grep 、sed、awk被称为linux中的"三剑客"。
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
awk 更适合格式化文本,对文本进行较复杂格式处理
AWK是一种优良的文本处理工具
awk是linux中处理文本的强大工具,或者说是一种专门处理字符串的语言,它有自己的编码格式。awk的强大之处还在于能生成强大的格式化报告
使用方法 : awk '{pattern + action}' {filenames}

尽管操作可能会很复杂,但语法总是这样,programe 又分为 pattern 和 action ,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。
案例分析
数据链接 https://www.cnblogs.com/SliverLee/protected/p/11868443.html 密码 :123456
现有数据如下,求出Reason=1000时,Lefts字段值汇总。
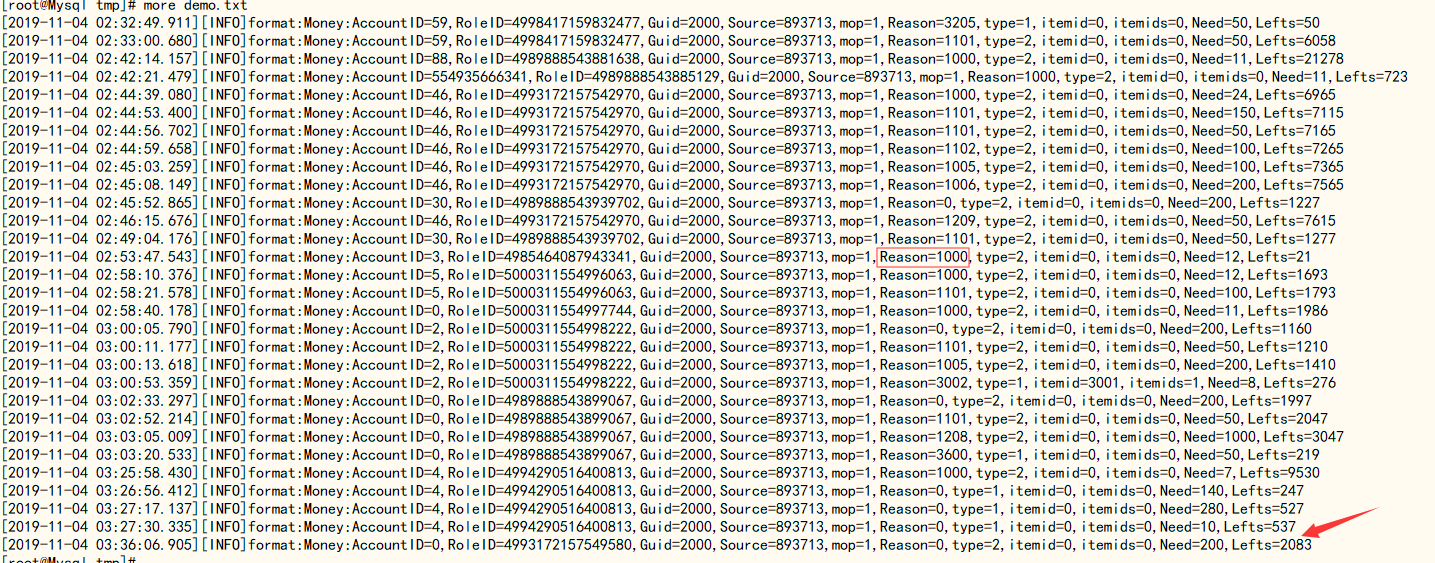
1、从所有数据中,利用grep先过滤出 Reason=1000部分。
[root@localhost tmp]# more demotest.txt | grep Reason=1000

2、接下来就是awk的功能了
AWK常用参数
ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 $0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。3、print和printf


默认空格分隔符

修改分隔符为 “ - ”,对比默认空格,很明显发现不同。

如根据多个分隔符进行分割呢?可以两次awk,但是我们可以一次告诉awk我们所有的分隔符,如-和|这两个,用[]包起来,想根据更多也可以继续加。

5、计算
根据前面的几个内容,我离最终的目的越来越近了,首先我先获取到Lefts这个列,分隔符为多个“-:,=”,

当Lefts值大于2000时,才输出

BEGIN与END
特殊模式 BEGIN 用于匹配第一个输入文件的第一行之前的位置, END 则用于匹配处理过的最后一个文件的最后一行之后的位置。这个程序使用 BEGIN 来输出一个标题:
下面求和
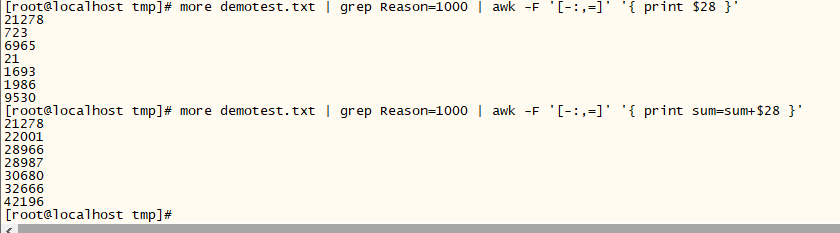
结合END,计算如下
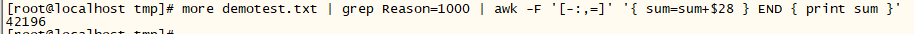
最后结合之前所有的知识点总结一下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号