FW: 推荐系统 -框架
推荐系统本质是对用户不同行为,从海量物料中选取用户可能感兴趣的物料进行展示,通过策略、算法、规则等途径引导用户产生点击或其他交互行为,那从用户打开特定app起,到展示出相关内容到底经历了何种操作,海量的物料是怎样被筛选出来?如果业务越做越大,用户和物料数据积累越来越多,仅靠规则不能进一步提升用户对物料感兴趣程度,那么该如何升级成为推荐系统为用户带来更好的浏览体验?本系列文章将展示如何从0搭建一套较为完整的推荐系统,进而一窥其内部原理。
高屋建瓴,各公司业务系统和场景各有不同,系统有繁有简,技术栈和使用细节千差万别,要搭建推荐系统,我们先把系统模块和数据流梳理清,大多都具有如下模块和流程。
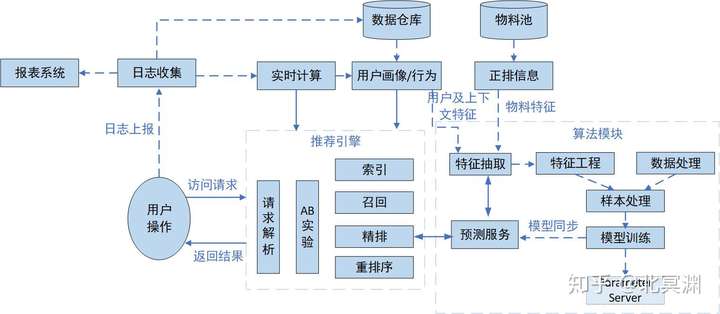
如图所示,数据流实线为在线流程,虚线为离线流程。一般在线流程指用户实时访问系统用于计算及使用的服务,离线流程指跟用户请求无直接关系可对数据单独统计计算的过程。
物料数据
首先要有被推荐的物料数据,而且必须要多,非常多,几十上百个的也就可以先退出 了,与其花大量精力搭建推荐系统,还不如多开垦业务场景,丰富内容,一把好枪还需要充足的弹药供应才能发挥威力不是。一般来说可推荐物料需要数万到数千万甚至上亿,每个物料具有唯一id,除此之外还应有其自身的各类基础信息,各家业务不同信息也各不相同,例如类型(文本、视频、图片)、类别(新闻、娱乐、体育)、标签(宝马,奥迪,东坡肘子.....)、时效、地域等等。物料数量规模庞大,再加上自身各类信息,那需要存储的物料池也会成倍增加,对不同规模的数据量就得盘一盘该如何存储,这里先简单抽象成一个物料池。
用户数据
有了物料数据还需要有用户数据,一般是系统日志通过埋点记录用户各类行为,通过日志收集系统计算处理,将有效的用户行为数据结构化并落到存储空间中,一般用数据仓库进行管理,便于后续分析、计算。用户行为一般是用户的浏览、点击、播放等普通行为以及点赞、评论、转发、下单等深层行为,结合访问时获取到的用户设备、时间、地域等,加上各行为打上时间戳,日积月累就能构造出一个用户的多维度行为轨迹和画像。
用户画像
用户数据结构化落仓后就方便后续对用户行为的统计分析了,结合用户时序信息,可以计算出所需维度的用户画像,例如用户的兴趣点标签,偏好什么内容,习惯在什么时段访问,常用的地理位置信息,通过浏览内容判断用户年龄段和性别等,深入些的后续还可进行用户聚类、分群等分析处理。
实时计算
这里还需要一个实时计算的环节,用于通过实时收集日志并解析物料与用户的实时统计信息,例如物料的曝光数、点击数、评论数等,可以丰富物料的基础信息;对用户来说可以收集用户实时曝光、点击及其他行为的实时数据,用于后续算法特征处理或在线规则处理。
算法模块
物料和用户数据齐备,就轮到推荐算法上场了,当然这里也是一个大模块,上面的数据虽有,但此数据非彼数据,算法需要用的还需要转化为特征和样本数据,绝大部分算法模型还是很挑食的,喂进去的数据必须要经过处理,否则再好的模型面对噪声数据也不会有好的结果。数据处理好,选好模型就可以训练了,结果不错皆大欢喜,效果不好不能直接把锅甩给模型不给力,还要分析数据、调整参数,经过几个来回后得到一个还不错的模型,就可以准备给用户使用啦。如果数据规模庞大还需要分布式训练。
推荐引擎
如果业务要求实时性不强,用户和数据量都不是很庞大,那么在离线按小时或天的频次直接计算各个用户可能的偏好物料即可,无论通过用户画像偏好匹配物料,还是使用训练好的模型进行直接预测排序,只要能满足业务要求就是一套好系统。但很多场景用户访问要求实时性高,业务特性复杂,就需要一套专门的推荐引擎将推荐系统及依赖的各模块整合起来,包括构建倒排索引、召回、排序、rerank及其他依赖模块,便于灵活开发与部署。另外评估推荐系统效果也需要科学的分桶实验系统也需要在推荐引擎模块中实现。
数据报表
截止目前一套完整的数据流已经可以跑通了,也可以为用户推荐计算好的结果,但还需要一个看起来不起眼却非常重要的模块——报表数据,用来展示推荐系统整体效果,包括AB实验效果,分标签、召回等维度效果等,用于后续迭代优化时提供数据支撑。
至此,推荐系统的蓝图已构思完毕,数据可以在纸面上完全流动起来形成闭环,不断积累数据,不断迭代算法策略,不断提升效果指标,不断产生业务收益,不断提升程序员的工资,想想是不是很开心?后面我们就把上述的这些坑一块一块填起来,完整实现一套推荐系统。
推荐系统自诞生之日起就是为解决海量物料如何高效分发给海量用户,一套高效的算法流程就是推荐系统的核心。如今火热的各类机器学习、深度学习、强化学习等都可以在推荐系统中大显身手,推荐也是AI在工业界最广泛的落地场景之一。推荐算法在推荐系统中的位置如图1所示,主要是通过离线或在线拿到特征及样本数据训练模型,将训练好的模型同步给召回或排序的预测服务,推荐引擎实时调用预测结果供召回及排序使用。
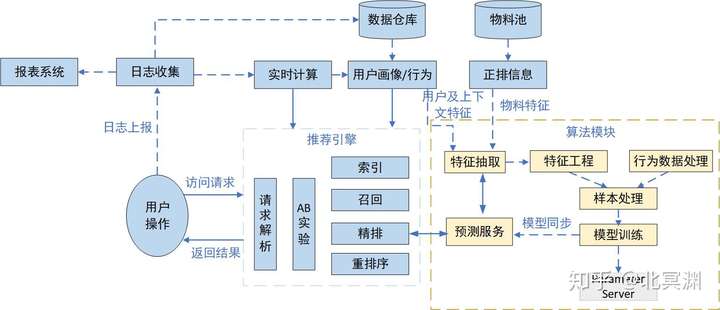 推荐算法在推荐系统中地位
推荐算法在推荐系统中地位
如果更宽泛意义上,推荐内容的质量、类别、理解等都可通过各自AI算法计算,节省大量人工成本,通过NLP、音频、视频、图像理解等领域内的先进算法,丰富物料的正排信息进入资源池,如物料质量、物料类别、关键词提取,图像视频理解、音频转文本、物料属性的embedding向量等等。
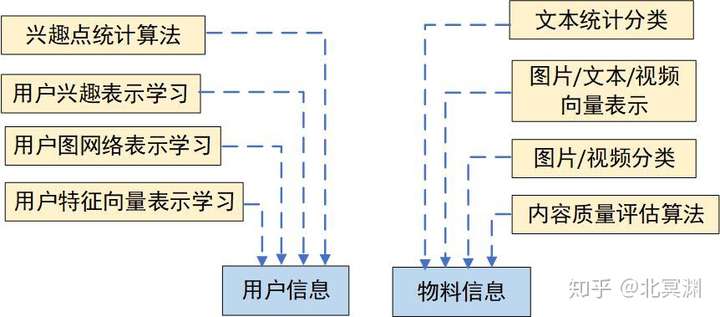 各领域算法对用户与物料信息的丰富
各领域算法对用户与物料信息的丰富
推荐效果主要以提升ctr为目标,但转化率、完播率、停留时长等均可作为辅助指标,可以说只要能够抽象出问题并描述出要最优化的损失函数,有较丰富的特征及样本,那就一定能够用算法来解决问题。这里我们先以精排阶段的算法为例说明如何构建起完整的排序算法通路。
特征库/服务
算法需要数据,数据需要特征,特征是模型训练数据中最重要的部分,各类算法的本质也是根据现有样本分布拟合出一个最接近真实情况的概率分布函数,需要拟合的参数就是各个特征,通过这个函数即可获取特定用户或物料的特征下用户对物料的感兴趣程度(点击的概率),因此特征工程也是推荐算法工程师的必备技能,人工智能圈广为人知的调侃“人工智能靠人工”,在推荐领域的重要体现就在于通过分析数据来获取重要特征。
推荐系统连接的是人与物,特别是独特业务场景下的人与物,那么一定也会有独特的物料属性特征与用户行为特征,针对深入理解业务的基础上构造好的特征,那推荐算法出来的结果也就成功了一半以上。从人和物的角度,特征也分为物料特征、用户特征及上下文特征,上下文也可算作用户特征的一种。用户特征一般通过明确记录或统计挖掘得到,如用户的地理位置、访问时段、使用设备、性别年龄(可能通过填写资料获取)一般在访问时即可拿到;挖掘特征通过历史用户的操作行为,统计用户的画像偏好。物料特征一般是物料自身属性及其统计数据,例如类别、关键词、主题等固有属性,以及历史一段时间窗口内的效果统计如曝光、点击、点赞、转发等。从直观含义看可分为类别特征和数值型特征,对不同特征也要多种特征工程处理方式,这里推荐一份slide讲解特征工程,很香!原始出处要FQ,为方便大家直接搬运了。
https://pan.baidu.com/s/1i4EVDVR?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0&traceid=
特征工程是一项实践性很强的工作,基本的技术方法就那么几种,但真正用来调好模型的特征工程方法一般网上也很少,原因之一就在于是跟自己公司具体业务挂钩的,不具有普遍性,即使放出来也只适用于自己公司业务,无法放之四海而皆准,可以看下各大厂主要产品线的推荐系统特征工程是如何做的。
腾讯技术工程:浅谈微视推荐系统中的特征工程zhuanlan.zhihu.com
这里用户特征,包括上下文特征,可以根据用户离线的行为日志统计,类似用户画像,假设此时用户属性类别、各维度偏好、对各行为的统计量等都已用特征工程处理完毕并结构化存入hive表,同理对物料在资源池获取属性类别特征,通过客户端日志获取物料各维度统计类信息,保存至hive表,再通过一个定时任务将hive内的特征数据整合,这样将离线计算的用户及物料维度特征保存至hive表,同时更新至redis供线上实时获取。
 特征构建
特征构建
有了特征就能方便的构建出模型训练样本数据,这时要针对推荐效果指标来构建样本,对于ctr指标来说一般是分类问题,使用用户对物料是否点击作为label,对于视频类播放时长指标一般可作为回归问题,用户对物料的播放时长作为样本y值,这里以ctr作为评价指标,正样本为用户点击物料,负样本为用户曝光未点击物料。
训练数据
说到算法并无太多神秘之处,如果了解基础的机器学习原理,各类算法只是针对大量样本数据的一个拟合过程,拟合出一个接近真实数据分布的概率分布函数,即所谓的“规律”,大量的样本正是这条规律的基础,算法只是用数学的方式来求解。通过用户行为日志可获取全量用户曝光点击物料信息,通过用户及物料特征库抽取特征,从而构建出样本矩阵,通过离线计算保存到样本文件。
接下来需要对整个样本集做处理,否则会引入大量噪声,不能让模型很好的拟合出样本分布。
非真实用户访问样本
例如爬虫、机器人等大量非真实用户的频繁访问,带来大量高曝光未点击行为,会严重影响样本数据分布,一段时间窗口有大量相同用户id频繁访问远超正常访问量的均值等,刷次数方差较大的数据需要去除
极少行为用户样本
这类用户样本虽然是真实行为,但极少的行为并不能为其在模型中找到属于该类用户的“规律”,或者说引入这些数据后,模型会开始学习这类用户的数据分布,对整体分布的拟合带来噪声,易引起模型过拟合。通常对这类用户可以看做类似新用户,通过用户冷启动的手段为其探索兴趣补充推荐。
特征缺失值及异常值等处理
这里参考特征工程处理方法,针对方差较大的少量异常值做抛弃或均值处理,缺失值用均值或中值代替等
正负样本处理
机器学习中正负样本的选取也直接关系着训练出的模型效果,在推荐系统中不同公司也有针对自家业务采取的样本划分方法。
- 一次请求会产生N条推荐结果,但大部分手机端通常用户只能看到其中的m条,m<N,通过客户端埋点计算出用户真实可见曝光的物料,在这批物料中选取点击与未点击样本直观上一次曝光中可能有点击或无点击
- 早期yutube推荐中,会对所有用户选取相同数量训练样本,可以同时避免低活跃用户和高活跃用户对整体模型的影响,使训练的模型更符合绝大多数用户行为
- 对于有曝光无点击行为的用户,其曝光未点击的负样本可随机选取,这样可以学到这类用户“不感兴趣”的部分
- 样本在通过定时任务整合时需要做shuffle打散,避免同类用户样本数据扎堆引起数据分布偏差,在训练模型时,也通过batch训练方式中每个batch的样本也进行shuffle打散
总之正负样本处理还是要根据深入理解业务和用户行为基础上进行调整,可以让模型学习到更适合的效果。
生成样本数据后,将样本随机分成训练集与测试集,一般为七三开或八二开,丢给模型来训练了
模型训练
首次搭建排序模型可以先用基础模型如LR或GBDT跑出一个baseline快速上线,后续逐步迭代为复杂模型。推荐算法模型一般经历了由简入繁的过程,数据量不断增大,模型不断复杂,大规模数据集下深度学习模型已经逐渐成为主流,但这也是行业头部公司所独享,只有他们才有足够的数据和算力来支撑庞大复杂的模型,绝大多数公司在中等数据集下,仍然使用主流的线性模型,通过分析用户行为及数据,构建特征工程及样本数据优化,得来的效果要比深度学习模型更好。
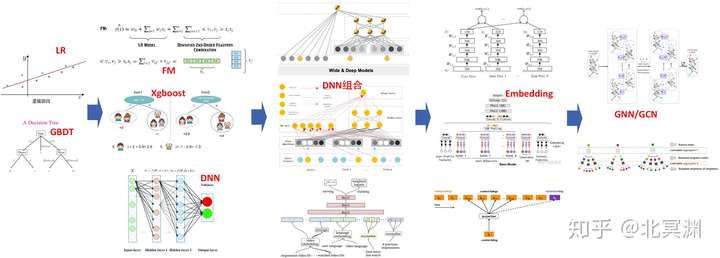 模型进化:lr/gbdt-》fm/xgboost/dnn》LR+GBDT/wide&amp;amp;amp;deep/deepFM》embedding》GNN/GCN &amp;amp;amp; 知识图谱
模型进化:lr/gbdt-》fm/xgboost/dnn》LR+GBDT/wide&amp;amp;amp;deep/deepFM》embedding》GNN/GCN &amp;amp;amp; 知识图谱
模型训练过程根据使用的框架不同,大体流程可以统一成下面的伪代码
# 从文件读入训练集与测试集
train_data = read(TRAIN_DATA_FILE)
test_data = read(TEST_DATA_FILE)
# 对数据处理并生成样本与特征数据结构
y_train, x_train = preprocess(train_data)
y_test, x_test = preprocess(test_data)
# 实例化模型,传入参数
# 对经典模型各主流框架中只需传入参数,若需对模型结构调整需要自己实现模型结构
model = SomeModel(y_train, x_train, y_test, x_test, batchsize, optimizer, learning_rate, other_param...)
# 开始训练
model.fit()
# 评估模型效果
model.evaluate() 通过优化训练数据、优化模型超参等方法训练得到AUC指标较好的模型,可提供给线上应用。模型训练可根据数据量和计算复杂度离线按天或小时定时训练更新。
线上预测
通常线上使用预测服务的形式实时提供模型推断功能,这时需要通过推荐引擎接口将待排序候选集的物料id、用户id以及请求上下文信息传给预测服务。预测服务中也分为特征抽取、物料打分排序、模型同步校验等模块。通过传入的物料id及用户id,可以从特征库中在线抽取特征,结合上下文特征得到所有候选集的特征信息,进而通过模型中各特征权重,计算每个物料的打分。这个过程中注意被抽取的特征id要同训练好模型中的特征权重id保持一致,同时各物料特征抽取和打分过程可以通过并行化方式提升系统性能。训练好的模型由离线训练流程定时同步到线上预测服务机器,注意同步时需要同时把模型的checksum一并同步并在服务端进行校验,当同步失败时仍使用缓存的上次同步模型进行预测,避免数据不一致。候选集物料被打分后进行整体排序,结果返回给推荐引擎。
 预测服务
预测服务
到此通过算法模型给出个性化排序的流程就打通了。关于模型打分步骤对于基于DNN的模型TensorFlow有专门tf.server用于部署生产环境的模型预测服务,TensorFlow也有为服务端语言golang/java/C++等专门适配
https://tensorflow.google.cn/install/lang_gotensorflow.google.cn golang调用tensorflow/keras训练的模型_cdj0311的专栏-CSDN博客_golang tensorflowblog.csdn.net
golang调用tensorflow/keras训练的模型_cdj0311的专栏-CSDN博客_golang tensorflowblog.csdn.net
对于传统机器学习模型LR、GBDT等,可以将模型特征id及权重直接序列化为文件,在排序服务端定时加载解析,打分预测时直接使用特征id及其权重值运算即可。
番外
推荐系统算法侧主流程架构大体就是这样,已经可以跑通一个基本模型并应用于线上观察效果。后续算法侧的迭代优化,一方面可以跟进业界前沿的模型方法,一方面通过分析用户行为与业务数据来尝试在特征和样本数据层面做优化,而后者可能才是产生更直接收益的法宝,毕竟不是所有公司都能有Google阿里家那种量级的用户数据,复杂模型应用起来因为过拟合的问题甚至带来负向效果。反过来说大厂在模型上的创新也是基于不断分析累积用户行为的经验得来,比如yutube关于视频推荐的论文
魔鬼吊儿郎:Youtube 排序系统:Recommending What Video to Watch Nextzhuanlan.zhihu.com
也是分析用户点击一个视频不一定是真喜欢,而可能和正好排在前面有关,从而设计模型结构将排序位置特征引入模型,通过多目标学习将这种实际样本“有偏”的影响消除。
本文来自博客园,作者:Slashout,转载请注明原文链接:https://www.cnblogs.com/SlashOut/p/14946133.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号