

git clone linux库踩过的坑及解决方法
1.前言
我在git clone linux开源仓库中遇到了很多的麻烦,解决这些麻烦也花费了我大量的时间,于是打算记录我解决这个问题的过程。
2.过程
最开始的时候我是直接在git bash中使用:git clone git@github.com:torvalds/linux.git命令来直接clone linux的源代码库,但是一开始的下载速度非常慢,等了很久,在波动的网速下总算将所有的object下载下来了(一看发现有3GB多),但后面就遇到了困扰我最久的一个问题:
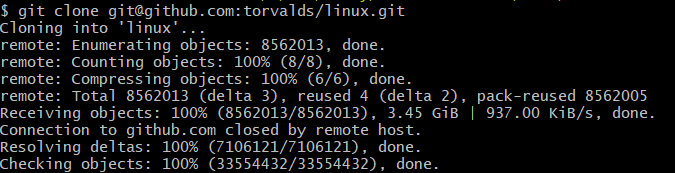
这个closed by remote host的问题经我百度之后发现一般都是在ssh链接上发生的,没有适用我这个情况的帖子。所以我只能盲人摸象。
一开始我认为是网速的问题,然后挂了VPN进行下载,在平均2-3MB/s的网速下仍有这个问题,认为并不是网速的缘故。后面我发现最花费时间的是resolving deltas这个步骤,而且这个connect closed的跳出时间在resolving之前,而且百度方面也没有相似的问题,这一阶段我已经卡了很久了。
我git clone了好几次,也尝试过失败后直接进行git pull,但仍然是一样的问题。为了提高网速我甚至采用先把代码库clone到国内的gitee网站上再clone的方法,但是gitee对于1GB以上的仓库需要收费,不了了之。
然后我开始认为是linux库过大的原因,于是打算提高buffer的容量,但仍然没有解决。
后面又打算延长ssh的链接时间,但是并没有找到正确的命令,无法延长。
之后我总算找到了正确的解决方法。
3.解决方法
主要参考网址:https://blog.csdn.net/SmallSource/article/details/90691700
我采用的方法是浅层clone,命令是
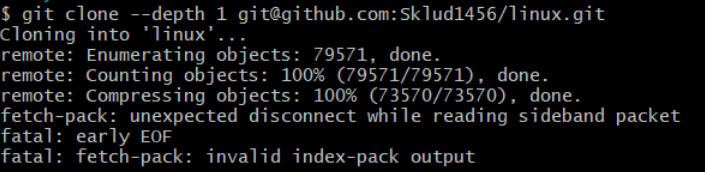
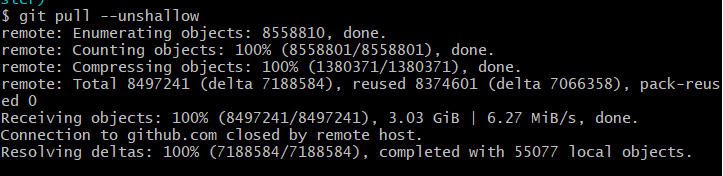
运行结束后其中的commit数量变成了全部的commit数量。
4.总结
对于git clone我还是第一次踩这么多的坑,而且网上没有对于这种情况的完整解释,且该方法可能对其他一些commit数量多、总量大的仓库也有借鉴作用,所以进行了记录,希望可以帮到其他人。
我现在觉得一开始直接git clone报connect closed的问题也有可能是没有关闭文件保护的原因,但是我并没有进行验证。已经有了一个解决方法,够用就行。

