

xpath解析
xpath
简介:**XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
安装:pip install lxml
调用方法:
# 先导包
from lxml import etree
# 将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定的节点
# 1. 本地文件
tree = etree.parse(文件名)
tree.xpath("xpath表达式")
# 2. 网络数据
tree = etree.HTML(网页内容字符串)
tree.xpath("xpath表达式")
xpath语法
xpath实例文档
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
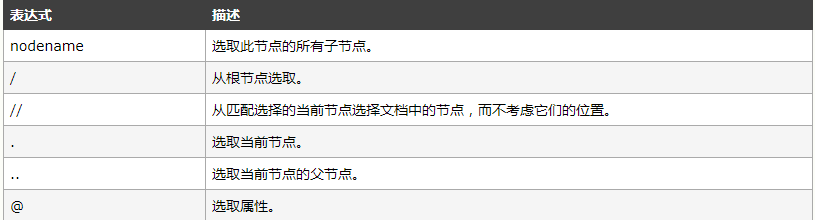
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
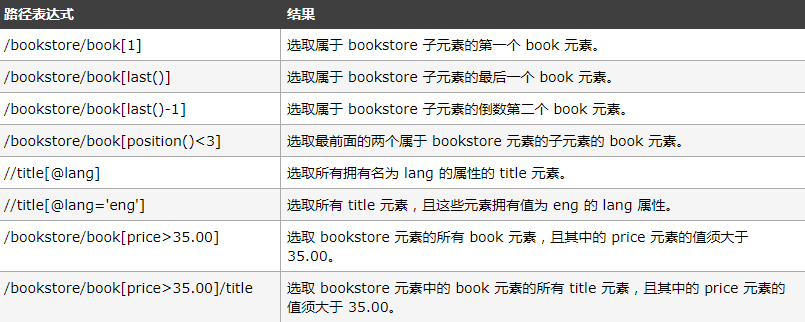
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

Xpath轴
轴可以定义相对于当前节点的节点集
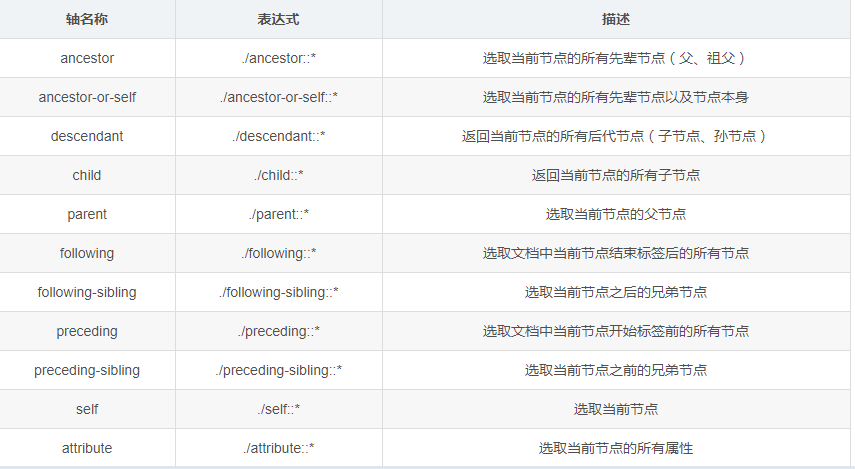
语法简介
1,选取节点
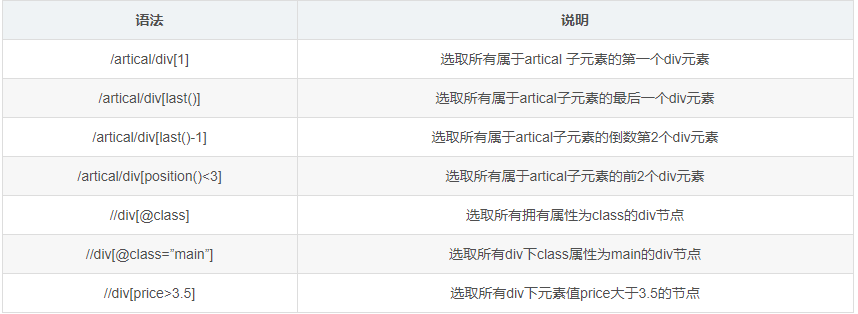
nodename # 选取nodename节点的所有子节点 xpath(‘//div’) # 选取了所有div节点
/ # 从根节点选取 xpath(‘/div’) # 从根节点上选取div节点
// # 选取所有的当前节点,不考虑他们的位置 xpath(‘//div’) # 选取所有的div节点
. # 选取当前节点 xpath(‘./div’) # 选取当前节点下的div节点
.. # 选取当前节点的父节点 xpath(‘..’) # 回到上一个节点
@ # 选取属性 xpath(’//@calss’) # 选取所有的class属性
#######################⬇例子⬇######################
ret=selector.xpath("//div")
ret=selector.xpath("/div")
ret=selector.xpath("./div")
ret=selector.xpath("//p[@id='p1']")
ret=selector.xpath("//div[@class='d1']/div/p[@class='story']")
2,谓语
表达式 结果
xpath(‘/body/div[1]’) # 选取body下的第一个div节点
xpath(‘/body/div[last()]’) # 选取body下最后一个div节点
xpath(‘/body/div[last()-1]’) # 选取body下倒数第二个div节点
xpath(‘/body/div[positon()<3]’) # 选取body下前两个div节点
xpath(‘/body/div[@class]’) # 选取body下带有class属性的div节点
xpath(‘/body/div[@class=”main”]’) # 选取body下class属性为main的div节点
xpath(‘/body/div[@price>35.00]’) # 选取body下price元素值大于35的div节点
#######################⬇例子⬇######################
ret=selector.xpath("//p[@class='story']//a[2]")
ret=selector.xpath("//p[@class='story']//a[last()]")
3,通配符
Xpath通过通配符来选取未知的XML元素
表达式 结果
xpath(’/div/*’) # 选取div下的所有子节点
xpath(‘/div[@*]’) # 选取所有带属性的div节点
#######################⬇例子⬇######################
ret=selector.xpath("//p[@class='story']/*")
ret=selector.xpath("//p[@class='story']/a[@class]")
4,取多个路径
使用 “|” 运算符可以选取多个路径
表达式 结果
xpath(‘//div|//table’) # 选取所有的div和table节点
#######################⬇例子⬇######################
ret=selector.xpath("//p[@class='story']/a[@class]|//div[@class='d3']")
print(ret)
5,Xpath轴
轴可以定义相对于当前节点的节点集
轴名称 表达式 描述
ancestor xpath(‘./ancestor::*’) # 选取当前节点的所有先辈节点(父、祖父)
ancestor-or-self xpath(‘./ancestor-or-self::*’) # 选取当前节点的所有先辈节点以及节点本身
attribute xpath(‘./attribute::*’) # 选取当前节点的所有属性
child xpath(‘./child::*’) # 返回当前节点的所有子节点
descendant xpath(‘./descendant::*’) # 返回当前节点的所有后代节点(子节点、孙节点)
following xpath(‘./following::*’) # 选取文档中当前节点结束标签后的所有节点
following-sibing xpath(‘./following-sibing::*’) # 选取当前节点之后的兄弟节点
parent xpath(‘./parent::*’) # 选取当前节点的父节点
preceding xpath(‘./preceding::*’) # 选取文档中当前节点开始标签前的所有节点
preceding-sibling xpath(‘./preceding-sibling::*’) # 选取当前节点之前的兄弟节点
self xpath(‘./self::*’) # 选取当前节点
6,功能函数
使用功能函数能够更好的进行模糊搜索
函数 用法 解释
starts-with xpath(‘//div[starts-with(@id,”ma”)]‘) # 选取id值以ma开头的div节点
contains xpath(‘//div[contains(@id,”ma”)]‘) # 选取id值包含ma的div节点
and xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) # 选取id值包含ma和in的div节点
text() xpath(‘//div[contains(text(),”ma”)]‘) # 选取节点文本包含ma的div节点
element对象
from lxml.etree import _Element
for obj in ret:
print(obj)
print(type(obj)) # from lxml.etree import _Element
'''
Element对象
class xml.etree.ElementTree.Element(tag, attrib={}, **extra)
tag:string,元素代表的数据种类。
text:string,元素的内容。
tail:string,元素的尾形。
attrib:dictionary,元素的属性字典。
#针对属性的操作
clear():清空元素的后代、属性、text和tail也设置为None。
get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值。
items():根据属性字典返回一个列表,列表元素为(key, value)。
keys():返回包含所有元素属性键的列表。
set(key, value):设置新的属性键与值。
#针对后代的操作
append(subelement):添加直系子元素。
extend(subelements):增加一串元素对象作为子元素。#python2.7新特性
find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。
findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。
findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。
insert(index, element):在指定位置插入子元素。
iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。#python2.7新特性
iterfind(match):根据tag或path查找所有的后代。
itertext():遍历所有后代并返回text值。
remove(subelement):删除子元素。
'''
