李宏毅《机器学习》总结 - 2022 HW1(回归) Strong Baseline
调参调吐了。目前做的最好的是 private 1.09 / public 1.04
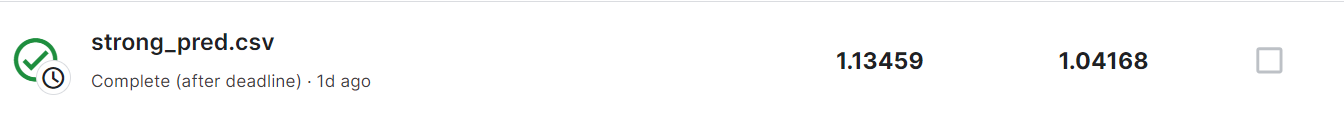

代码:https://colab.research.google.com/drive/1Rhne-XV8P6u_qSAjKsKA0NyAmbzQWbll?usp=sharing
分析
对代码的一些理解:
这里是构建神经网络模型的代码
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
self.layers = nn.Sequential(
# nn.Linear(input_dim, 32),
# nn.ReLU(),
# nn.Linear(32, 32),
# nn.ReLU(),
# nn.Linear(32, 32),
# nn.ReLU(),
# nn.Linear(32, 1),
# nn.Linear(input_dim, 32),
# nn.BatchNorm1d(32),#使用BN,加速模型训练
# nn.Dropout(p=0.2),#使用Dropout,减小过拟合,注意不能在BN之前
# nn.LeakyReLU(),#更换激活函数
# nn.Linear(32, 1)
nn.Linear(input_dim, 16),
nn.LeakyReLU(0.1),
nn.Linear(16, 8),
nn.LeakyReLU(0.1),
nn.Linear(8, 1)
)
self.criterion = nn.MSELoss(reduction='mean')
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
def cal_loss(self, pred, target):
regu_loss = 0
for param in model.parameters():
regu_loss += torch.sum(param ** 2)
return self.criterion(pred, target) + 0.0007*regu_loss
这里我试了三种模型:
- fully connected network,激活函数用 relu(用 Sigmoid 效果更差)
- BatchNorm 调整数据至正态分布、Dropout 减少过拟合、激活函数改为 Leakyrelu
- fully connected network,激活函数用 leakrelu
其中第 3 种效果较好
此外,我还尝试了在计算 loss 时引入 这一项(类比岭回归,在函数 cal_loss 中,即 L2 regularization),并达到了 private 1.09
如何挑选 feature 呢?使用 python 中的 sklearn 的回归函数,找到和最后结果相关性最大的几个 feature,程序如下:
import numpy as np
import pandas as pd
data = pd.read_csv("./covid.train.csv")
# print(len(data.columns))
x = data[data.columns[0:117]]
y = data[data.columns[117]]
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
x = (x - x.min()) / (x.max() - x.min())
selector = SelectKBest(score_func=f_regression, k = 10)
fit = selector.fit(x, y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(x.columns)
featurescore = pd.concat([dfcolumns, dfscores], axis=1)
featurescore.columns = ['Speces', 'Score']
print(featurescore.nlargest(25, 'Score'))
训练过程的模型使用了 Adam
训练的代码如下(训练 + 验证):
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
#optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate']*10)
writer = SummaryWriter() # Writer of tensoboard.
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = []
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
mean_train_loss = sum(loss_record)/len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
首先利用 train 中的数据训练一个 model
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
这里,先将 optimizer 的梯度置为 0,然后利用 loss 的 backward 函数,通过反向传播方法计算出当前位置的梯度,再将 optimizer 的位置沿着梯度乘以 learning rate 的方向移动(这个操作在 .step() 中)
.detach() 是切断梯度的传播
然后再利用 validator 中的数据求出当前模型在 valid 中的 loss,进行筛选即可。
这样训练集和验证集是预先弄好的,可以考虑每个 epoch 都随机划分,这样就是 cross validation 了。
分类:
机器学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下
2023-01-25 关于AC自动机的一些理解 || Luogu3121 & 4824 Censoring - 哈希 - AC自动机
2023-01-25 常用哈希质数