
[云计算]一致性哈希算法
先引入简单哈希算法
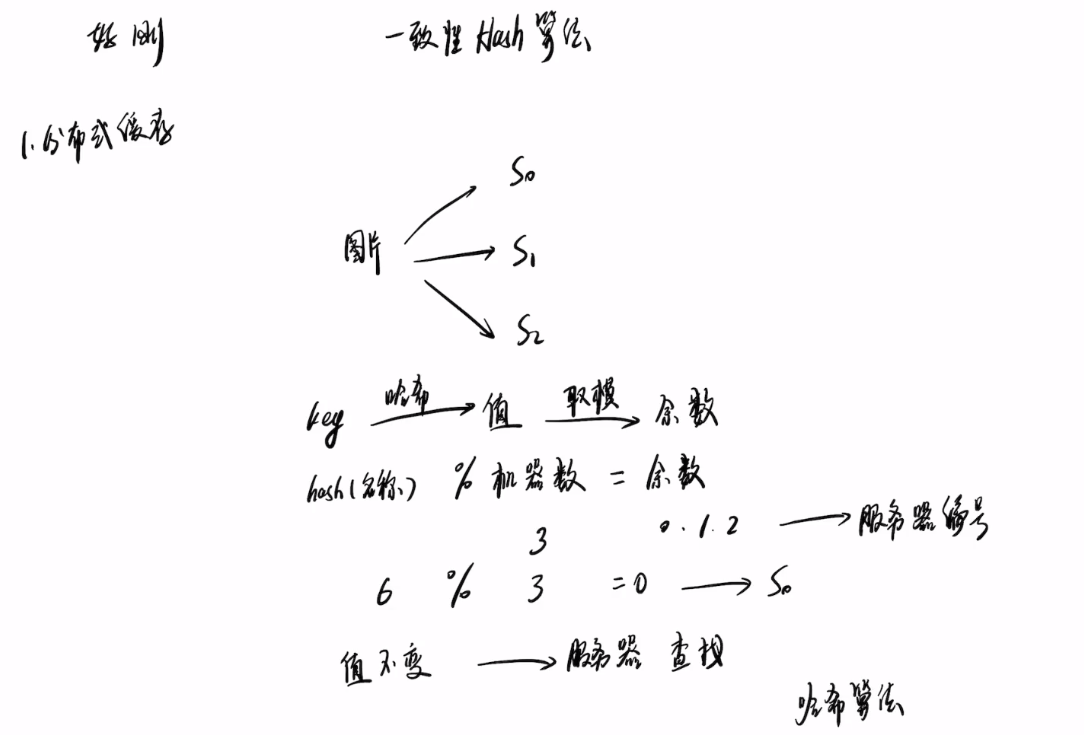
假设有三台缓存服务器,分别为S0,S1,S2。如何使得缓存均匀的分布在三台服务器上?
简单来说就是将缓存的键进行哈希计算,对获得的值进行取模,取模得到的余数来决定数据缓存到哪台服务器上。
举例:
hash(键/key)% 机器数 = 余数
假设hash(键/key)= 6,机器数为3
则 6 % 3 = 0,因此,数据将缓存在服务器S0上。
因为,同一个键(Key)进行哈希计算得到的值(Value)是不变的。
所以,当需要读该图片的时候,对图片的键再次进行哈希就可以在相应的服务器上读取该图片
但是,简单哈希算法有个缺陷,就是当服务器的数量发生增加或者减少的时候,取模得到的数值就会不一样。
举例:
hash(键/key)% 机器数 = 余数
假设hash(键/key)= 6,机器数增加到4台
则 6 % 4 = 2,因此,将从S2上读取数据。
但是,数据实际上存放的是S0而不是S2,所以就会发生缓存失效的情况。
因此,为了解决这个问题,就发明了一致性哈希算法(DHT)。
一致性哈希是什么?
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题,解决了简单哈希算法在分布式哈希表中存在的动态伸缩等问题。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
平衡性、单调性、分散性、负载
引入环形Hash空间:按照常用的Hash算法来将对应的Key哈希到一个具有232次方个桶的空间中,即范围为(0,232-1)的数字空间中。可以把这些数字头尾相连,想象成一个闭合的环形,如图。
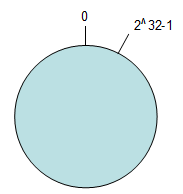
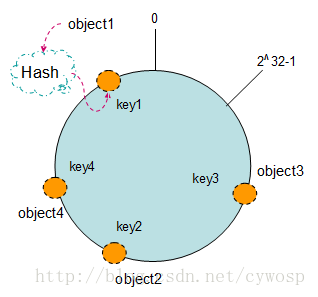
把数据通过一定的hash算法处理后映射到环上
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
把机器节点通过hash算法映射到环上
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
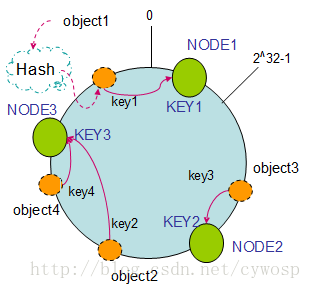
顺时针转动,第一个遇到的服务器,负责缓存数据。
此时,当节点发生增加或者减少的时候,都会使得迁移的数据量最小化,避免了大量数据的迁移,减轻了服务器的压力。
同时,可以引入虚拟节点,使得数据更加平均的分布在每一个节点上,实现负载均衡的效果。
本文作者:SkyBiuBiu
本文链接:https://www.cnblogs.com/Skybiubiu/p/14860750.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步