用少于2MB内存存下5百万个介于0到1千万之间的整数
使用bitmap,对每个bit为进行映射、
把每个bit位映射成一个整数,
https://blog.csdn.net/yangliuy/article/details/42874221
在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
转载自https://itimetraveler.github.io/2017/07/13/%E3%80%90%E7%AE%97%E6%B3%95%E3%80%9110%E4%BA%BFint%E5%9E%8B%E6%95%B0%EF%BC%8C%E7%BB%9F%E8%AE%A1%E5%8F%AA%E5%87%BA%E7%8E%B0%E4%B8%80%E6%AC%A1%E7%9A%84%E6%95%B0/
10亿int整型数,以及一台可用内存为1GB的机器,时间复杂度要求O(n),统计只出现一次的数?
首先分析多大的内存能够表示10亿的数呢?一个int型占4字节,10亿就是40亿字节(很明显就是4GB),也就是如果完全读入内存需要占用4GB,而题目只给1GB内存,显然不可能将所有数据读入内存。
- 位图法:用一个bit位来标识一个int整数。
- 分治法:分批处理这10亿的数。
int整型数是4字节(Byte),也就是32位(bit),如果能用一个bit位来标识一个int整数那么存储空间将大大减少。
另一种是分治法,内存有限,分批读取处理。
int型数据是 -2^31~2^31-1个数,共有2^32个数。接近43亿
位图法:int型是4字节(byte)=32位(bit)。每个int用1bit来表示,表示所有的int型数字需要2^32bit的空间,也就是2^32/8=512MB,即用512M就可以存储所有int型的数。
具体做法:因为每个int型数有32bit,所以申请int num[N/32+1]大小的数组即可,N=2^32为要查找的总数。
num中的每个元素在内存中都有32bit可以表示对应的十进制数0-32,所以相应的bitmap表如下:
num[0]:0~31
num[1]:32~63
num[2]:64~95
~~
假设这10亿int数据为:6,3,8,32,36,……,那么具体的BitMap表示为:
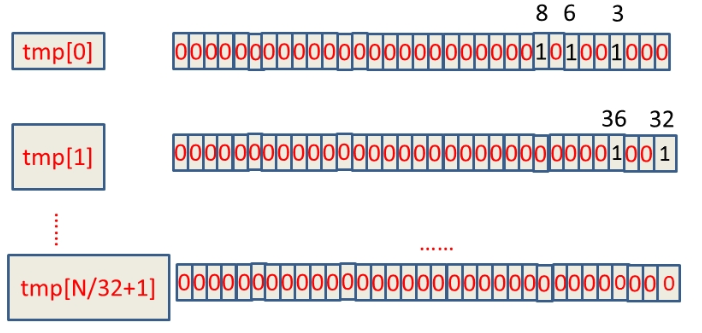
(1):判断int型数字target在哪个位置:将数字target/32,取整数部分,来得到在数组中的位置,然后target%32来得到在具体哪个bit上
如:8 8/32=0 即在num[0]的内部,8%32=8,则它在num[0]的第8个bit位
如何统计只出现一次的数:
可以分为3种情况:出现0次,出现1次,多于1次,需要使用2个bit位来表示,分别表示为00,01, 10, 11(无效)
然后顺序扫描10亿个数,在对应的双bit位标记该数出现的次数,最后取出所有双bit位为01的就是了
优点:
-
运算效率高,不许进行比较和移位;2
-
占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
Bit-Map可作为数据的查找、去重、排序等操作。比如以下几个例子:
1、在3亿个整数中找出重复的整数个数,限制内存不足以容纳3亿个整数
对于这种场景可以采用2-BitMap来解决,即为每个整数分配2bit,用不同的0、1组合来标识特殊意思,如00表示此整数没有出现过,01表示出现一次,11表示出现过多次,就可以找出重复的整数了,其需要的内存空间是正常BitMap的2倍,为:3亿*2/8/1024/1024=71.5MB。
具体的过程如下:扫描着3亿个整数,组BitMap,先查看BitMap中的对应位置,如果00则变成01,是01则变成11,是11则保持不变,当将3亿个整数扫描完之后也就是说整个BitMap已经组装完毕。最后查看BitMap将对应位为11的整数输出即可。、
2、对没有重复元素的整数进行排序
对于非重复的整数排序BitMap有着天然的优势,它只需要将给出的无重复整数扫描完毕,组装成为BitMap之后,那么直接遍历一遍Bit区域就可以达到排序效果了。
举个例子:对整数4、3、1、7、6进行排序:

直接按Bit位输出就可以得到排序结果了。
3、已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话。
4、2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
将bit-map扩展一下,用2bit表示一个数即可:0表示未出现;1表示出现一次;2表示出现2次及以上,即重复,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
最后放一个使用Byte[]数组存储、读取bit位的示例代码,来自利用位映射原理对大数据排重:
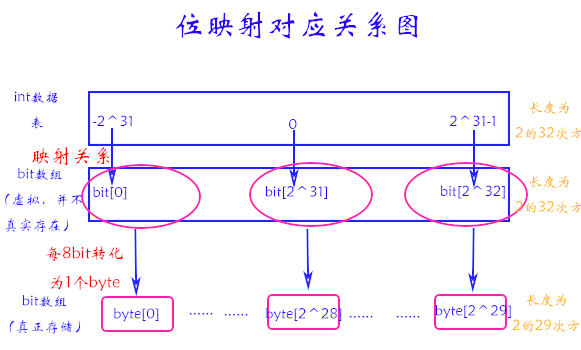
由于最大值可能是2^32,故用long接收。
long bitIndex = num + (1l << 31);
计算在转化为byte[]数组的索引,由于上面定义的bitIndex 索引是非负数,故无需引入位运算去符号。
int index = (int) (bitIndex / 8);
计算bitIndex 在byte[]数组索引index 中的具体位置。
int innerIndex = (int) (bitIndex % 8);
引入位运算将byte[]数组索引index 的各个位按权值相加
dataBytes[index] = (byte) (dataBytes[index] | (1 << innerIndex));
这样就解决了整个大数据读取排重的问题。
http://yacare.iteye.com/blog/1969931
class BitmapTest {
private static final int CAPACITY = 1000000000;//数据容量
// 定义一个byte数组缓存所有的数据
private byte[] dataBytes = new byte[1 << 29];
public static void main(String[] args) {
BitmapTest ms = new BitmapTest();
byte[] bytes = null;
Random random = new Random();
for (int i = 0; i < CAPACITY; i++) {
int num = random.nextInt();
System.out.println("读取了第 " + (i + 1) + "\t个数: " + num);
bytes = ms.splitBigData(num);
}
System.out.println("");
ms.output(bytes);
}
/**
* 读取数据,并将对应数数据的 到对应的bit中,并返回byte数组
* @param num 读取的数据
* @return byte数组 dataBytes
*/
private byte[] splitBigData(int num) {
long bitIndex = num + (1l << 31); //获取num数据对应bit数组(虚拟)的索引
int index = (int) (bitIndex / 8); //bit数组(虚拟)在byte数组中的索引
int innerIndex = (int) (bitIndex % 8); //bitIndex 在byte[]数组索引index 中的具体位置
System.out.println("byte[" + index + "] 中的索引:" + innerIndex);
dataBytes[index] = (byte) (dataBytes[index] | (1 << innerIndex));
return dataBytes;
}
/**
* 输出数组中的数据
* @param bytes byte数组
*/
private void output(byte[] bytes) {
int count = 0;
for (int i = 0; i < bytes.length; i++) {
for (int j = 0; j < 8; j++) {
if (!(((bytes[i]) & (1 << j)) == 0)) {
count++;
int number = (int) ((((long) i * 8 + j) - (1l << 31)));
System.out.println("取出的第 " + count + "\t个数: " + number);
}
}
}
}
}
2、分治法
分治法目前看到的解决方案有哈希分桶(Hash Buckets)和归并排序两种方案。
哈希分桶的思想是先遍历一遍,按照hash分N桶(比如1000桶),映射到不同的文件中。这样平均每个文件就10MB,然后分别处理这1000个文件,找出没有重复的即可。一个相同的数字,绝对不会夸文件,有hash做保证。因为算法具体还不甚了解,这里先不做详细介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号