
SQL的一些注意事项
SQL总结
1)find_in_set
查询表中的某列是否存在单个值(或者集合中的值)
部门id查询,(父部门可以查所有子部门)
ancestors为祖级列表
FROM tb_school WHERE company_id IN(SELECT dept_id FROM sys_dept WHERE (find_in_set(#{companyId}, ancestors)) or dept_id= #{companyId})
2)replace into
replace是insert的增强版
replace into 首先尝试插入数据到表中,
1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。
2. 否则,直接插入新数据
3)ON DUPLICATE KEY UPDATE
配合mybatis的insert
<insert id="saveOrUpdateYiYuan" parameterType="java.util.List"> insert into yiyuan (id,agent,enterprise,operator,remark) values <foreach collection="listData" item="item" index="index" separator=","> (#{item.id},#{item.agent},#{item.enterprise},#{item.operator},#{item.remark}) </foreach> ON DUPLICATE KEY UPDATE id = values(id), agent = values(agent), enterprise = values(enterprise), operator = values(operator), remark = values(remark) </insert>
根据集合加入信息,如果 数据重复-ON DUPLICATE KEY UPDATE(唯一索引)则执行更新
4)SQL的事件调度器
(例子1): 定时删除15天前的数据
1.首先需要查看是否开启了“事件调度器”
show variables like '%sc%';
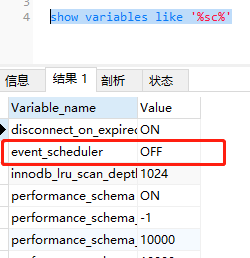
2.开启事件(mysql服务重启后之后失效)
SET GLOBAL event_scheduler = ON; SET GLOBAL event_scheduler = 1; — 1为开启
3.创建事件
DELIMITER $$ DROP EVENT IF EXISTS 事件名; CREATE EVENT 事件名 ON SCHEDULE EVERY 15 DAY STARTS '2022-09-27 17:59:55' ON COMPLETION PRESERVE DO BEGIN delete from 表 where TO_DAYS(now())-TO_DAYS(字段)>15; END$$ DELIMITER ;
4.开启事件
alter event 事件名 on completion preserve enable;
5.关闭事件
alter event 事件名 on completion preserve disable;
6.删除事件
drop event if exists 事件名;
5)动态表名
<update id="unifiedUpdate"> update ${tableName} set approval_status = #{status} where id = #{id} </update>
要注意:#使用预编译,$使用拼接SQL。
当字段为String时,SQL是否需要带引号,$时不带' ',#带' '。防注入也是因为这个原因
Mybatis的SQL注入 : https://blog.csdn.net/M983373615/article/details/118696823
6)concat类型
一、concat()函数
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
说明:返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
3、举例:select concat (id, name, score) as 别名 from 表名;
二、concat_ws()函数
1、功能:和concat()一样,但是可以指定分隔符(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
3、举例:select concat ('#',id, name, score) as 别名 from 表名;
三、group_concat()函数
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator分隔符是一个字符串值,缺省为一个逗号。
3、举例:select name,group_concat(id order by id desc separator '#') as 别名 from 表名 group by name;
四、concat_ws()和group_concat()联合使用
题目:查询以name分组的所有组的id和score
举例:select name,group_concat(concat_ws('-',id,score) order by id) as 别名 from 表名 group by name;
在update中使用 case
@Transactional @Modifying @Query(value = " update group_pk_room A \n" + "set people_num = (CASE WHEN ?2 = 1 THEN people_num - 1 ELSE A.people_num END), \n" + "room_num = (CASE WHEN ?2 = 2 THEN room_num - 1 ELSE A.room_num END) \n" + "WHERE id = ?1 ",nativeQuery=true)
EXISTS的一些用法
MySQL中EXISTS的用法 - QiaoZhi - 博客园 (cnblogs.com)
if (position!=null && !StringUtils.isEmpty(position)){
sql.append(" AND exists ( select 1 from course_to_buwei ctb where ctb.buwei_label_id=:position and ctb.course_id=c.id ) ");
params.put("position",position);
}
GROUP BY优化,
GROUP BY 会默认进行一次隐性排序,可以通过 order by NULL,优化查询速度
SELECT course_field_id from course_field_to_course_topic GROUP BY course_field_id order by NULL;
尽量少用DISTINCT ,多用GROUP BY,底层查询速度差不多,但是GROUP BY 可以做COUNT()等一系列函数操作。
select DISTINCT course_field_id from course_field_to_course_topic;
MySQL报错:sql_mode=only_full_group_by 4种解决方法含举例,轻松解决ONLY_FULL_GROUP_BY的报错问题
5.7之后的版本,会出现这种错误。因为SELECT 的字段,没有出现在GROUP BY中。可以通过聚合函数MAX(查询字段),MIN(查询字段),去显示出来。
或者直接修改数据库配置
select @@global.sql_mode;
如果没有出现(ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION)
就去设置就去
SET GLOBAL sql_mode='STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION';

 浙公网安备 33010602011771号
浙公网安备 33010602011771号