哈希——并查集结构
并查集解决的问题:(速度快)
1.非常快的检查两个元素是否属于一个集合 isSameSet(A, B)
2.将两个元素各自所在的集合,合并在一起 union(A, B) 合并的是A,B所在的 集合,而不是单纯的合并A和B
代表结点:指向自己的结点
初始化时,要有所有的样本结点
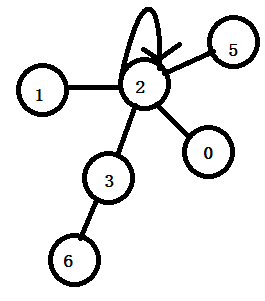 2是代表结点
2是代表结点
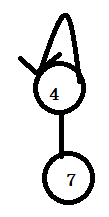 4是代表结点
4是代表结点
isSameSet(A, B) 查找A,B的上面的结点,知道找到指向自己的代表结点,如果是同一个代表结点,就是true,否则就是false
union(A, B) 将两个代表结点合并即可,结点数少的挂到结点数多的上面
优化(扁平化处理):当查找,从链上某个结点往上找它的代表结点时,找到之后,沿途所经过的所有结点,在找完之后统统指向代表结点
(只要涉及到链的查找动作时,都优化)
如下面找12结点的代表结点时,
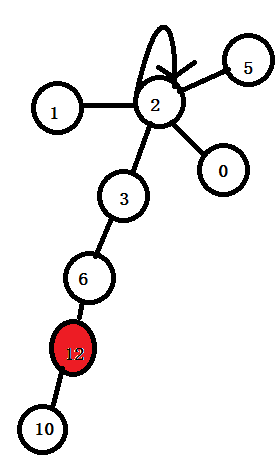
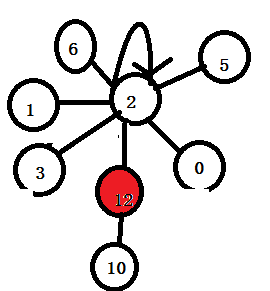
找到代表结点2之后,将12往上的结点统统直接挂到2结点上,但是12结点下面的不管
public class UnionFind {
public class Node{
//随便定义
}
public static class UnionFindSet{
//key为当前结点, value指向父结点
HashMap<Node, Node> fatherMap;
//key为当前结点,value它他连接的结点个数
HashMap<Node, Integer> sizeMap;
//构造器
public UnionFindSet(List<Node> nodes){
fatherMap = new HashMap<>();
sizeMap = new HashMap<>();
for(Node node : nodes){
//初始化的结点的父结点指向自己
fatherMap.put(node, node);
//初始化的结点的结点为1
sizeMap.put(node, 1);
}
}
//找到代表结点,并且将一路上的结点都扁平化(都挂在代表结点上)
public Node findHead(Node node){
Node father = fatherMap.get(node);
if(node != father){
father = findHead(father);
}
fatherMap.put( node, father );
return father;
}
//判断两个结点是否属于同一个集合
public boolean isSameSet(Node node1, Node node2){
return findHead(node1) == findHead(node2);
}
//将两个结点所在的集合合并
public void union(Node node1, Node node2){
Node father1 = findHead(node1);
Node father2 = findHead(node2);
if(father1 != father2){
int size1 = sizeMap.get(father1);
int size2 = sizeMap.get(father2);
if(size1 >= size2){
//当第一个代表结点的size大于第二个代表结点的size时,
// 将第二个代表结点挂在第一个上面,同时更新第一个代表结点的size值
//注意:在fatherMap中,key是结点,value是其前面的结点
fatherMap.put(father2, father1);
sizeMap.put(father1, size1 + size2);
}else{
fatherMap.put(father1, father2);
sizeMap.put(father2, size1 + size2);
}
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号