
算法——计算算法效率
度量
度量一个程序(算法)的执行时间有两种办法:
1 事后统计法
2 事前统计法
事后统计法
计算一个程序或算法,跑完后总共用时。这种方法可行,但是有两个不足:1:必须得运行后才能得到结果。2:所得的时间统计量还依赖于计算机的硬件、软件等环境因素,无法很简单的一口咬定是算法的所有的时间。
事前统计法
通过分析某个算法的时间复杂度来判断哪个算法更加优化
算法的时间复杂度:
时间频度:
一个算法花费的时间与算法中语句的执行次数成正比例,那个算法中语句执行次数多,它花费的时间就多。一个算法中的语句执行次数称为语句频度或者时间频度,记为T(n)。
比如:
int sum=0;
for(int i=0;i<n;i++)
{
sum+=i;
}
这个for循环中的算法的时间频度T(n) = n;
时间频度的特点
1 忽略常数项。
2 忽略低次项。
3 忽略系数。
忽略常数项
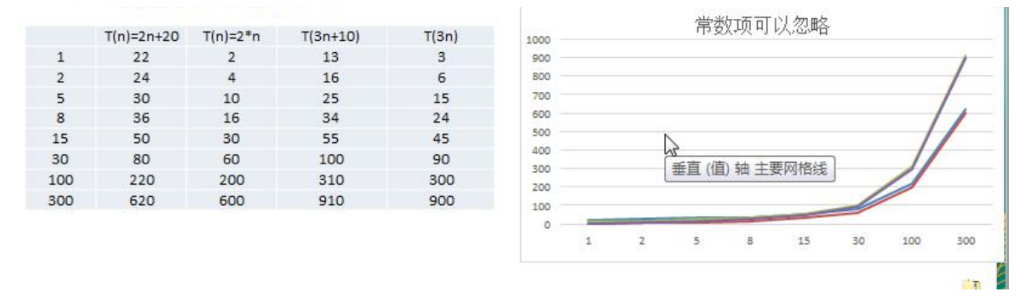
1) 2n+20 和 2n 随着 n 变大,执行曲线无限接近, 20 可以忽略
2) 3n+10 和 3n 随着 n 变大,执行曲线无限接近, 10 可以忽略
结论:时间频度可以忽略常数项
忽略低次项
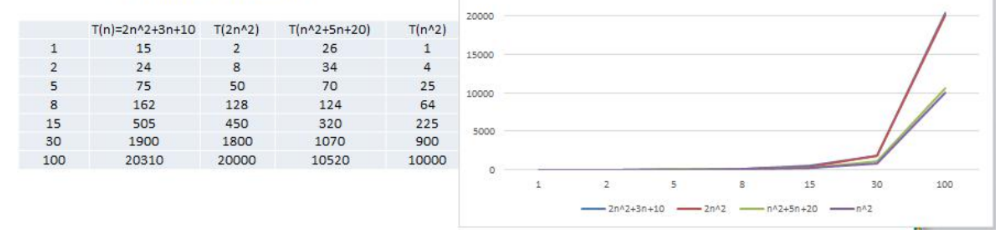
1) 2n^2+3n+10 和 2n^2 随着 n 变大, 执行曲线无限接近, 可以忽略 3n+10
2) n^2+5n+20 和 n^2 随着 n 变大,执行曲线无限接近, 可以忽略 5n+20
结论:时间频度可以忽略低次项
忽略系数:
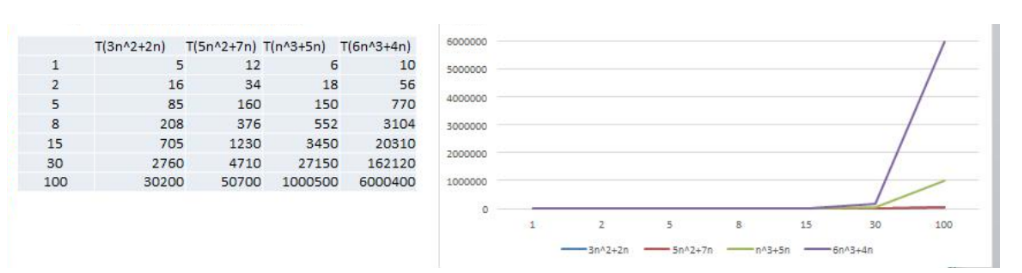
1) 随着 n 值变大,5n^2+7n 和 3n^2 + 2n ,执行曲线重合, 说明 这种情况下, 5 和 3 可以忽略。
2) 而 n^3+5n 和 6n^3+4n ,执行曲线分离,说明多少次方式关键
结论:时间频度可以忽略系数
时间复杂度
一般情况下,算法中的基本操作语句的重复执行次数是问题规模n的某个函数,用T(n)表示,也就是前面的时间频度,若有某个辅助函数f(n),使得当n趋近与无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。简单来说就相当于把前面的时间频度使用时间频度的特点后的最简化的结果。
T(n)不同但是时间复杂度是完全可以相同的。
计算时间复杂度的办法:
简单来说就相当于把前面的时间频度使用时间频度的特点后的最简化的结果,就是对T(n)去掉常数项,去掉低次项,去掉系数的结果。
常见的时间复杂度
1) 常数阶 O(1)
2) 对数阶 O(log2n)
3) 线性阶 O(n)
4) 线性对数阶 O(nlog2n)
5) 平方阶 O(n^2)
6) 立方阶 O(n^3)
7) k 次方阶 O(n^k)
8) 指数阶 O(2^n)
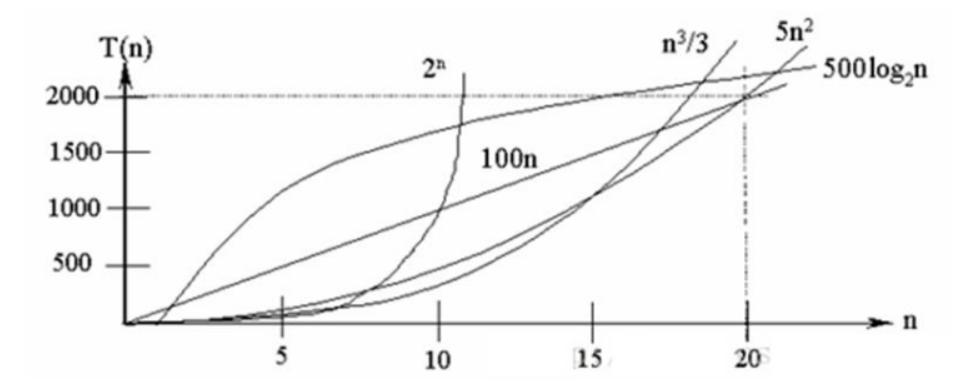
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)< Ο(n的k次方) <Ο(2的n次方) ,随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低 应该尽可能避免使用指数阶的算法
时间复杂度的分类
时间复杂度分为三种情况:
1 最好情况
2 最坏情况
3 平均情况
最好情况
这个没啥价值的,就是对于排序而言最好的情况就是已经排好序了
平均情况
平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间
最坏情况
最坏情况下的时间复杂度称为最坏时间复杂度。一般讨论的时间复杂度都是在最坏的情况下的时间复杂度。这样可以保证算法的运行时间不会比最坏的情况还糟糕,相当于是一个运行时间的界限。
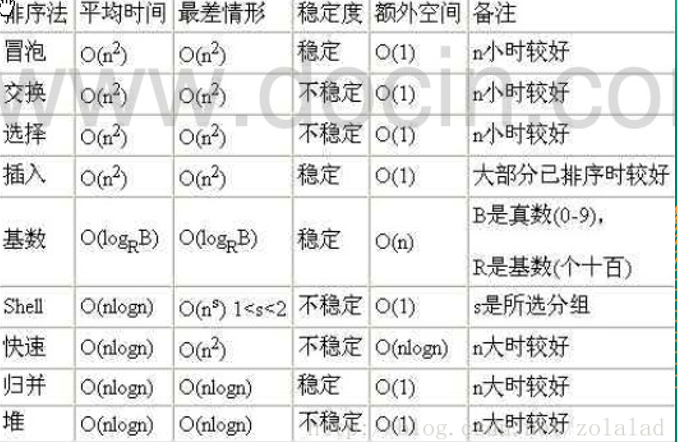
平均情况和最坏情况的时间复杂度是否一致和算法有关:
算法的空间复杂度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号