李宏毅《机器学习》总结 - CNN
使用场景:对图片进行分类
首先,将图片变成向量。例如,对于一个彩色的 \(N\times N\)(这个 N 指的是像素个数) 图片,其对应着一个 \(N\times N\times 3\) 的矩阵(其中 3 是图片的 channel,在彩色图片中,每个像素由 RGB 构成,因此 channel 为 3)
一个初始的想法
将这个矩阵拉长,变成一个向量,然后连一个 fully connected network。
效率太低
因此需要引入 CNN,有两种理解的方法,这两种本质上是一样的。
(注意:CNN 主要是通过缩减了很多图片中的信息来进行优化,具有较大局限性,因此如果不是图像处理的问题的话,需要慎用 CNN)
1
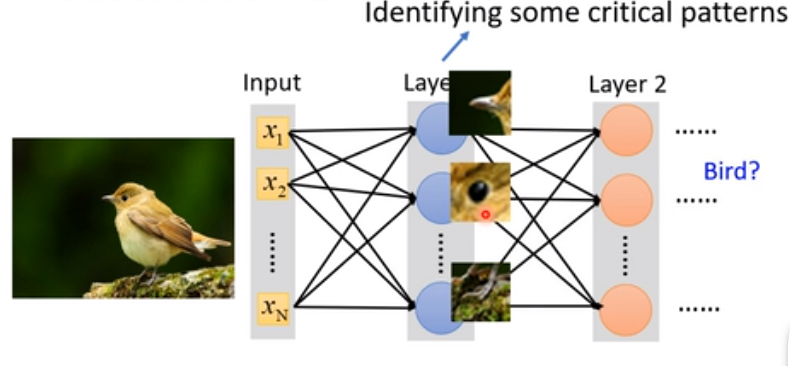
考虑分类的过程,实际上可以认为是找到一些“特征”。如识别鸟,只需要找到鸟嘴就可以判断。因此是否可以每次识别图片的一部分?——引入感受野(Receptive field)的概念
感受野就是在原来的矩阵中找到若干个小矩阵(如 \(3\times 3\) 的,称为 kernal size),将这个小矩阵作为“特征”输入到 neural network 里面。
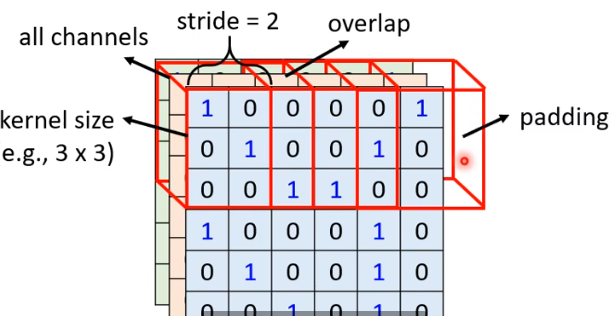
首先,感受野是可以重叠的,也可以是长方形,也可以有大有小。所以可以在两个维度都设定一个步长(stride),这样能选出一堆感受野
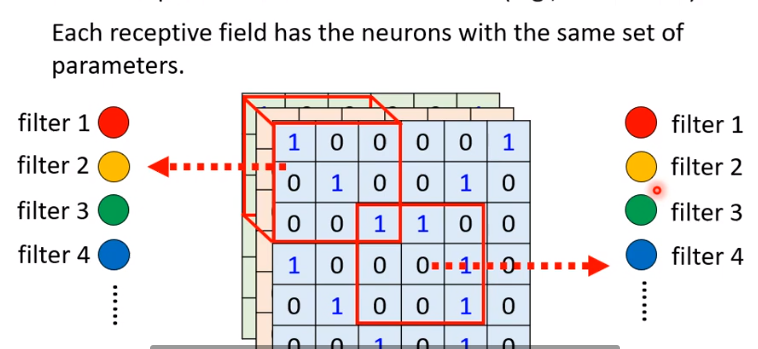
对每个感受野,用一组 neuron 来处理(可以理解为有很多 feature,每个 neuron 处理其中一个 feature)
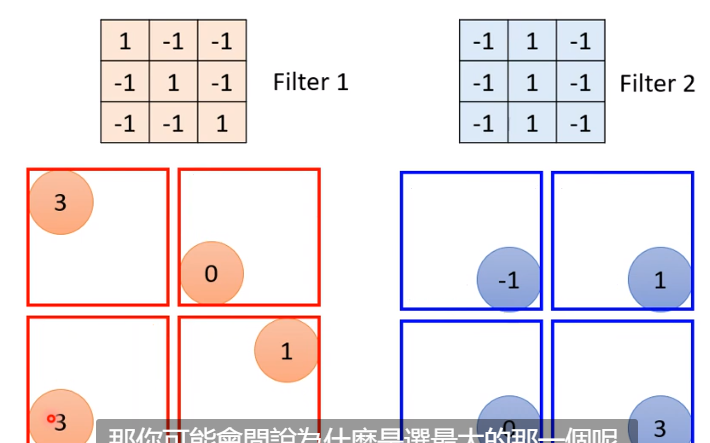
另外,如果有一个 feature,出现在多个位置,此时不应该用多个 neuron,而应该用一个,这就是参数共享,即在neural network 中的 weight 是要相同的。而某一个 feather 对应的共享参数的 neuron,我们称之为 filter
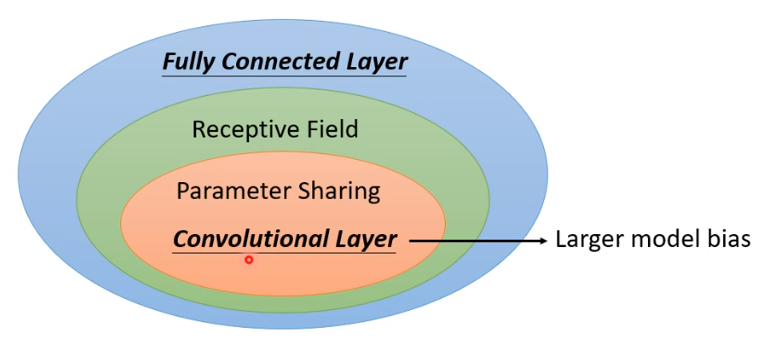
关系:
2
直接考虑 filter 和图片对应矩阵(此时,假设图片是黑白的,channel 为 1,因此对应的矩阵是 \(N\times N\times 1\) 的)进行的运算
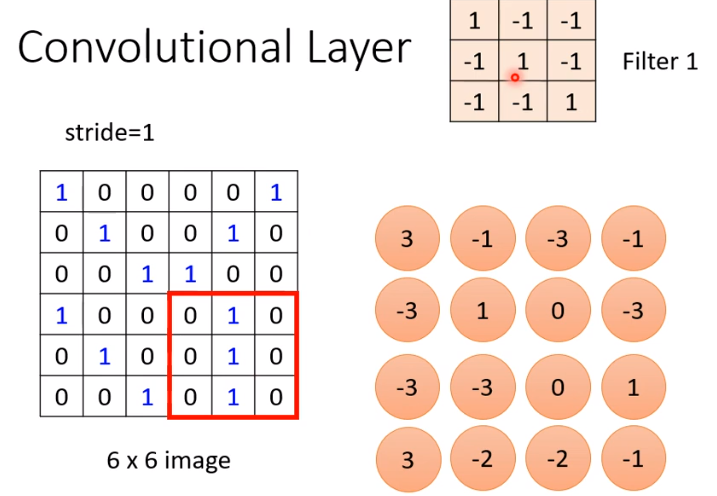
这里进行的运算是 inner product(对应位置相乘再相加),得到结果矩阵
不同的 filter 和矩阵做运算,可以得到不同的结果矩阵(这些结果矩阵叫做 feature map)
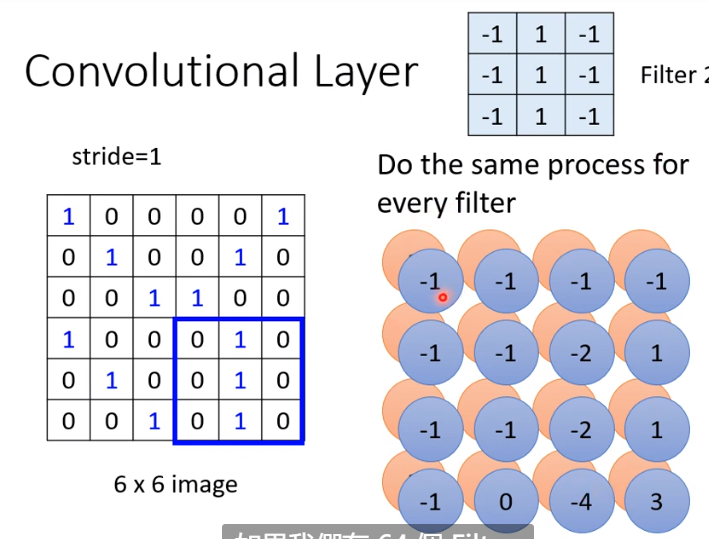
有多少个 feature map 呢?就是 filter 的数量,这也决定了 feature map 的“高度”(channel,即第三维的大小),如 64 张图片就有 64 个 channel
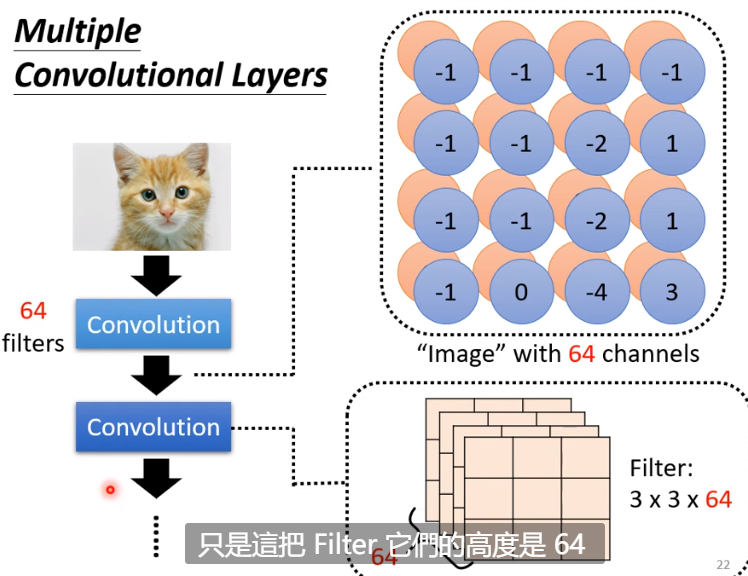
因此,这样做的步骤就是:先将多个 filter 和当前矩阵求 inner product(这个过程即 convolution),得到若干个 feature map,并将其作为下一个操作的当前矩阵,继续操作。
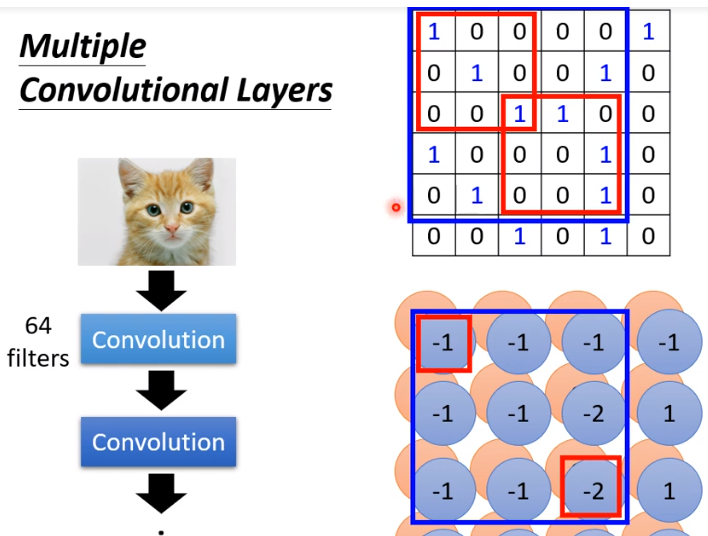
有没有可能一个比较大的 feature 无法被识别到?不会。我们考虑一次 convolution 之后的下一个 convolution,我们发现拿一个 filter 做一次 inner product(蓝色框内),实质上是对原矩阵的 \(5\times 5\) 进行了运算,这就能扩大识别范围了。
- 池化
是一种 operator/函数(如ReLU/Sigmoid),不用训练。
将得到的 feature map 几个组成一组(如 \(2\times 2\)分成一组),然后将每一组中最大的那个元素提取出来,得到新的矩阵。
好处就是减少了数据规模,提升了效率。
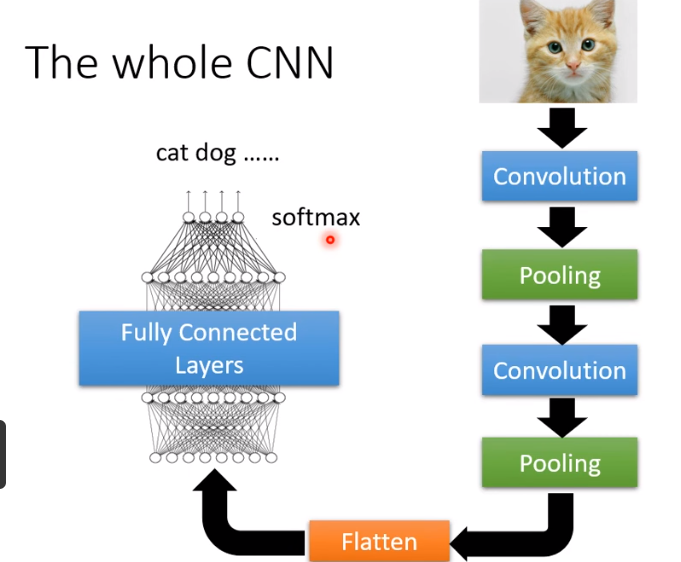
总的 CNN 框架如图:
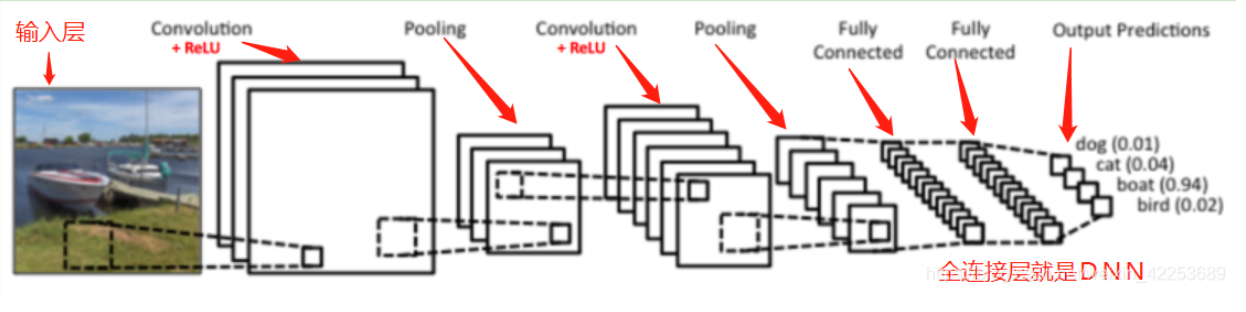
一种可能的实现方法(HW 3):
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号