Border / 回文 Border 理论小记
普通 Border 理论#
证明:不妨钦定
对于
对于
由
使用更相减损术来归纳,即可得证。
当然有更厉害的强周期引理:若
证明:我们只需考虑匹配次数
考虑第一、二次匹配距离为
又根据
而第一次匹配的位置
对于
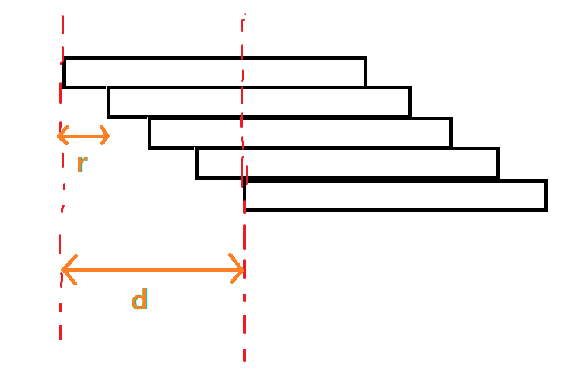
进一步可得这些匹配的位置是以
证明:
考虑其中的两个长度
那么对应的,有周期
因为
由于
因此这些 Border 组成了公差为
证明不会,直接拿结论用好了,这个用的比较广泛。
回文 Border 理论#
证明:
一个回文串
对于一个 Border
证毕。
证明:考虑反证。
如果多出现了一次,起始位置为
那么
而
证毕。
结合普通 Border 论中的
回文划分 dp#
考虑一个问题:一个由小写字母构成的字符串
设
我们把转移放到 PAM 上,可以枚举一条链上的点。
但还是
设
现在考虑一个等差序列,公差为
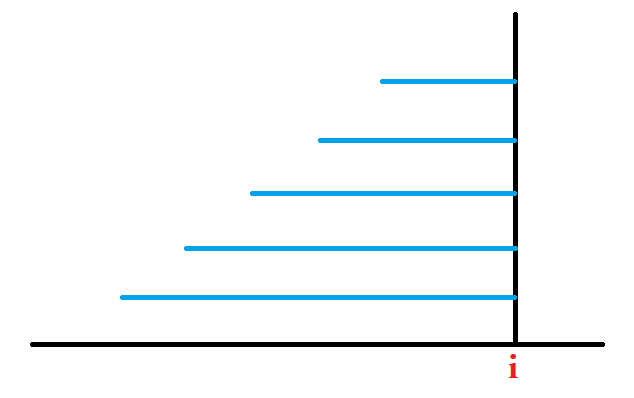
我们根据理论,很容易推出这些后缀上一次出现位置(除了最下面那个后缀):
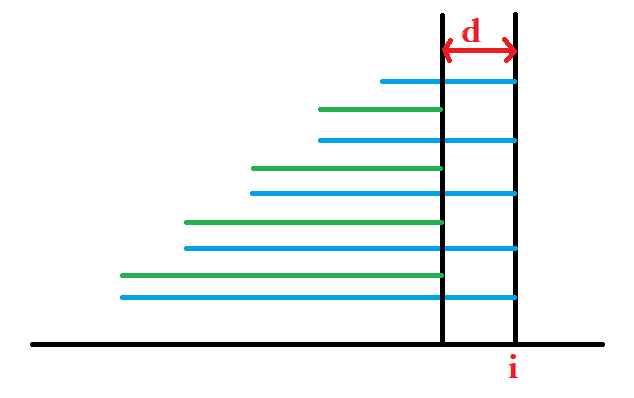
我们会发现除了最上面那个后缀,其他部分的贡献之前都在
每次取出链底
现在考虑正确性,我们可以证明上面的后缀上一次一定是对应的最长回文后缀:
反证,如果上面的后缀上一次出现时不是对应的最长后缀,因为他的长度的
时间复杂度
点击查看代码
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const ll maxn=1e6+10, mod=1e9+7;
struct node{
ll fail,len,ch[26],slk;
}a[maxn];
ll n,f[maxn],tot,las,dif[maxn],g[maxn];
char s[maxn];
ll ad(const ll &x,const ll &y) {return x+y>=mod? x+y-mod:x+y;}
void ins(ll i,ll c){
ll p=las;
while(s[i-a[p].len-1]-'a'!=c) p=a[p].fail;
if(!a[p].ch[c]){
ll np=las=++tot, q=a[p].fail;
while(s[i-a[q].len-1]-'a'!=c) q=a[q].fail;
if(!a[q].ch[c]) a[np].fail=2;
else a[np].fail=a[q].ch[c];
a[p].ch[c]=np, a[np].len=a[p].len+2;
dif[np]=a[np].len-a[a[np].fail].len;
a[np].slk=(dif[np]!=dif[a[np].fail]? a[np].fail:a[a[np].fail].slk);
} else las=a[p].ch[c];
}
int main()
{
scanf("%s",s+1); n=strlen(s+1);
tot=2, las=1;
a[1].fail=a[2].fail=1, a[1].len=-1;
f[0]=1;
for(ll i=1;i<=n;i++){
ins(i,s[i]-'a');
for(ll x=las;x>2;x=a[x].slk){
g[x]=f[i-a[a[x].slk].len-dif[x]];
if(a[x].slk!=a[x].fail) g[x]=ad(g[x],g[a[x].fail]);
f[i]=ad(f[i],g[x]);
}
}
printf("%lld",f[n]);
return 0;
}
例题#
考虑把字符串改成
我们只在偶数的
考虑可以离线怎么做。
枚举链上的所有点,给
考虑等差链划分,我们可以发现一条等差链很多贡献都会抵消,只需要求最上面长度和最下面的后缀上一次出现位置。
前者容易,后者考虑树上操作。每个
用主席树即可转为在线查询。记录
出处:https://www.cnblogs.com/Sktn0089/p/18085889
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下