记录MFC在UNICODE字符集下读取中ANSI英文混合文件英文字符为单数汉字出现乱码问题
惭愧,做了3年多 C++ 了,虽说半路出家,之前也做过 Linux 一年多,但是 MFC 也做了一年多了,由于一直维护公司的老项目,也没有做过新东西。
最近心血来潮,在网上找了些学习视频,复习下 MFC 控件的使用,熟悉下 MFC 的 API,毕竟是吃饭的家伙,废话不多说,来干货。
最近在仿写一个记事本软件,初具基本功能,但遇到了一个比较蹩脚的问题,MFC 在 UNICODE 字符集下在读取 ANSI 编码的文本文件时,全中文没问题,全英文也没问题,但是中英文混合时,当英文个数为奇数个时,英文后面的汉字就会编程乱码。
原因是我想的太简单了,觉得读取 ANSI 编码的文本文件,就是读取多字节字符串,也就有了如下代码:
代码中的形参只是定义了一个 CFile 对象并以只读方式打开,个人习惯,如果解释就要解释的明明白白,所以给这两句代码也复制过来了。
CFile file;
file.Open(szFile, CFile::modeRead);
1 void CNotepadDlg::ReadAnsi(CFile& file) 2 { 3 file.Seek(0, CFile::begin); 4 char buff[1024]; 5 UINT nRet = 0; 6 CString str; 7 8 while (nRet = file.Read(buff, sizeof(buff - 1))) 9 { 10 buff[nRet] = '\0'; 11 str += buff; 12 } 13 14 SetDlgItemText(IDC_EDIT_TEXT, str); 15 16 }
这只是按照单字节读取,当然显示也就存在问题。
这是用微软记事本打开的 ANSI 编码的文本文档。
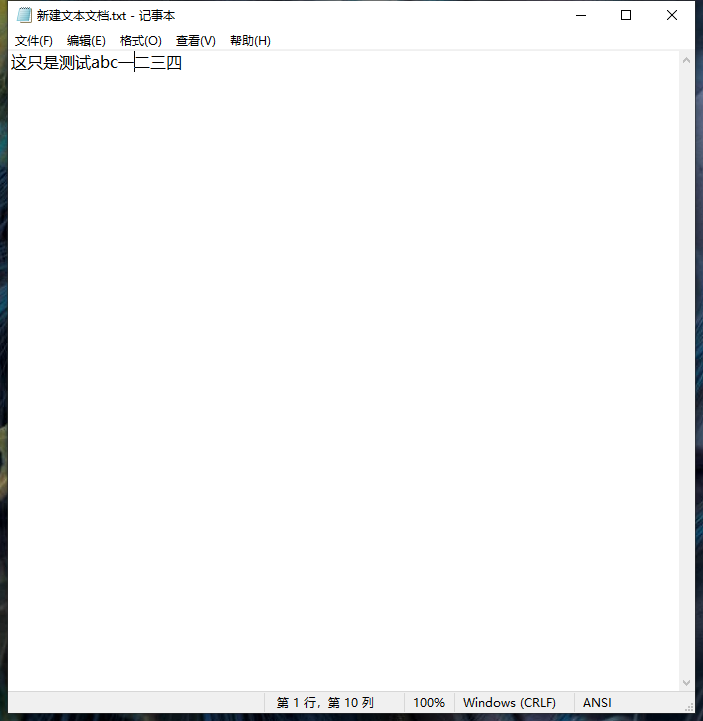
这是我仿写记事本打开的文本文档
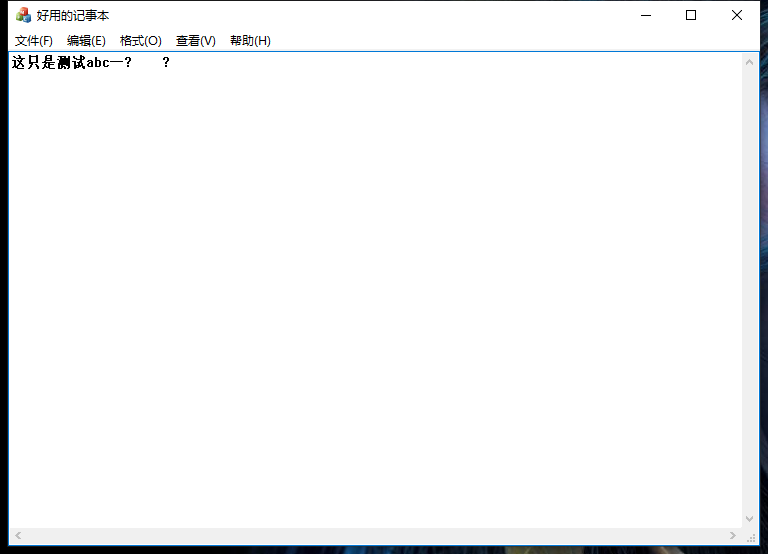
结果很明显,不对。
网上也找了很多处理办法,A2T,bstr_t,_tsetlocale(LC_ALL, _T("chs")); 这几个方法都试了,可能我水平不济,确实没弄明白,最后还是用最原始的 MultiByteToWideChar() 解决了问题。当然,代码还存在许多问题,待优化。
1 void CMFC194Dlg::ReadAnsi(CFile& file) 2 { 3 file.Seek(0, CFile::begin); 4 // TODO: 在此处添加实现代码. 5 char buff[1024]; 6 UINT nRet = 0; 7 CString str; 8 9 LONGLONG nLen = file.GetLength(); 10 char* p = new char[nLen + 1]; 11 nLen = file.Read(p, nLen); 12 p[nLen] = '\0'; 13 TCHAR* pText = new TCHAR[nLen + 2]; 14 memset(pText,0 , nLen + 2); 15 16 nLen = MultiByteToWideChar(CP_ACP, NULL, p, -1, pText, nLen + 2); 17 18 SetDlgItemText(IDC_EDIT_TEXT, pText); 19 20 delete[]p; 21 delete[]pText; 22 }
读取结果:
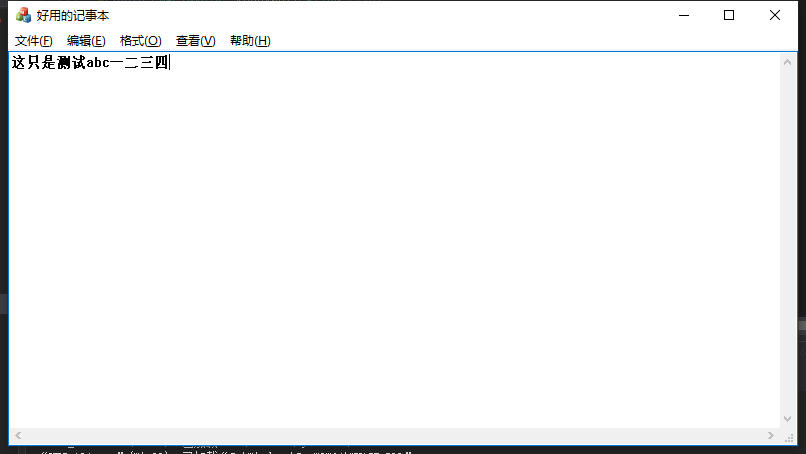
处理这个问题的灵魂是这两句代码:
TCHAR* pText = new TCHAR[nLen + 2];
memset(pText,0 , nLen + 2);
因为 ANSI 编码中英文字母占一个字节,中文汉字占两个字节,所以定义 pText 长度不能是 多字节长度 / 2 + 2,这会导致空间不足,使 MultiByteToWideChar() 返回 0,用 GetLastError() 可知返回122。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号