CRUD工程师---InnoDB存储引擎2
上次说到InnoDB关键特性
插入缓冲、两次写、自适应hash索引、异步IO、刷新相邻页

Insert Buffer插入缓冲
是InnoDB存储引擎关键特性中的一个重点,也是经常被问到的问题之一。InnoDB缓冲池中有Insert Buffer信息,但是也和数据页一样,也是物理页的一个组成部分。
在InnoDB存储引擎中,主键是行的唯一标识符。通常应用程序中行记录是按照主键递增的顺序进行插入的,也因此Primary Key一般是顺序的,不需要磁盘的随机读取。但是当主键是UUID这种类型的时候,就会和辅助索引一样,进行随机插入(人话:主键是自增类型,但插入的值是指定值,不是Null值,就会造成插入非连续的情况)。
但是表中不可能只有一个索引(不可能只使用ID进行查询),如果查询的索引是一个非唯一的值,就会产生一个非聚集的而且不是唯一的索引。
CREATE TABLE T(
A INT AUTO_INCREMENT,
B VARCHAR(30),
PRIMARY KEY(A),
KEY(B)
)1
CREATE TABLE T(2
A INT AUTO_INCREMENT,3
B VARCHAR(30),4
PRIMARY KEY(A),5
KEY(B)6
)在进行插入操作的时候,数据页的存在还是按照主键进行顺序排放的,但是对于非聚集索引叶子节点的插入不再是按照顺序了。这时候去查询B,就会发现InnoDB是按照一个离散的方式进行查询。
对于非聚集索引的插入或更新操作,不是每一次都插入索引页中,而是先判断插入的非聚集索引是否在缓存池中,若在则直接插入,若不在就先放到一个Insert Buffer对象中,然后再按照一定的频率和情况进行Insert Buffer和辅助索引页子节点merge合并。
当然需要满足两个条件:
1.索引是辅助索引
2.索引不是唯一的
Change Buffer:可以看作是Insert Buffer的升级
从1.0.X版本后引入Change Buffer,适用的对象依然是非唯一的辅助索引。对一条记录进行UPDATE操作可能分为两个过程:
1.将记录记录为已删除
2.真正地记录删除
Insert Buffer的内部实现:
Insert Buffer的使用场景:非唯一的聚集索引的情况下的插入操作
Insert Buffer的数据结构是一个B+树,在Mysql4.1之后的版本中只有一颗Insert Buffer B+树,复杂对所有表的辅助索引进行Insert Buffer操作。这棵树会共享表空间中(ibdatal)中,因此,试图通过对独立表空间ibd文件恢复数据的时候,会导致CHECK_TABLE失败,这是因为表的辅助索引中的数据可能还在Insert Buffer这个对象中。
Insert Buffer是一颗B+树,叶节点和非叶节点组成,非叶节点存在查询的search key(键值)
构造:
| space | marker | offset |
space用于表示待插入记录所在表的表空间ID,marker用来兼容老版本的Insert Buffer,offset表示页所在的偏移量
当一个辅助页需要插入的space和offset时,这个页不在缓存池中那么InnoDB会构造一个search key,接下来查询Insert Buffer这颗B+树,然后再将这条记录插入到Insert Buffer B+树的叶子节点中
两次写
doublewrite带给引擎数据页的可靠性,流程图: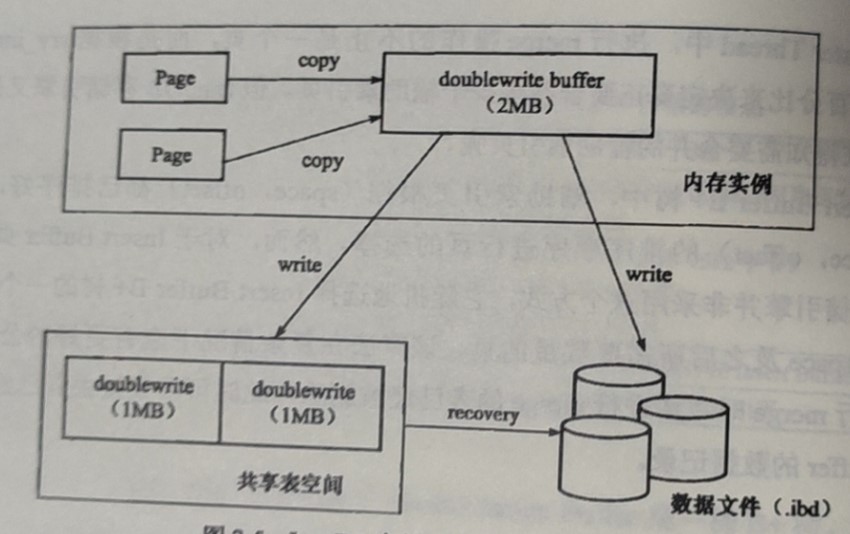
在写入失效时,先通过页的副本来还原该页,再进行重做。
doublewrite由两个部分组成,内存中的doublewrite buffer,大小为2MB。另外一个部分为物理磁盘中恭喜表的空间中的128个页,即2个区,也为2mb。在对缓冲池的脏页进行刷新的时候,不是直接写在磁盘中,先通过memcpy函数将脏页复制到doublewrite buffer中,然后再通过doublewrite buffer分两次,每次都1MB顺序地写入共享表的磁盘空间中。然后调用fsync函数,同步磁盘,避免了缓冲带来的问题。因为doublewrite页是连续的,因此这个过程是顺序写。完成doublewrite页写入后,再降doublewrite buffer中的页写入表的各个空间文件中。
如果在写入磁盘的过程中出现了奔溃就可以通过共享表中的doublewrite中找到页的副本。
自适应哈希索引
哈希是一种非常快的查找方法,一般情况下这种查找的时间复杂度为O(1),一次就可以完成定位数据,而B+树的查找次数,取决于B+树的高度,一般生产环境中B+树的高度为3~4层,所以需要3~4次的查询。
InnoDB会监控对表上各索引页的查询,如果观察到建立哈希索引可以带来速度提升,则建立哈希索引(看到这里肯定有一个疑问,怎么观察)
AHI(自适应哈希索引)是通过缓冲池的B+树页构造而来的,因此建立的速度很快,而且不需要对整张表构造哈希索引,InnoDB会根据访问的频率和模式来自动的为某些热点页建立哈希索引。
AHI有个要求,即对这个页的连续访问模式必须是一样的,例如(a,b)这要的联合索引查询。(WHERE a === X and b===X)
访问模式一样指的是每一次都是这种样子,而且有要求:以该模式访问了100次,页通过该模式访问了N次,其中N=页中记录*1/16
这边有个特点就是AHI只能搜索等值寻找。
异步IO
为了调高磁盘操作性能,当前的数据库系统都是采用异步IO的方式来进行磁盘处理操作,InnoDB也是。
AIO(异步IO)对应的都是Sync IO(需要等待操作结束才进行下一次操作)
AIO另外一个优势就是能进行IO Merge操作,对多个IO操作进行合并处理。
在InnoDB中 read ahead方式的读取和脏页的刷新都是由AIO完成的
刷新邻接页
InnoDB会检测该页所在区的所有页,如果是脏页就一起进行刷新操作
smartcat.994

 浙公网安备 33010602011771号
浙公网安备 33010602011771号