歇工几天,将最近所做的工作进行总结一下,首先进行PCA处理
完成目标:对一个文件下所有.csv文件进行PCA,得到5个主成分,并将其得到的结果另存一个文件下相应名字的.csv文件中
第一步:处理好的原始数据放在一个文件夹下,如下我的文件夹下包含三个.csv数据文件


第二步:程序批量处理
from sklearn.preprocessing import StandardScaler
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import k_means
import csv
import numpy as np
import os
def standard_pca_kmeans(file_path, n_component, k, save=True):
# 读取目标文件中相应的表
df = pd.read_csv(file_path, header=None)
# 获取需要进行处理的数据,保留第1列,并转化为numpy数组
data_useful = np.array(df)
data_useful=data_useful.T
# 对数据进行标准化处理以进行PCA(相关阵法)
scaler = StandardScaler().fit(data_useful)
data_scaled = scaler.transform(data_useful)
# 对数据进行PCA降维处理
pca = PCA(n_components=n_component).fit(data_scaled)
data_pca = np.dot(pca.components_, data_scaled.T).T
print('当选取%s个主成分时,累计方差贡献率为%s' % (n_component, sum(pca.explained_variance_ratio_)))
# 对降维后的数据进行聚类
kmeans = k_means(data_pca, k)
lables = kmeans[1]
# 整合成一个表
print(data_pca.shape)
result = pd.DataFrame(data_pca, columns=['第%s主成分' % (i + 1) for i in range(n_component)])
if save:
return result, data_pca, data_scaled
#result.to_csv('C:\\Users\\Administrator\\Desktop\\mean\\PCAspon7结果.csv')
if __name__ == '__main__':
#批量读取文件夹下的数据文件
def get_file(path): # 创建一个空列表
files = os.listdir(path)
list1 = []
for file in files:
if not os.path.isdir(path + file): # 判断该文件是否是一个文件夹
f_name = str(file)
# print(f_name)
tr = '\\' # 多增加一个斜杠
filename = path + tr + f_name
# filename = f_name
list1.append(filename) # 得到所有
return list1#返回.csv文件路径
f1 = get_file('C:\\Users\\Administrator\\Desktop\\yuanshispike') # 得到文件夹下所有数据文件的路径
data = []
for file in f1:
filename=os.path.basename(file)#截取文件名
result, data_pca, data_scaled = standard_pca_kmeans(file, 5, 3)
meansignal = pd.DataFrame(data=result)
datapath1 = 'C:\\Users\\Administrator\\Desktop\\combine\\' + filename#新建文件夹,将得到的结果保存在该路径下
meansignal.to_csv(datapath1, index=True) # 进行数据的保存
输出结果,主成分根据自己的数据自行定义,此时累计方差贡献率已经很高了。

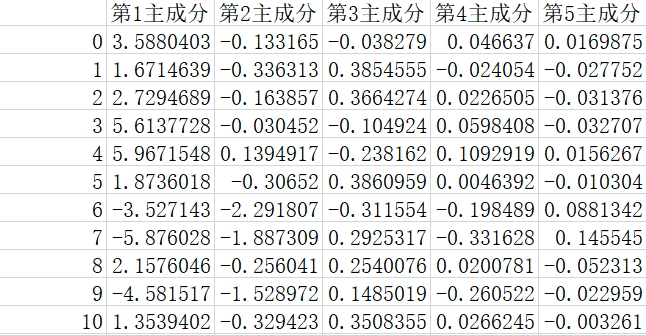
此时发现该文件夹下已经存在了相应名字的PCA数据结果了
文件中的结果如下所示
PCA被称作是主成分分析,该算法的作用是将高维数据通过降维的方法转换低维度进行数据处理,相当于在原始坐标轴基础上对数据的点重新建立一个坐标轴,从而达到用更少的主要属性来区分出数据的类别(仅是个人理解)详细请看:https://blog.csdn.net/program_developer/article/details/80632779

 浙公网安备 33010602011771号
浙公网安备 33010602011771号