Redis设计与实现(十四)复制
在Redis中,用户可以通过SLAVEOF命令或者slaveof选项让一个redis服务器去复制另外一个服务器的数据,这个复制是所有的库。
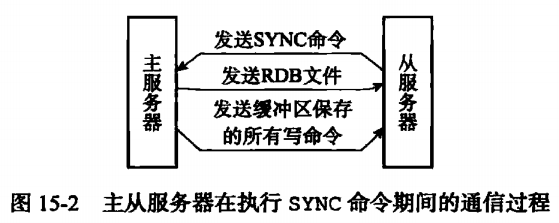
在执行SLAVEOF的时候,从服务器会向主服务器发送一个SYNC命令,主服务器收到SYNC命令之后会进行BGSAVE命令(也就是生一个子进程进行RDB操作),然后生成完RDB之后将对应的东西重新返回给从服务器,从服务器进行载入。那么从服务器就可以和主服务器一样得到某一时刻的同步,如果在生成RDB的时候,主服务器依然在进行命令的处理,那么主服务器就会将这些命令发送给从服务器。完成最新时刻的同步,之后的时间内一旦主服务器收到Command,就会给从服务器也发送一份(也就是命令传播)。
在2.8之前的Redis对于主从复制的功能有个缺陷就是,如果是初次启动的Redis从服务器进行SLAVEOF命令是正常的,逻辑上也是没问题的,但是如果是断线后的重新连接,如果依然是进行的SLAVEOF,那么效率就相对比较低下,问题的来源在于,主服务器执行BGSAVE的时候,然后生成了子进程,但是依然会占用很多资源,同时进行传输的时候会有很多的带宽的损失。虽然这一操作是一个看起来很完善的操作,但是问题在于因为强一致性损失了性能。

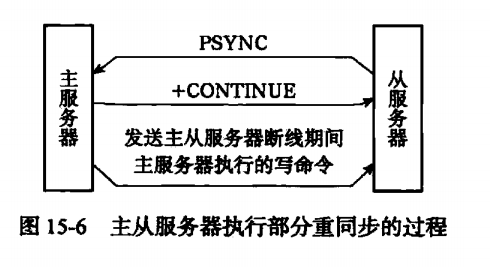
所以在2.8之后,redis是使用了PSYNC代替了之前的SYNC操作,PSYNC操作具有完成重同步和部分重同步这两种操作,简单的收完全重同步是和之前的SYNC一样的。部分重同步这个就是针对断线后的重连接进行的,这边需要思考的是(是不是断线后的所有情况都满足这个,以及如何准确的判断从服务器断线的节点),假设有个场景,主服务器每秒百万次写操作,从服务器每秒十万次读操作。从服务器每断开一秒都会造成和主服务器百万次的指令之差,那么主服务器如何对从服务器的断开连接进行准确判断的呢(心跳机制是肯定的)。
部分重同步由以下三个功能组成:主服务器的复制偏移量和从服务器的复制偏移量;主服务器的复制积压缓冲区;服务器的运行ID
主服务器和从服务器的复制偏移量很好理解,就是服务器内每次接收到数据,进行累加,通过这个属性进行对比就可以很轻松知道服务器是否处于一致状态了。
复制积压缓冲区是一个FIFO的队列。默认大小是1MB,当主服务器进行命令传播的时候,不光会发送给从服务器,也会填入复制积压缓冲区。
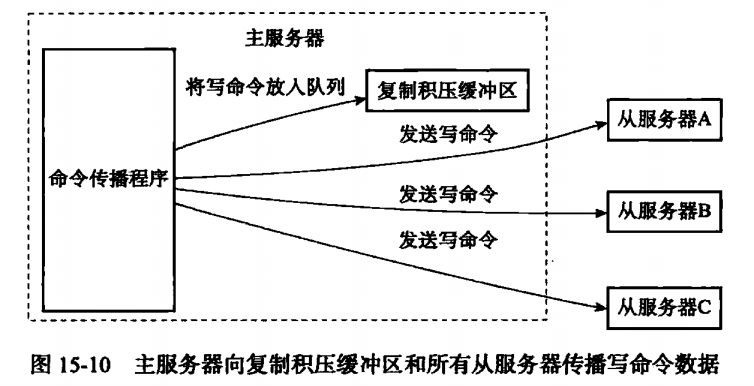
因此,主服务器的复制积压缓冲区,会保存着最近传播的命令。并且记录下对应的偏移量。

如果复制积压缓冲区中保存这对应的指令,那么就会发送断线的从服务器,已经主服务器在这一时间完成了太多了command导致复制缓存积压区里面的数据已经被去除了,那么就只能进行完全重同步了。

服务器ID这个就不用说了,是用来标识服务器的。
PSYNC指令的实现:
1.如果从服务器没有进行过和主服务器之间的连接,那么在输入SLAVEOF XXX.XXX.XX.XX:XXX的时候,实际上会发送一个PSYNC ? -1的command,作用是为了进行一次完全同步,也就是主服务器进行一次RDB(是否每个从服务器发送过来SLAVEOF 都需要进行一次RDB?)
2.如果进行过和主服务器的完全同步,那么就会发送PSYNC <runid> <offset>这个指令,runid表示上次和主服务器进行完全同步时候留下的标识,offset表示偏移量。
主服务器收到command之后会返回命令有三种:
1.+FULLRESYNC <runid> <offset>这个表示需要进行一次完全同步,runid需要你存起来,下次进行不完全同步时候传给我,offset表示偏移量。
2.+CONTINUE 表示会进行部分重同步
3.+ERR 则表示主服务器的版本低于2.8,只能接受SYNCcommand。
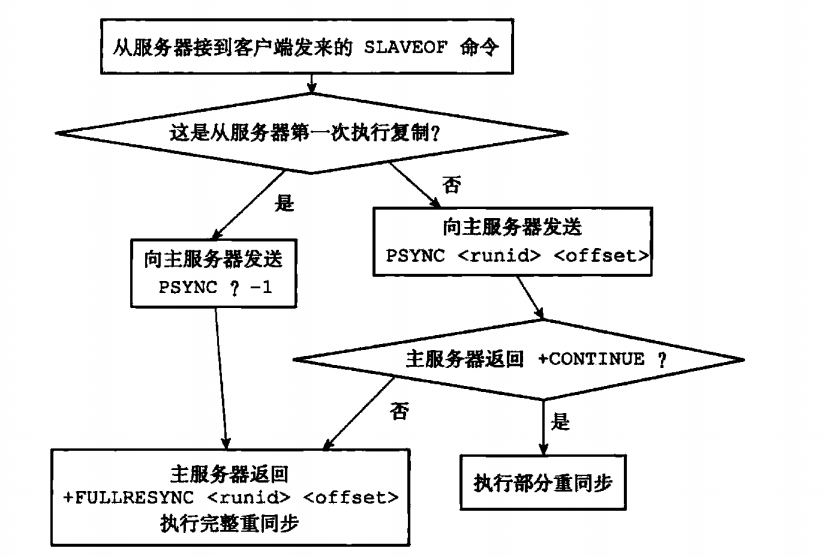
举例2.8之后的redis实现复制的详细步骤
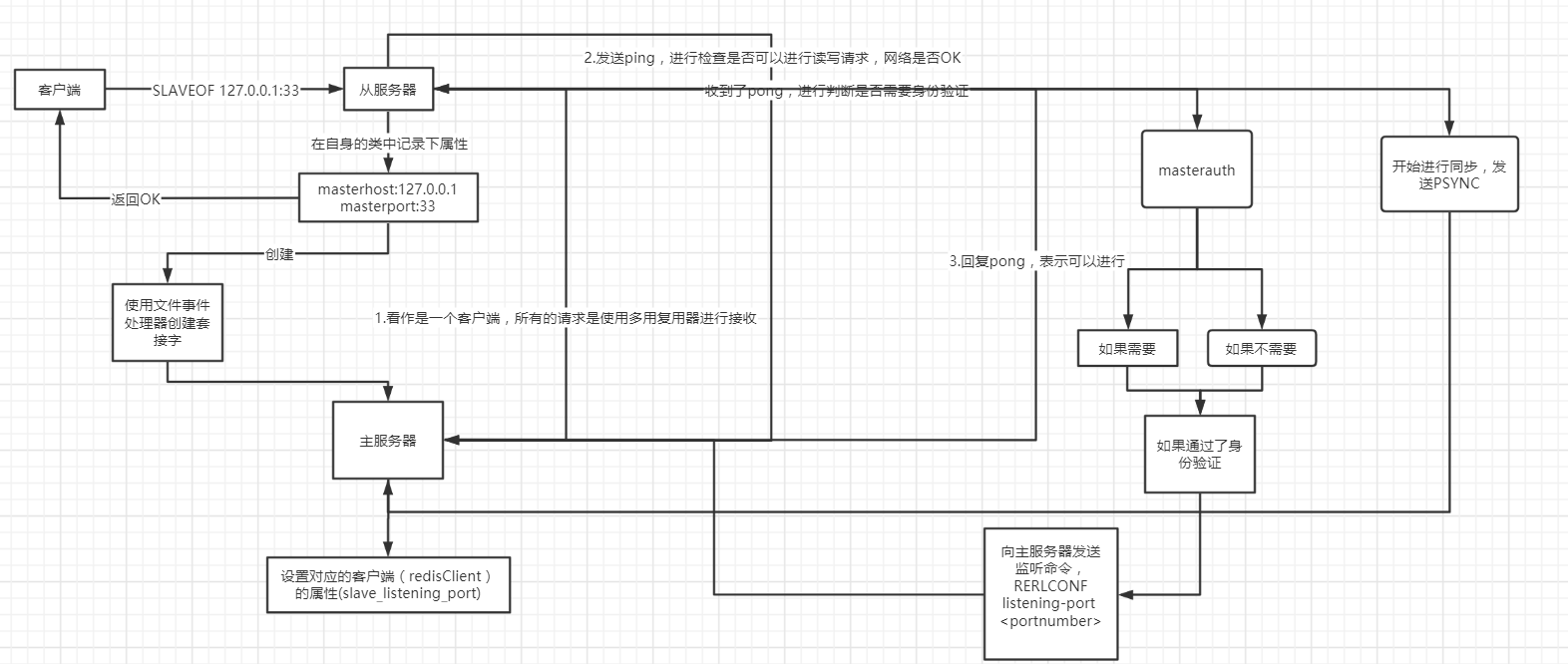
在最后会进行心跳机制的重复实现,保证检查命令丢失情况,网络情况,以及min-slave(防止不安全的情况).


 浙公网安备 33010602011771号
浙公网安备 33010602011771号