实现目标:一个文件夹下包括n个.csv数据文件,想将后缀为ts.csv的文件与对应数字的.csv文件进行合并
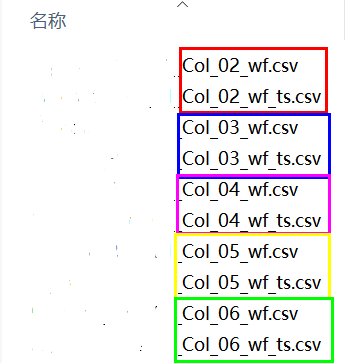

此图为wf.csv文件中的数据格式,ts.csv文件是与此文件等行数的一列数据,将此列数据添加到已有18列数据的后面,完成数据合并操作
代码如下:
import pandas as pd
from pandas import DataFrame
import os
import numpy as np
import csv
import xlrd
import xlwt
import time
# https://www.cnblogs.com/nxf-rabbit75/p/10105271.html替换一些小技巧
path = r'C:\Users\Administrator\Desktop\mat'#文件夹路径
def get_file(): # 创建一个空列表
files = os.listdir(path)
list = []
for file in files:
if not os.path.isdir(path + file): # 判断该文件是否是一个文件夹
f_name = str(file)
# print(f_name)
tr = '\\' # 多增加一个斜杠
filename = path + tr + f_name
#filename = f_name
list.append(filename)#得到所有数据文件的名字
return list
list = get_file()
#start=time.time()
i=0
for f in list[1::2]:
df = pd.read_csv(f,header=None) # 每个csv文件中的数据
data1 = np.array(df) # 把表格转换成数组的格式
df1 = pd.read_csv(list[i],header=None) # 每个csv文件中的数据
data2 = np.array(df1) # 把表格转换成数组的格式
#np.insert(data2, 18, values=data1, axis=1)
data3=np.c_[data2,data1]#将data1数据加载在data2数据列后面
dfdata = pd.DataFrame(data=data3)
filename=os.path.basename(list[i])#截取文件名
datapath1 = 'C:\\Users\\Administrator\\Desktop\\combineFile\\' + filename
dfdata.to_csv(datapath1,index=False,header=None) # 进行数据的保存
i=i+2
#end=time.time()
#print("此程序一共运行%s"%(end-start))
转换成功啦!
一定要注意如果建立了numpy.array是不能改变原有数组的值,只能新建一个变量进行保存生成的数据!!!
给numpy矩阵添加一列的方法和实例:https://blog.csdn.net/weixin_39624716/article/details/111434490?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-2&spm=1001.2101.3001.4242

 浙公网安备 33010602011771号
浙公网安备 33010602011771号