Redis设计与实现(七)对象
回忆下已经写过的数据结构:SDS,双向链表,整数数组,跳跃列表,压缩列表。
在Redis里面并没有直接使用这些,毕竟这些东西只是一个个的思想还是缺少了对业务上的定制化。例如缓存的生命。所以基于这些redis实现了一个对象系统,通过判断对象是属于which one来check 是否可以执行给定的命令。使用对象的另外一个好处就是可以针对不同的业务场景来使用多个不同的数据结构来进行优化。例如"针对订单的缓存,可以使用跳跃列表or压缩列表"
Redis也为对象实现了基于引用技术的内存回收机制,这个就很关键了,就有点像Java的容器,继承了Map,又继承了Iter。引用技术肯定需要和共享技术进行关联,也就是说可以多个数据库键对应一个对象,来节约了内存的使用。
最后Redis的对象还附带了访问时间信息,在服务器启动了maxmemory功能的情况下,空转时间长的数据会被优先删除。
Redis使用对象来完成键值对这两个对象,在set指令进行的时候,会产生一个字符串值"msg"的对象,而键对的值则是一个包含了字符串值的"helloword"对象。
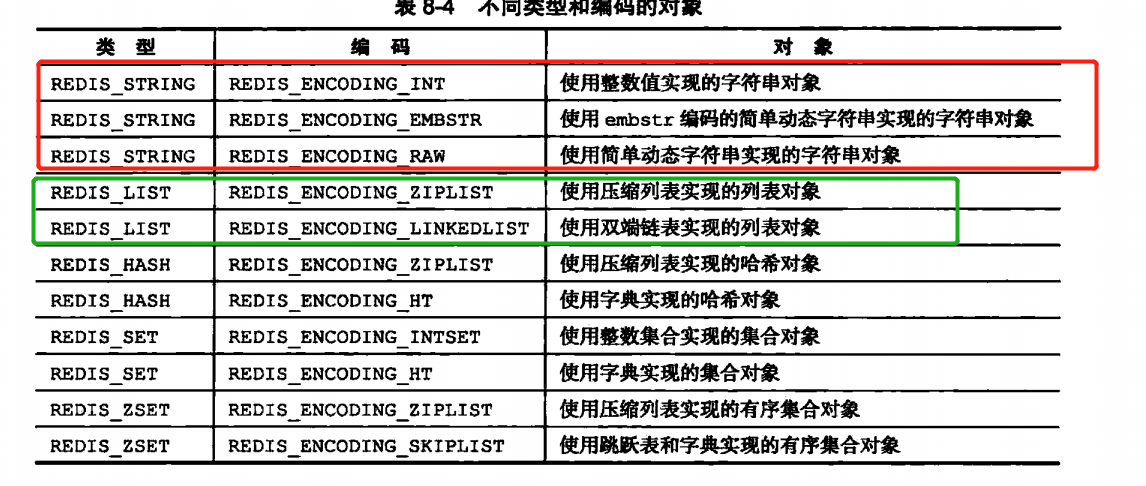
在Redis里面的对象统称为redisObeject,三个属性,type,encoding,ptr。
ptr是最关键的,是一个指针,表示的就是指向具体的哪个数据结构,例如SDS
type表示了一个具体的对象的类型,例如字符串对象,哈希对象,列表对象,集合对象,有序集合对象。这边要注意的是在redis中健的对象一般都是SDS对象,只有value的对象类型可以不也一样。

在redis里面执行type的时候返回给你的就是value 的类型,也就是从type里去get。

encoding记录了对象所使用的编码,也就是说这个对象使用了什么数据结构进行底层的实现。

但是,每个对象类型至少有两种编码。
encoding的实现就是用了可以让类型丰富起来,最大的特点就是你可以进行搭配。

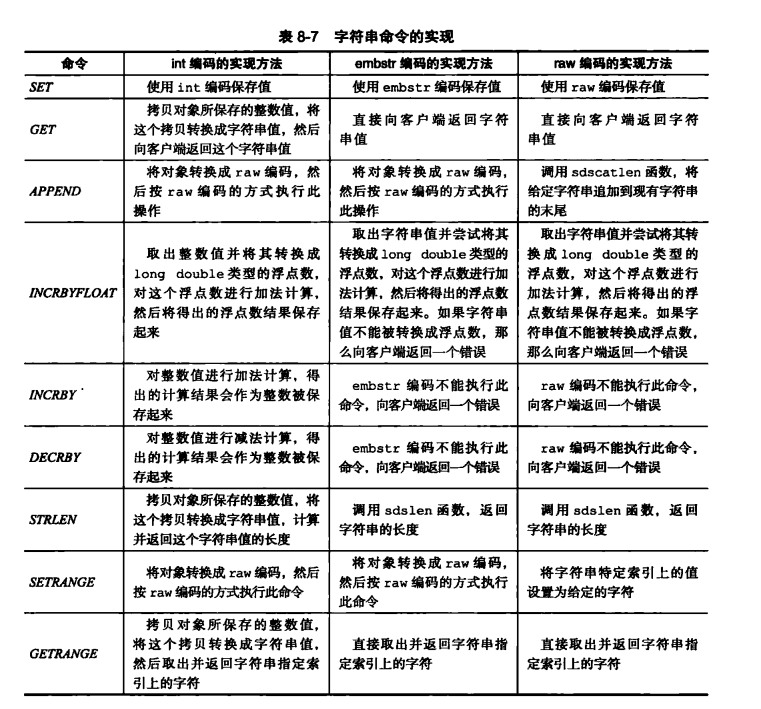
字符串对象的编码可以是raw,int or embstr。如果一个字符串对象保存的是整数值(可以使用Long来进行表示),那么就会在ptr里面把void*改成 int,并且修改字符串对象的编码为int。
如果保存的是字符串对象,并且它的大小大于32字节。那么就是raw——>SDS
小于32字节就是使用embstr,embstr和raw其实一样,止不过raw在使用的时候是分两步进行创建,redisObjetct和sdshdr结构。embstr是一步到位
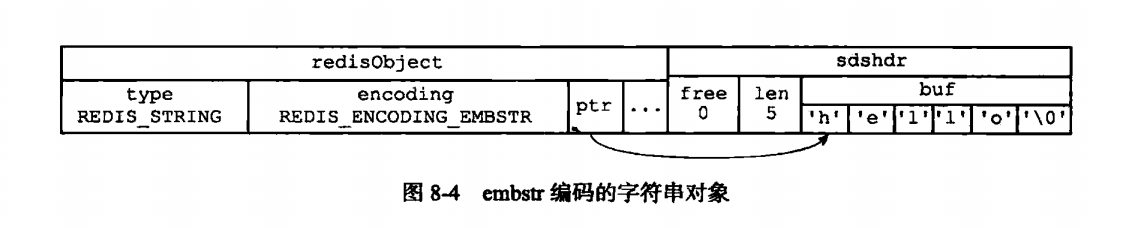

如果是浮点型的就是先转化成字符串类型。
在一定情况下是可以进行转化的,例如一个字符串对象里面本身存的是int,那么编码应该是int的,但是后续进行了追加操作,追加了一些字符串,那么就会使得int转变为raw。

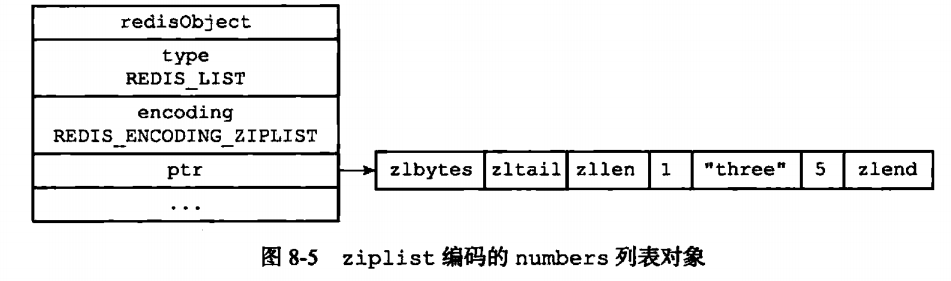
列表对象的编码可以是ziplist或者linkedlist
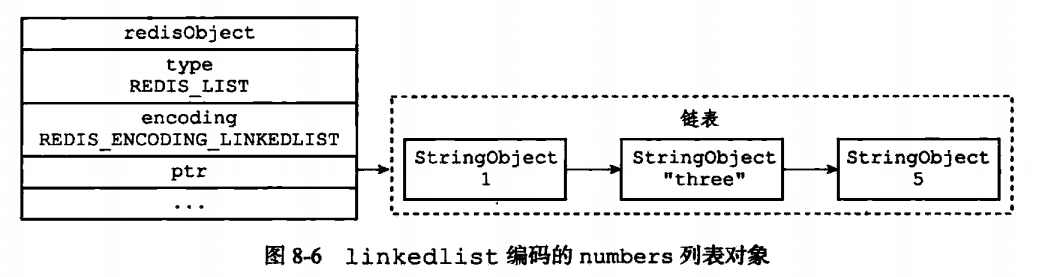
这边的区别就是使用的双向链表就会内层再嵌套一个SDS。至于编码的转化,其实也就是新生成一个对象,而不是简简单单的把encoding进行替换。
当列表对象保存的字符串元素长度大于64字节的时候,或者保持的元素大于512个的时候 都是使用的是linkedlist。其余的都是使用ziplist。当然这两个边界值是可以进行修改的。
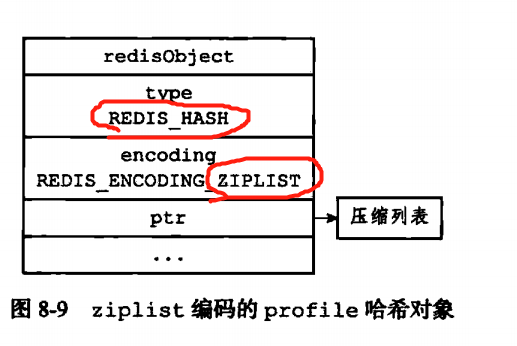
哈希对象的编码可以是ziplist也可以是hashtable
有新的键值对进入的哈希对象的时候,会先将保存了key的压缩列表节点放入尾部,然后再放入保持了value的压缩列表进入尾部。

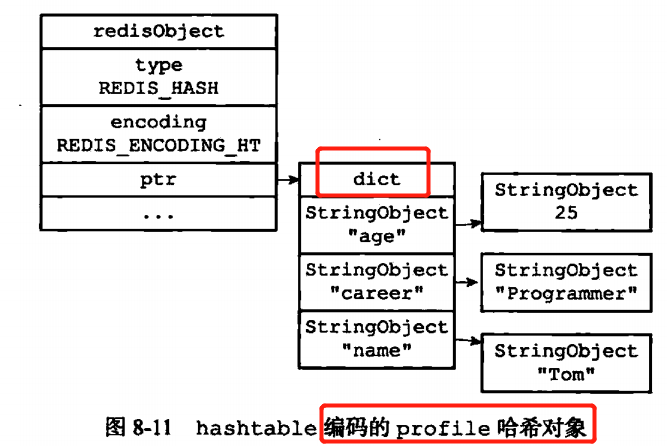
如果是使用hashtable作为底层实现的话,hashtable的底层是一个dict。
那么哈希对象的每一个键值对都是使用字典键值(也就是每一个key和value都是SDS)来进行保存的。同样的和上面一样都是使用64和512作为限制进行编码转化。
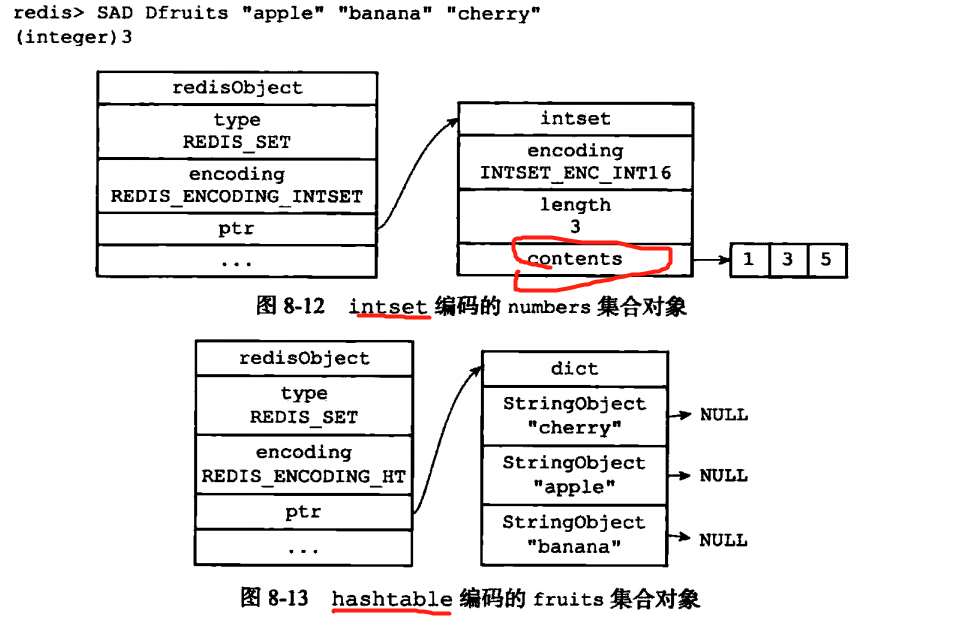
集合对象的编码是intset或者hashtable
intset就是上面说的整数队列有自带的升级功能的那个。hashtable刚刚也写过了就不会再写了。
最后一个对象是有序集合对象,这个的编码使用的是跳跃表和压缩表。有序是通过score来进行维护的。在压缩表里面score小的元素会放置在前面,在跳跃表里面也是一样。但是这边要主要的是在跳跃表的实现中,是还有一个dict作为附送的,保持了score和成员的映射。反过来也就是说

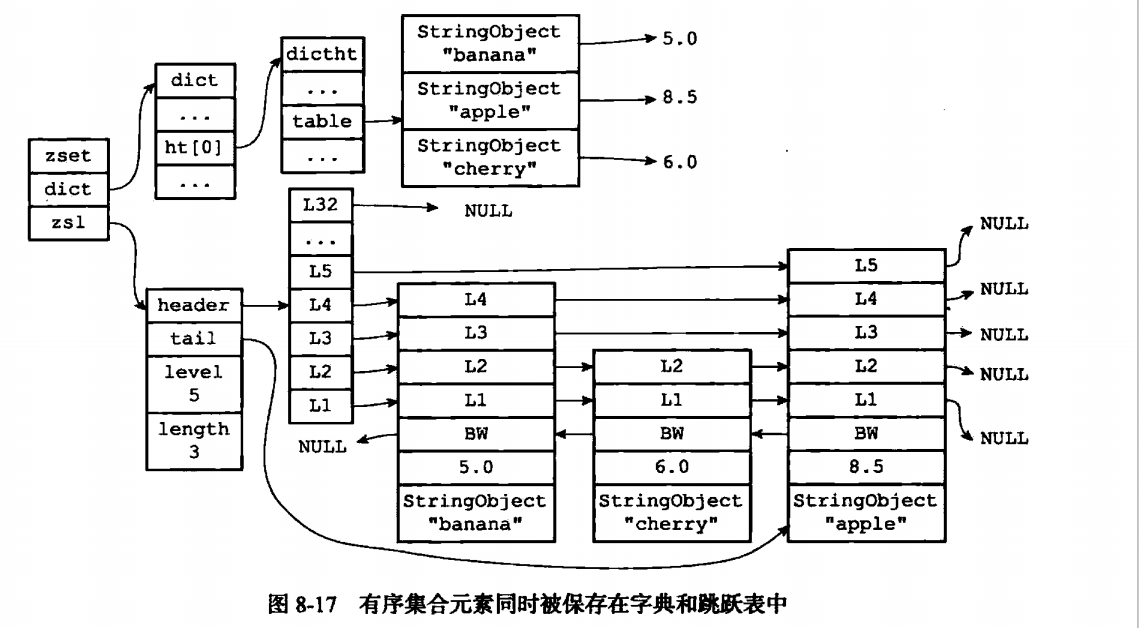
总结起来:
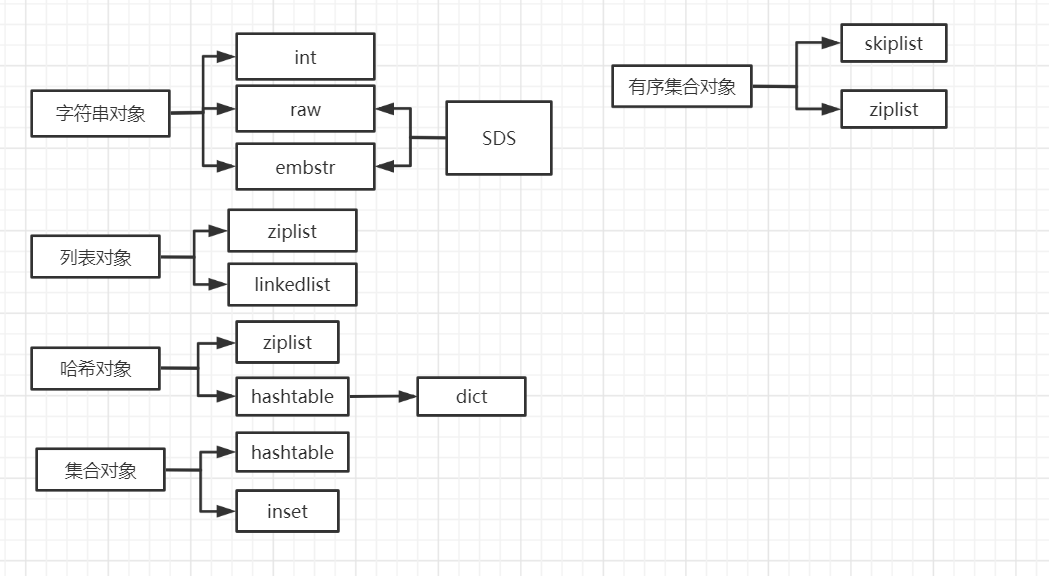
应该是这样的一张图,然后小的分支的模样,心里中要有数,然后64,512两个边界值。
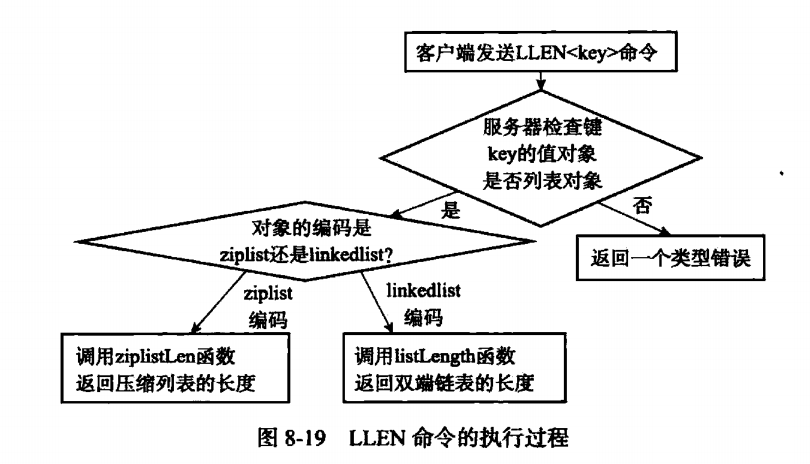
多态的执行流程:
最重要的内存回收机制,由于C里面是不包含这个的,所有redis自己实现了一个引用技术实现的内存回收机制。
每个对象(redisObject)是通过refcount属性记录的,refcount是一个int形的数据。
有以下几个规则进行维护:
1.创建这个新对象的时候这个refcount被默认为1
2.对象被一个程序进行引用的时候refcount会+1
3.当对象不被某个程序引用的时候,refcount会进行-1
4.如果这个对象的引用计数变成了0,就会被自动清除--->有函数可以进行手动的reset
对象的生命周期可以看作:创建对象,使用对象,销毁对象。
同样的有了这个引用机制了可以进行对象的共享,例如A加入了100这个元素,B也要加入100这个元素,两种做法要么给B也新建一个100,然加入,要么和A一起贡献这个元素。
这边就是是为了极致的节约内存,如果B需要修改对象的时候,再给B新建出需要的对象。而且Redis在开机的时候,会自动创建出0~9999这一个万个DSD对象(type:int)

要么总结下RedisObject的属性
type:用来记录是哪一种对象
encoding:用来记录底层的实现的类型
ptr:底层实现的引用
refcount:引用的计数器
lru:最后一次被访问的时间


 浙公网安备 33010602011771号
浙公网安备 33010602011771号