leetcode刷题笔记,无重复字符的最长子串题解
无重复字符的最长子串题目
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
无重复字符的最长子串题目题解
提交时的代码↓
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
str_list = []
str_list2 = []
len_max = 0
str_len = 0
for i in s:
str_list.append(i) # 将字符串分割为列表,存储在str_list
for i in range(0, len(str_list)):
for n in range(0, len(str_list)-i):
if str_list[i + n] not in str_list2:
str_list2.append(str_list[i + n]) # 将str_list中的元素放进str_list2中
str_len = len(str_list2)
else:
len_max = max(len_max, str_len)
str_len = 0
str_list2.clear() # 如果重复,清空str_list2
break
return max(len_max, str_len)
结果

执行用时我记得超过了5.01%的人,内存消耗是30%的人😞
去评论区和题解区取波经
无重复字符的最长子串题目优化
基本上用的都是滑动窗口的思路(说明我的思路应该没有问题,可能在其他地方还得优化)
滑动窗口
以"abcabcbb"为例,窗口从"abcabcbb"开始,慢慢往右拉,当拉到"abcabcbb"时,"abc"就是不包含重复字符的最长字串
然后再从"b"开始往右拉,当拉到"abcabcbb"时,"bca"就是不包含重复字符的最长字串
。。。
最后从这些最长字串中找出最长的长度
去掉将字符串分割为列表这一步
遍历字符串可以直接用s[i],没有必要用for循环对"s"作遍历,再添加到list中,有点多此一举
用while循环替代"n"的for循环
用while循环替代"n"的for循环,并且将代码中多余的部分优化,比如ls = len(s)、原来的return max(len_max, str_len)修改为return len_max,减少重复计算
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
str_list2 = []
len_max, str_len = 0, 0
ls = len(s)
n = 0
for i in range(0, ls):
while n < ls and s[n] not in str_list2:
str_list2.append(s[n])
str_len = len(str_list2)
n += 1
len_max = max(len_max, str_len)
str_list2.clear()
n = i
return len_max
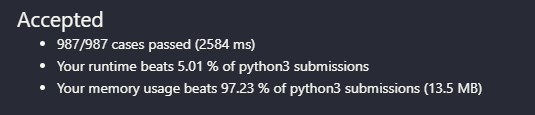
提交结果:执行用时从2720ms提升到2584ms(虽然还是5.01%),内存消耗13.8MB减少到13.5MB(97.23%感人)
用hashmap(转自该题评论区中CaptainTec的解法)
还学到了一个新的函数enumerate()
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
k, res, c_dict = -1, 0, {}
for i, c in enumerate(s):
if c in c_dict and c_dict[c] > k: # 字符c在字典中 且 上次出现的下标大于当前长度的起始下标
k = c_dict[c]
c_dict[c] = i
else:
c_dict[c] = i
res = max(res, i-k)
return res
不得不说,这里的c_dict[c] > k用的真好,执行用时只有68ms,超过了87.89%的用户

 浙公网安备 33010602011771号
浙公网安备 33010602011771号