Movie相关
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
故事:现在的LVLM只能处理单场景,跨场景中关联实体的能力不行。比如电影中同一个角色在不同场景中出现,现有的LVLM不能把相同角色合并。所以本文提出了一个benchmark衡量跨场景角色对齐能力,并且提了一个简单的base model。
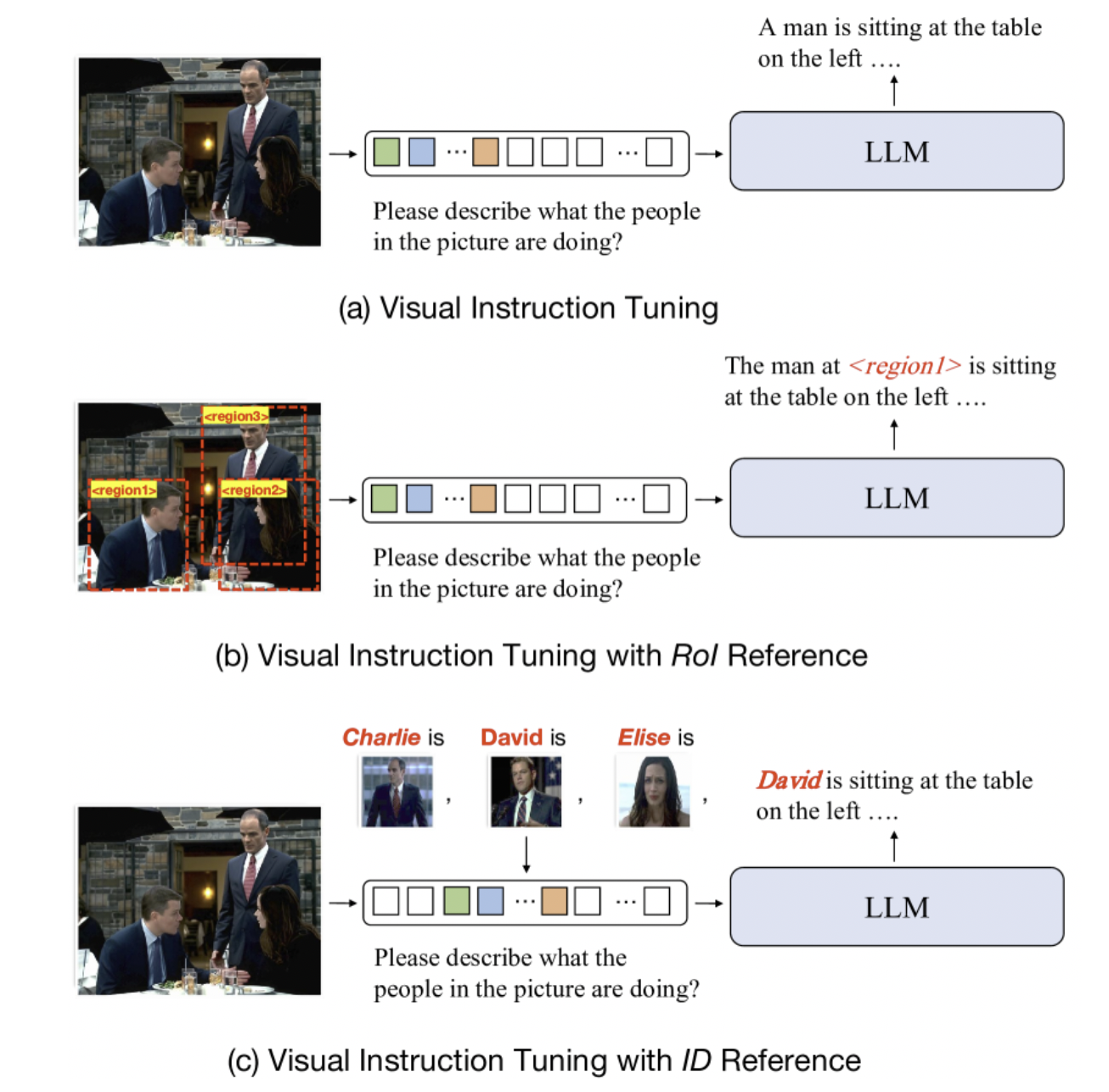
Intro里简单介绍了现有视觉指令调优的方法。普通的只能说出来"A man",加了layout 框的可以说出来"The man at region X",他们的可以把名字对上。
模型结构比较简单:
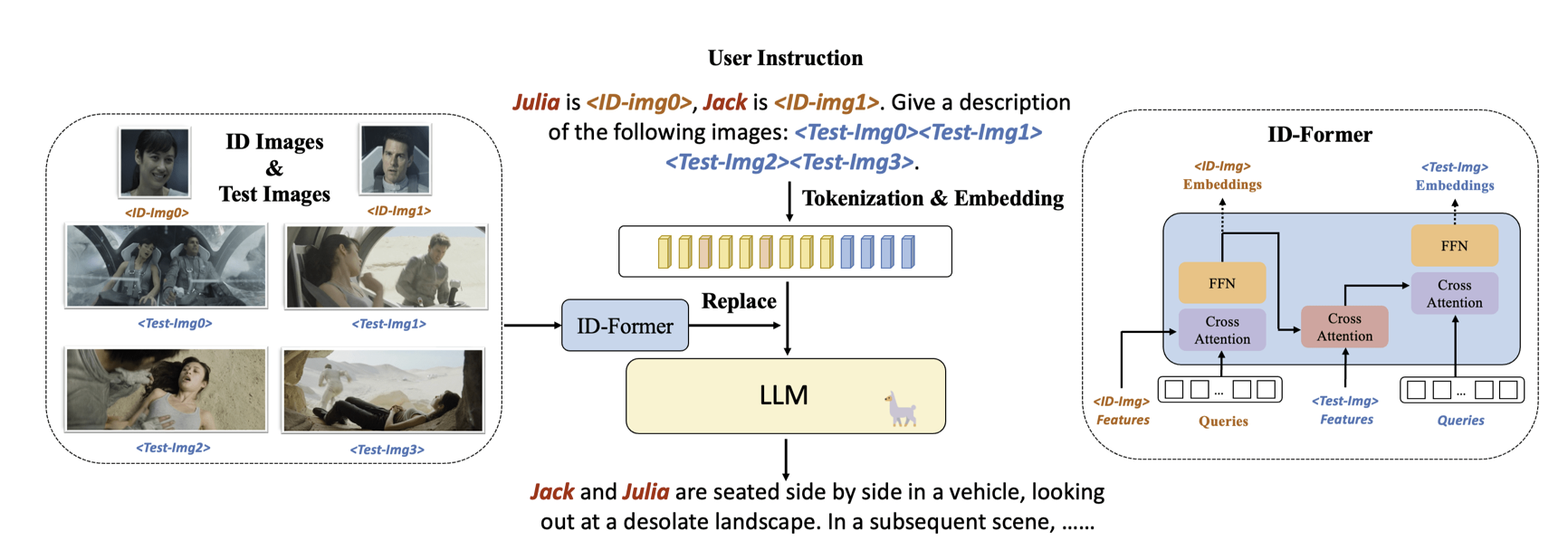
魔改了一下Q-former,把人脸单独拎出来做了个cross attention
额外提了two-stage的训练方法:

stage 1用VCR/RefCoco/Flickr30K的数据集截了里面人物的subgraph,用模板对里面的人物构造QA
stage 2用MovieNet的角色标注把相同角色抽出来用GPT构造QA
stage1的ID-img是Test-img的子图,stage2上了难度
评测上Q&ACaption用的GPT打分,Location用的IoU, Matching用的正确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号