CRUD工程师——索引
强调:一旦为表创建了索引,以后的查询最好先查索引,再根据索引定位的结果去找数据
1、在表中有大量数据的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
根据书中写的,索引是有一个专门的索引页,而索引是为了减少IO,加速查询的。也就是说最好是有一个目录一样的书,然后就这样,B+树天然适合了MySQL索引。
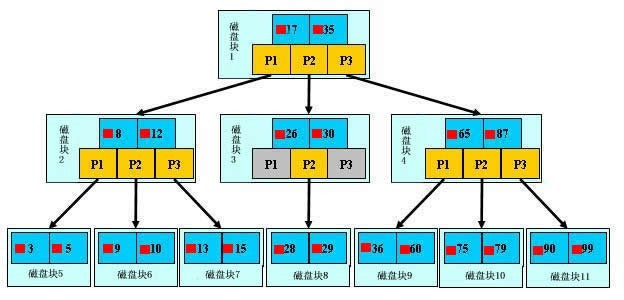
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。除了叶子节点,其他的树根啊树枝啊保存的就是数据的索引,他们是为你建立这种数据之间的关系而存在的。
注意点:
聚焦索引和辅助索引
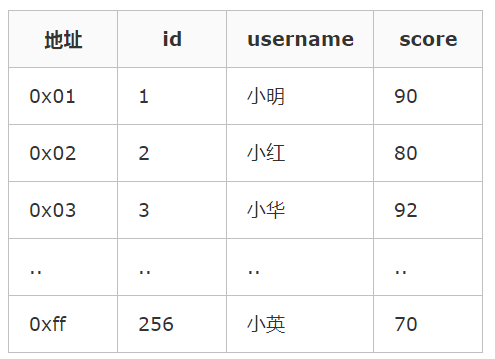
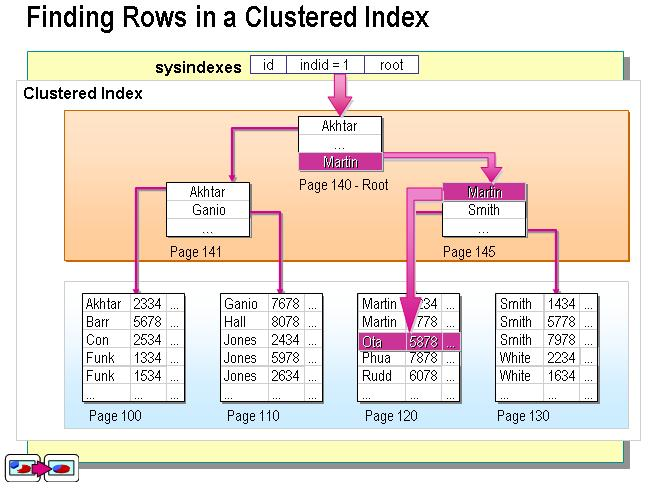
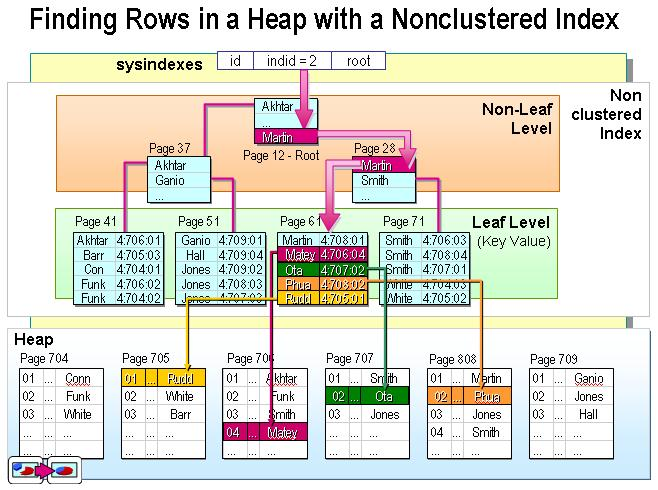
二级索引:叶子节点中存储主键值,每次查找数据时,根据索引找到叶子节点中的主键值,根据主键值再到聚簇索引中得到完整的一行记录。
问题:
1.相比于叶子节点中存储行指针,二级索引存储主键值会占用更多的空间,那为什么要这样设计呢?
InnoDB在移动行时,无需维护二级索引,因为叶子节点中存储的是主键值,而不是指针。
2.那么InnoDB有了聚簇索引,为什么还要有二级索引呢?
聚簇索引的叶子节点存储了一行完整的数据,而二级索引只存储了主键值,相比于聚簇索引,占用的空间要少。当我们需要为表建立多个索引时,如果都是聚簇索引,那将占用大量内存空间,所以InnoDB中主键所建立的是聚簇索引,而唯一索引、普通索引、前缀索引等都是二级索引。
3.为什么一般情况下,我们建表的时候都会使用一个自增的id来作为我们的主键?
InnoDB中表中的数据是直接存储在主键聚簇索引的叶子节点中的,每插入一条记录,其实都是增加一个叶子节点,如果主键是顺序的,只需要把新增的一条记录存储在上一条记录的后面,当页达到最大填充因子的时候,下一跳记录就会写入新的页中,这种情况下,主键页就会近似于被顺序的记录填满。
若表的主键不是顺序的id,而是无规律数据,比如字符串,InnoDB无法加单的把一行记录插入到索引的最后,而是需要找一个合适的位置(已有数据的中间位置),甚至产生大量的页分裂并且移动大量数据,在寻找合适位置进行插入时,目标页可能不在内存中,这就导致了大量的随机IO操作,影响插入效率。除此之外,大量的页分裂会导致大量的内存碎片。
非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,此如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。
两者注意点
- 使用聚集索引的查询效率要比非聚集索引的效率要高,但是如果需要频繁去改变聚集索引的值,写入性能并不高,因为需要移动对应数据的物理位置。
- 非聚集索引在查询的时候可以的话就避免二次查询,这样性能会大幅提升。
不是所有的表都适合建立索引,只有数据量大表才适合建立索引,且建立在选择性高的列上面性能会更好。
索引的优缺点:
- 索引大大减小了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机IO变成顺序IO
- 索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组。在MySQL5.1和更新的版本中,InnoDB可以在服务器端过滤掉行后就释放锁,但在早期的MySQL版本中,InnoDB直到事务提交时才会解锁。对不需要的元组的加锁,会增加锁的开销,降低并发性。 InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组数。但是只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即索引达不到过滤的目的),MySQL服务器只能对InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了。如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。
缺点
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效;
参考博客:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号