大量爬虫的肆意妄为,特别是一些垃圾机器人,技术人员真的是绞尽脑汁。但是道高一尺魔高一丈,直到目前为止,也并没有完全无懈可击的反爬方案。
目前最流行的反爬技术是验证码,几乎所有网站的注册页面都会用到验证码技术,为了防止爬虫自动注册,批量生成垃圾账号。验证码技术从一诞生,就是黑客们最感兴趣的话题,验证码的英文为 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),翻译成中文就是 全自动区分计算机和人类的公开图灵测试,它是一种可以区分用户是计算机还是人的测试,只要能通过 CAPTCHA 测试,该用户就可以被认为是人类。使用计算机模拟人类的行为一直以来都是黑客们最热衷的事情,也是黑客们梦寐以求的理想。所以验证码技术从一提出,就有大量的人尝试破解,其实这些人并不是为了制造垃圾爬虫,他们只是相信计算机可以和人一样,阿西莫夫的机器人世界在未来是可能的。
最初的验证码只是一张图片,图片上显示扭曲变形的文字和数字,这样的验证码通过图像处理和识别的技术可以达到很高的识别率。后来验证码技术又在图片上加入了各种干扰项,并且将字符粘连在一起,增加了字符切割和识别的难度,但是很快人们就想出了很多种不同的去噪方法,并使用骨架算法切割粘连字符,还有些人提出使用机器学习算法来切割字符。和图片验证码类似的是语音验证码,不过这种验证码只是在表现形式上有所区别,实质上和图片并没有太大的变化,采用语音识别技术破解也不是难事。而且语音和图片比起来缺乏交互,花样要少很多,识别难度也要低一些,所以只有在给盲人或者对颜色分辨有障碍的人提供服务时才可能会使用语音验证码,一般情况下使用的比较少。在静态的图片验证码被破解之后,又出现了动态的图片验证码,将字符动态的显示在 gif 动画上,不过这也没什么用,通过图像识别技术一样可以破解,实在破解不了的,还可以通过网上一些廉价的打码平台来人肉识别。
打码平台的诞生可以说是验证码领域的一件大事,它虽然不是什么高科技,只是把全世界廉价的劳动力汇集在了一起,就这样,再复杂的验证码都不在话下。这虽然不是什么光荣的事,但是它推动了验证码技术的发展,交互式验证码被开发出来。传统的图片验证码采用一问一答的形式,只要答案正确,就认为验证通过,它并不关心答案是怎么来的,所以出现了一些人工打码平台,你提供一个问题,它们提供一个答案,仅此而已。如果不仅仅关注答案的正确性,还将提交答案的过程记录下来,通过分析提交答案的过程,完全可以识别出这是不是一个人在操作,这就是交互式验证码的基本思路。这种验证码很难通过打码平台来破解,因为你必须对着浏览器,使用鼠标对验证码进行一系列的交互操作。
最耳熟能详的交互验证码莫过于 12306 的了,这种验证码叫做 图中点选 式验证码,同时提供多个图像,让用户根据条件点击选择。也有些验证码是同时显示 N 个变形的汉字让你选,原理与 12306 的类似,但这种验证码以其极差的用户体验遭到很多人的唾弃,这也是大多数产品不愿意选用的一个原因。滑块验证码 比图中点选体验好很多,它只需要用户使用鼠标将滑块从某个位置拖动到另一个位置即可。程序通过记录用户拖动滑块的轨迹,这一串的轨迹数据采用模式识别的手段就可以判断出这是否是真人在操作。最简单的滑块验证码是用户拖动滑块从左拖到右即可,后来又出现了 拼图式 的滑块,滑块作为图的一部分,然后背景图中有一个缺口刚好和滑块相同形状,需要用户将滑块拖到缺口中拼成一张完整的图片。现在比较流行的滑块验证码有 极验 和 网易云易盾,本篇博客以极验的滑块验证码为例,其他的滑块验证码原理是类似的。
最新的交互式验证码甚至只需要用户点击一个按钮即可验证,不需要做任何其他的操作,譬如 极验的第三代行为验证技术 和 易盾的智能无感知验证码。这种验证码的破解方式和滑块验证码不一样,我目前也没有太多的了解,后面有时间再研究研究吧。
最后不得不说的是,还有一种交互式验证码为短信或电话验证码,通过将验证码以短信的形式发送到你的手机,或者使用语音机器人自动打电话播报验证码,更有甚者,需要用户自己编辑短信将验证码发送到某个号码。对于这种验证码我认为并不能算作是 CAPTCHA,因为它利用的是用户的有限资源(手机号)这个客观限制,而并非是从技术角度来区分人和机器人的区别。如果某个人拥有大量的手机号(其实,黑产中确实也有专门养卡卖卡的),这种验证手段就形同虚设了。
二、破解思路
目前,极验正在推广其第三代行为验证技术,滑块验证码貌似已经没有前两年那么流行了,不过仍然有很多网站还在使用滑块验证码。譬如我这篇博客就以 春秋航空的会员注册页面 为例。
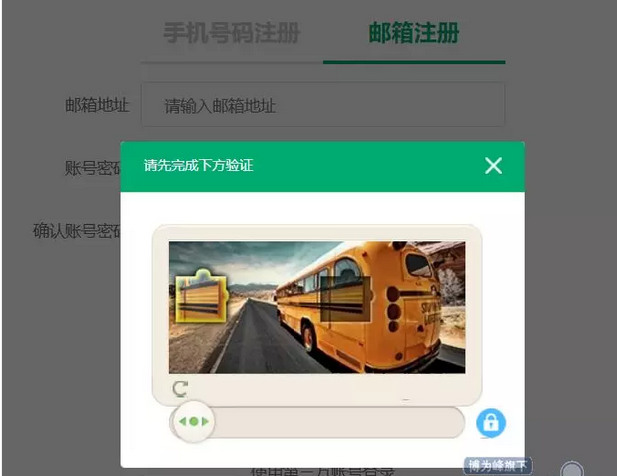
好了,上面讲了那么多,下面就开始我们的破解之旅吧。
2.1 传统爬虫
如果采用传统爬虫的方式来破解,首先我们需要测试下正常验证的情况是什么样的。在 Chrome 浏览器中按 F12 打开开发者工具,然后拖动滑块到正确位置,可以观察到 Network 面板发送的 Ajax 请求。

可以看到这个请求的参数非常复杂,每个参数的含义也完全没有头绪,如果要破解这个验证码,则必须模拟发送这个请求,这个请求的每个参数都必须弄清楚,于是我们在代码中搜索发送这个请求的地方。但事实上到这里我们就遇到了困难,ajax.php 这个请求根本就搜不到,甚至在浏览器中下 XHR 断点也不行(很显然它并不是一个 Ajax 请求),这是因为极验的核心代码经过了代码混淆。
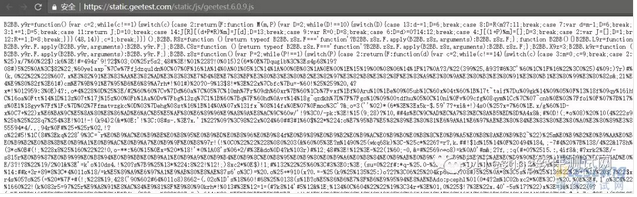
这样的代码也就只有机器能读懂,大多数人肯定是直接放弃了。不过网上也有大量的分析文章,如果你感兴趣可以自己研究下,譬如 Windows应用开发 的知乎专栏上就有几篇介绍 极验验证码破解的系列文章,还有 FanhuaandLuomu 的 这篇破解文章 也写得很好,推荐。
我在这里跳过对混淆代码的分析,总结下破解这样的滑块验证码的思路:
1、捕获所有关键请求;
2、分析调试混淆的代码,弄懂每个请求每个参数的含义,其中肯定会有一个参数,是拖动滑块的轨迹;
3、验证码图片是打乱的,需要解析页面上的样式,并使用图像处理方法还原出原始图像;
4、根据原始的图像和滑块位置得到缺口的偏移量;
5、滑块轨迹的模拟;
6、如果参数有加密处理,还需要模拟它的加密过程;实在不行可以直接在代码里模拟执行页面上的 JS;
7、...
可见这里的工作量非常大,破解难度可想而知,而且混淆的代码随时可能会发布新的版本,一旦版本升级,参数都有可能发生变化,之前的所有分析工作都可能前功尽弃。
除非实在是迫不得已,我并不推荐传统的这种破解方法。首先这样的破解方法太脆弱,不够通用,随时可能失效;其次这样的破解工作费时费力,就算破解出来也得不到成就感和满足感,对程序员的打击太大,他可能再也不会玩第二次了(除非他是极客中的极客,就以破解混淆代码为乐)。所以,还是让我们来看看浏览器爬虫如何。
2.2 浏览器爬虫
由于浏览器爬虫完全是以人为第一视角,你所看到的,就是浏览器爬虫看到的,甚至,它能比你看到更多。我们可以大概的总结下浏览器爬虫的破解思路:
-
图像识别,找到滑块的位置和缺口的位置;
-
模拟鼠标拖动,将滑块拖到缺口位置;
没错,就两步。虽然其中会遇到一些坑,但真的就这两步。使用上一篇博客中介绍的 Selenium 技巧,可以很快的写下下面的代码:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--start-maximized")
browser = webdriver.Chrome(
executable_path="./drivers/chromedriver.exe",
chrome_options=chrome_options
)
browser.get('https://account.ch.com/NonRegistrations-Regist')
Wait(browser, 60).until(
Expect.visibility_of_element_located((By.CSS_SELECTOR, "div[data-target='account-login']"))
)
email = browser.find_element_by_css_selector("div[data-target='account-login']")
email.click()
Wait(browser, 60).until(
Expect.visibility_of_element_located((By.ID, "emailRegist"))
)
register = browser.find_element_by_id("emailRegist")
register.click()
offset = get_gap_offset(browser)
drag_and_drop(browser, offset)
关键就在于最后两个方法 get_gap_offset() 和 drag_and_drop(),下面就来看下这两个方法的实现。
三、验证码图片处理
审查验证码图片元素,可以看到下面这样的 HTML 代码:
<div class="gt_cut_fullbg_slice" style="background-image: url('https://static.geetest.com/pictures/gt/3999642ae/3999642ae.webp'); background-position: -157px -58px;"></div>
这样的代码一共有 52 行,每一个 div 都是 10px * 58px 的小块。我们打开这个 background-image 对应的图片可以看出这是一张乱序的图片,这里的 background-position 用于显示出正确的图片。在代码上面,可以发现和这里完全类似的代码,background-position 都完全一样,只是 background-image 不一样,我们打开对应的图片,也是乱序的,但和上一张图片对比,可以猜测出,这是带有缺口的背景图片。
<div class="gt_cut_bg_slice" style="background-image: url('https://static.geetest.com/pictures/gt/3999642ae/bg/fbdb18152.webp'); background-position: -157px -58px;"></div>
一个很自然的想法就是把这两张乱序的图片根据 background-position 重组成两张看得懂的图片,然后对比两张图片,得到缺口的偏移量,然后将缺口偏移量减去滑块偏移量,就可以得到要拖动的偏移量。如下图所示:

其中滑块的偏移量可以通过下面的代码得到(其中,left: 12px 就是滑块的偏移量):
<div class="gt_slice gt_show" style="left: 12px; background-image: url('https://static.geetest.com/pictures/gt/e6e7e0440/slice/fa2d5bbd8.png'); width: 55px; height: 55px; top: 20px;"></div>
这里需要用到一点点图像处理的知识,我们采用大名鼎鼎的 Pillow,Pillow 是 Python 里的图像处理库(PIL:Python Image Library),在开始之前,可以先看下它的官网教程,这里有一份中文文档也可以参考。计算缺口偏移量的关键代码如下:
def get_slider_offset(image_url, image_url_bg, css):
image_file = io.BytesIO(requests.get(image_url).content)
im = Image.open(image_file)
image_file_bg = io.BytesIO(requests.get(image_url_bg).content)
im_bg = Image.open(image_file_bg)
# 10*58 26/row => background image size = 260*116
captcha = Image.new('RGB', (260, 116))
captcha_bg = Image.new('RGB', (260, 116))
for i, px in enumerate(css):
offset = convert_css_to_offset(px)
region = im.crop(offset)
region_bg = im_bg.crop(offset)
offset = convert_index_to_offset(i)
captcha.paste(region, offset)
captcha_bg.paste(region_bg, offset)
diff = ImageChops.difference(captcha, captcha_bg)
return get_slider_offset_from_diff_image(diff)
代码很好理解,就是根据 css 将两张背景图片重新排序生成两张新图片,然后通过 ImageChops.difference() 方法得到两张图片的差值图像,最后通过差值图像得到缺口的偏移量。其中有一点要注意的是,Pillow 的 Image.open() 方法只支持文件,不支持 URL,所以将图片转换为 BytesIO 对象,BytesIO 和 StringIO 一样,是 Python 提供的在内存中操作 bytes 和 str 的类,并且和读写文件具有一致的接口。
这种计算缺口位置的方法需要解析页面源码以及图片的 CSS 样式,其实还有一种更简单的方法:在显示验证码图片时对浏览器进行截图,这个时候的图像是完整的背景图像;然后再点击滑块,这个时候滑块和缺口都会显示出来,再对浏览器进行截图;分析两次的截图也可以计算出拖动的偏移量。有兴趣的同学可以一试。
......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号