
[Python]爬虫实例-深大新闻标题

import requests from lxml import etree #1.页面获取 url = "https://www.szu.edu.cn/index/mtsd.htm" response = requests.get(url) response.encoding="utf-8" wb_data = response.text html = etree.HTML(wb_data) #print(wb_data) #2.数据定位 infos = html.xpath("//ul[@class='news-list']/li/a/text()") for info in infos: print(info)

#多页 import requests from lxml import etree #1.链接处理 urls = ["https://www.szu.edu.cn/index/mtsd/{}.htm".format(i)for i in range(1,46)] urls.append("https://www.szu.edu.cn/index/mtsd.htm") urls = urls[::-1] #2.写入文件 f = open("深大爬虫.csv","w",encoding = "ANSI") fileheader = ["标题"] dict_writer = csv.DictWriter(f,fileheader) dict_writer.writeheader() #页面信息(翻页) for url in urls: response = requests.get(url) response.encoding="utf-8" wb_data = response.text html = etree.HTML(wb_data) #3.数据定位 (每一页) infos = html.xpath("//ul[@class='news-list']/li/a/text()") for info in infos: dict_writer.writerow({"标题":info}) f.close()
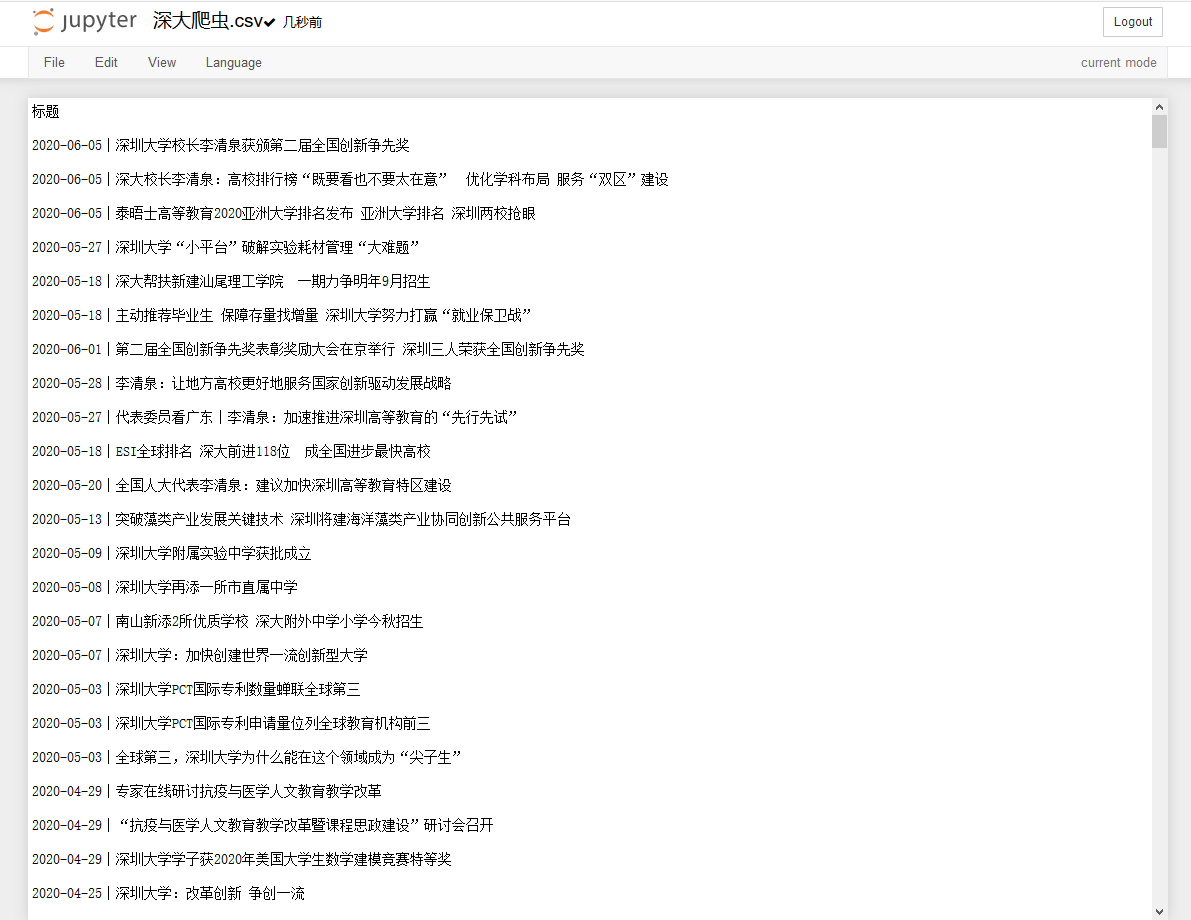
# UTF-8 改 ANSI,否则 在excel中打开会乱码
本文作者:SkyBiuBiu
本文链接:https://www.cnblogs.com/Skybiubiu/p/13073997.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步