可视化和理解NLP中的神经模型
Visualizing and Understanding Neural Models in NLP
Abstract
虽然神经网络已成功地应用于许多NLP任务,但基于向量的模型是非常难以解释的。例如,人们不清楚它们是如何实现组合性的,即从单词和短语的意义组合起来构建句子的意义。在本文中,我们描述了在NLP的神经模型中可视化组合性的策略,这是受到计算机视觉中类似工作的启发。我们首先画出单位值来可视化否定从句、强化从句和让步从句的组合性,这让我们看到众所周知的否定不对称性(not bad ≠ good)。然后,我们介绍了可视化一个unit的显著性,它的一阶导数是对最终组合意义的贡献。我们的通用方法可能在理解深度网络的组合性和其他语义属性方面有广泛的应用。
Introduction
在这篇文章中,我们探讨了在神经模型中解释意义组合的多种策略。我们引入简单的策略来测量一个神经单元对组合意义的贡献,使用一阶导数来测量它的“显著性”或重要性。
在这项工作中,可视化技术/模型对神经模型如何工作提供了重要的启示:例如,我们说明了LSTM的成功是因为它能够比其他模型更清晰地关注重要的关键词;多句组合更work、模型能够捕获负不对称性,这是自然语言理解中语义组合的一个重要特征;有明显的维度局部性,某些维以一种令人惊讶的local的方式标记否定和量化。虽然我们的尝试只触及神经模型的表面问题,而且每种方法都有其优点和缺点,但总的来说,它们可能为基于语言的任务中的神经模型行为提供一些见解,为理解它们如何在自然语言处理中实现意义组合迈出了第一步。
下一节将介绍一些视觉和NLP中的可视化模型,它们启发了本文的工作。我们在第3节描述数据集和采用的神经模型。不同的可视化策略和相应的分析结果分别在第4、5、6节中给出,然后是一个简短的结论。
A Brief Review of Neural Visualization
相似度通常是通过将嵌入空间投射到二维空间中来图形化的,相似的词倾向于聚集在一起。有人试图从静态的角度解释RNN模型。
在视觉领域,解释和可视化神经模型的方法已经得到了更大的探索,特别是卷积神经网络。卷积神经网络可视化技术主要包括映射网络的不同层返回到最初的图像输入,从而捕获它们在输入中表示的人类可解释的信息,以及这些层中的单元如何对任何最终决策做出贡献。这些方法包括
- Inversion:通过训练一个额外的模型,将不同神经级别的输出投影回初始输入图像,来反转表示。重构背后的直觉是,可以从当前表示进行重构的像素就是表示的内容。反向算法允许当前表示与原始图像的相应部分对齐。
- BP:错误从输出层传回到每一中间层,最后传回原始图像输入。反卷积网络的工作方式与此类似,它将输出一层一层地投影回初始输入,每一层都与一个监督模型相关联,以便将上一层投影到下一层。这些策略使发现活跃区域或对最终分类决策贡献最大的区域成为可能。
- Generation:通过已经训练好的网络模型]生成图片。模型从一幅图像开始,其像素在每一步都被随机初始化和变异。在图像构建的不同阶段被激活的特定层可以帮助解释。
在NLP中,词作为基本单位,因此(词)向量而不是单个像素是基本单位。单词序列(例如,短语和句子)也以比像素排列更结构化的方式呈现。
Datasets and Neural Models
RNN LSTM BiLSTM
Representation Plotting
局部组合
图1显示了所选单词/短语/句子表示的60d热图向量(也就是把这60维的向量可视化了),强调程度(副词和形容词)和否定。短语或句子的嵌入是通过从预训练模型组合单词表示来实现的。
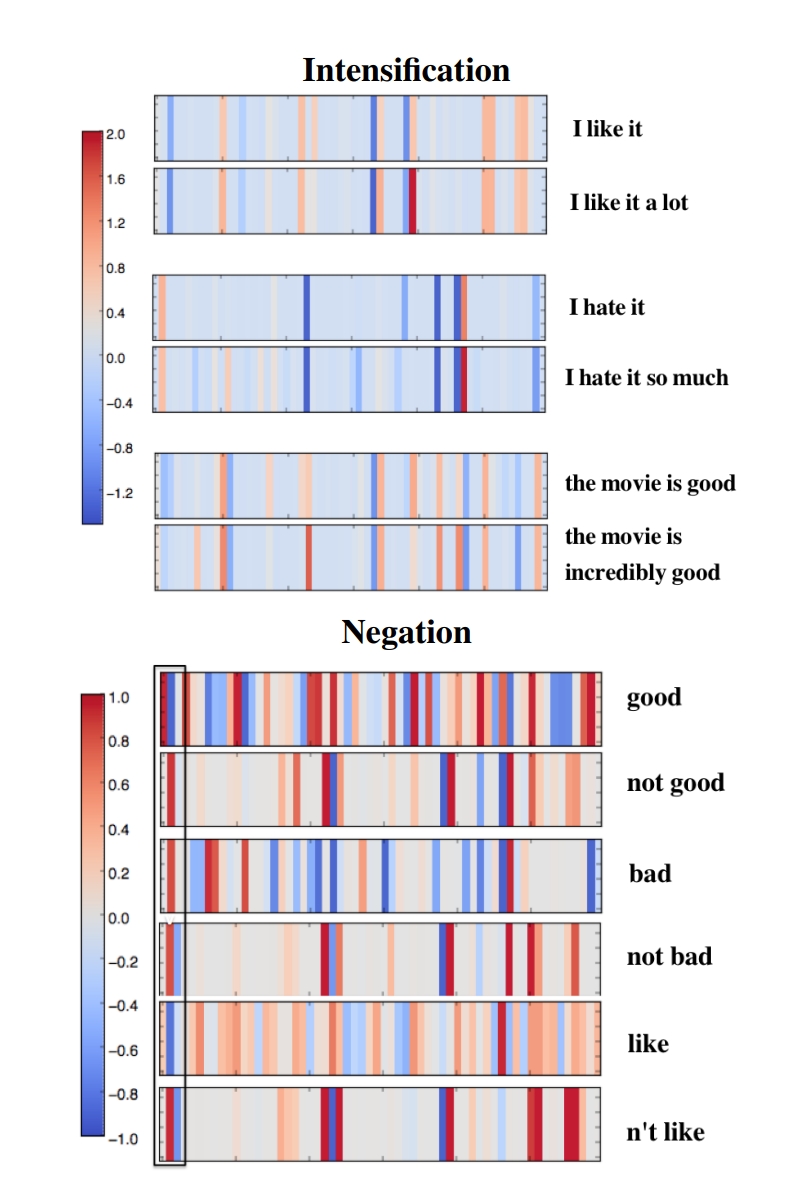
图1:可视化程度和否定。每个竖线显示了组合后最后一个句子/短语表示中的一个维度的值。短语或句子的嵌入是通过从预训练模型组合单词表示来实现的。
图1的程度部分显示了,其中一些维度的值通过修饰语“a lot”(第一个例子中的红色条)、“so much”(第二个例子中的红色条)和“incredibly”来加强。虽然否定的模式不是很清楚,但是对于某些维度仍然有一致的反转,可以看到在左边框起来的维度在蓝色和红色之间的转换。
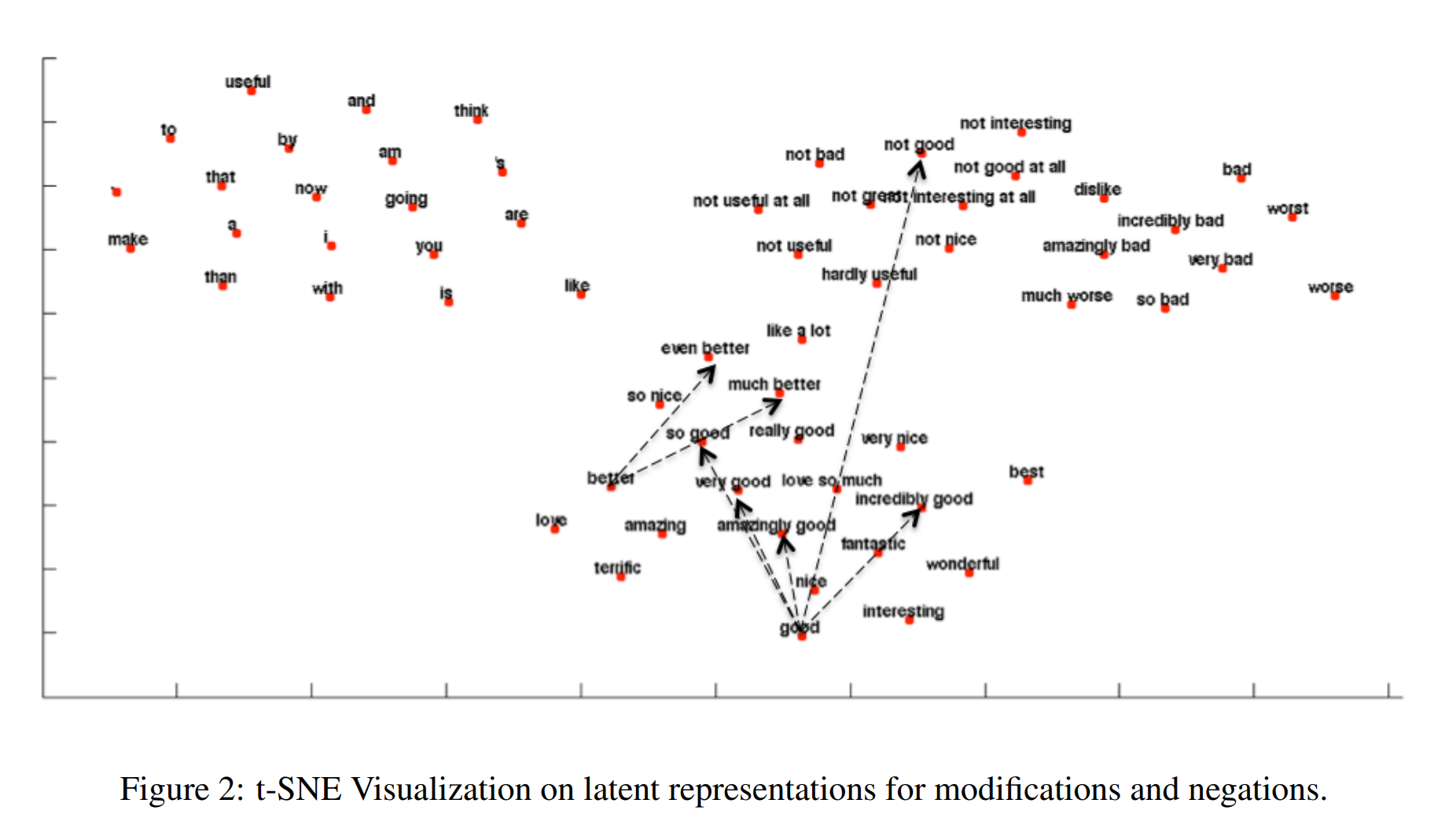
然后,我们在图2中使用t-SNE将单词和短语可视化,并有意添加一些随机单词以作比较。可以看到,神经模型很好地学习了局部组合的属性,发现否定+肯定词("not bad","not good")和消极的词聚类到了一起。也要注意否定的不对称性:“not bad”更多地与否定词聚集在一起,而不是积极词(如图1和2所示)。这表明,尽管该模型似乎确实专注于图1中特定的否定单元,但神经模型不仅学习应用“not”的固定转换,而且能够捕捉不同单词构成的细微差异。
让步句
在让步句中,两个分句具有相反的极性,通常通过与期望相反的含义联系起来。我们绘制了图3中两个让步的随时间变化的表示。
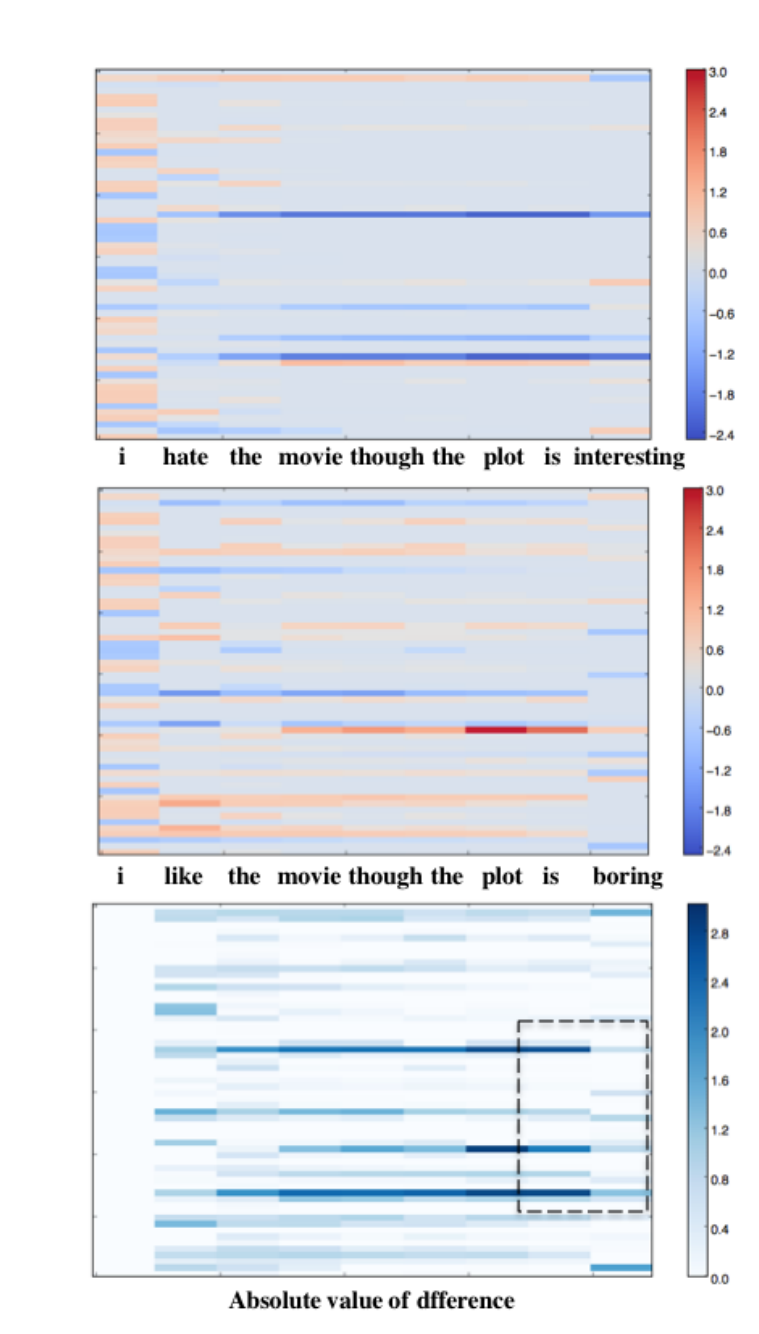
图3:lstm随时间变化的表示。每一列对应于LSTM在每个时间的输出(将当前的词嵌入与之前的构建嵌入结合后得到的表示)。列中的每个网格对应于当前时间表示的每个维度。最后一行对应两个序列每一步的绝对差值。
由图可得:
- 对于情绪分析等任务,太大维度导致许多维度非功能性(值接近于0),导致两个相反情绪的句子只在一些维度不同。这可能解释了为什么更多的维度并不一定会导致在这些任务上有更好的表现
- 在有转折的时候,算法倾向于将前后的情感统一起来,结果是彼此削弱。
从句组合

在图4中,我们更详细地研究了从句的组成。通过在简单的“I like the movie”的结尾加上“although it had bad acting”或“but it is too long”等消极从句,表达方式更接近消极情绪区域。相比之下,在否定句中加入让步从句并不会使句子变得积极;“我讨厌X,但是……仍然是非常消极的,和“我讨厌某某”没什么区别。这种差异再次表明,该模型能够捕捉到负不对称。
First-Derivative Saliency
在本节中,我们将介绍另一种策略,它是受到视觉中的反向传播策略的启发。它衡量每个输入单元对最终决策的贡献,可以用一阶导数来近似。
对于一个分类模型,输入 \(E\) 和一个gold-standard类标签 \(c\) 相关联。(根据NLP任务,输入可以是一个词或一个序列的embedding,而标签可以POS标签,情绪标签,下一个单词预测指数等)。给定与类标签 \(c\) 相关联的输入单词的embedding E,训练后的模型将 \((E, c)\) 与得分 \(S_c(E)\) 相关联。目标是决定 \(E\) 的哪个unit对 \(S_c(E)\) 做出最重要的贡献,从而决定选择类标签 \(c\)。
在深度神经模型的情况下,类别分数 \(S_c(e)\) 是一个高度非线性函数。
即:输入 \(E\) ,类别为 \(c\),目标是优化 \(S_c(E)\),在 \(E\) 上加细微噪声后变为 \(e\) ,其得分为 \(S_c(e)\),根据一阶泰勒展开, 计算为
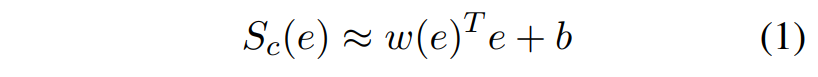
其中 \(w(e)\) 是 \(S_c\) 对embedding \(e\) 的导数。
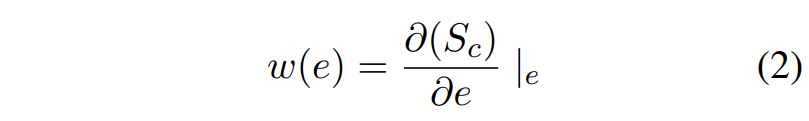
导数的大小(绝对值)表示最终决策对某一特定维度变化的敏感性,告诉我们单词embedding的某个特定维度对最终决策的贡献有多大。显著性得分
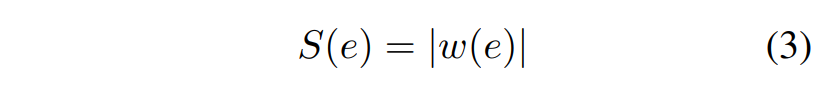
Results on Stanford Sentiment Treebank
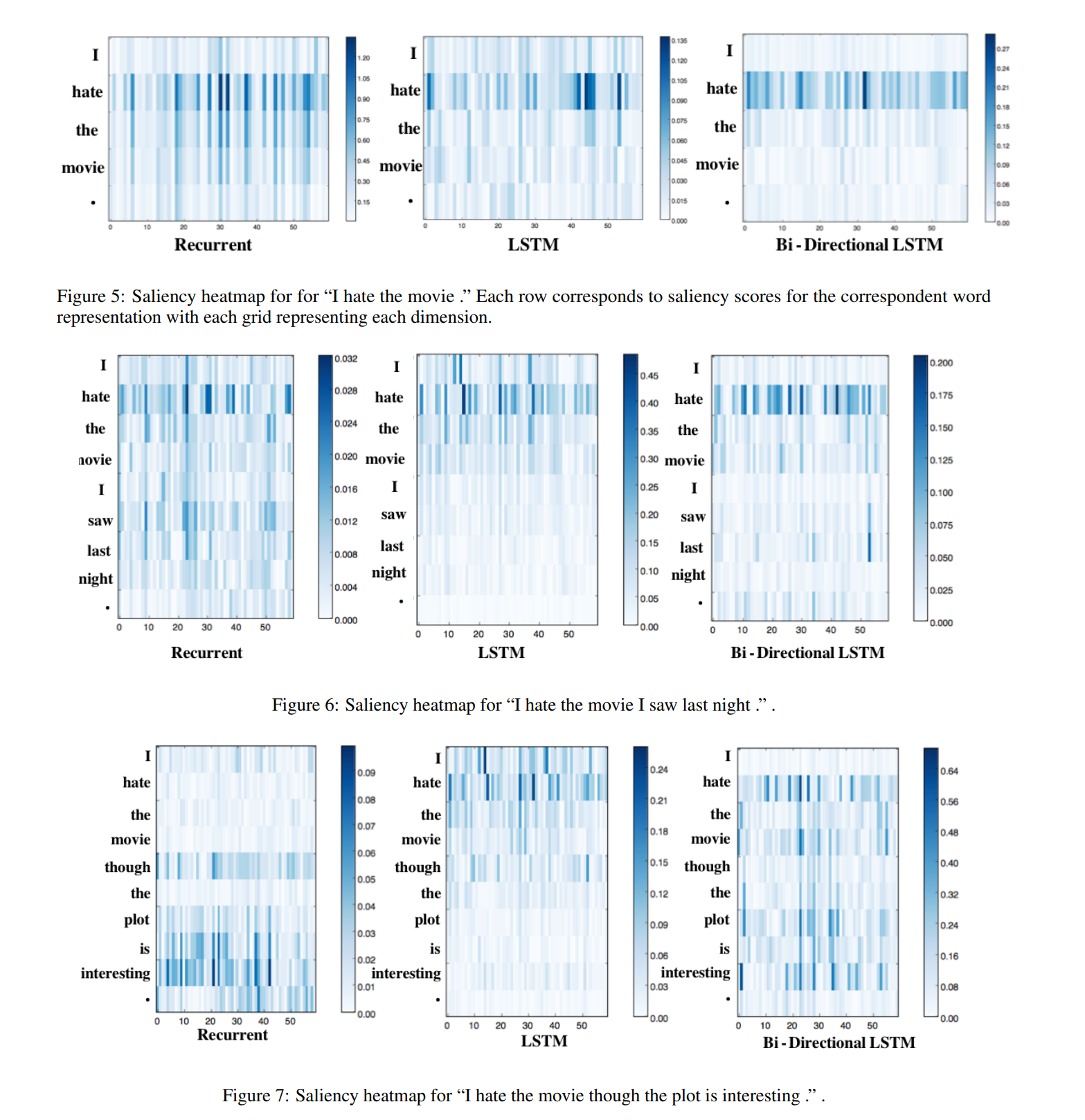
对于这三句话,将训练后的模型应用于每句话。每一行对应单词表示的显著性得分,每个竖着的格代表每个维度。这些例子是基于明确的情绪指标“hate”给他们带来负面情绪。
“I hate the movie”
这三个模型都对“hate”赋予了高度的显著性,并抑制了其他符号的影响。LSTM比标准的循环模型更清晰地关注于“hate”,但双向LSTM显示了最清晰的focus,几乎没有强调除了“hate”之外的其他词。这可能是由于LSTM和bi - LSTM控制信息流的中的门结构,使得这些体系结构能够更好地过滤掉不太相关的信息。
“I hate the movie that I saw last night”
这三个模型都给出了正确的情绪。简单的RNN模型在过滤不相关信息方面同样表现不佳,给与情感无关的词语赋予了太多的关注度。然而,尽管这句话变长了,所有模型都没有出现梯度消失的问题;经过7-8次卷积运算后,“hate”的显著性仍然很明显。
“I hate the movie though the plot is interesting”
RNN模型只强调第二句“the plot is interesting”,而不强调第一句“I hate the movie”。这似乎是由梯度消失引起的,但模型正确地将句子归类为消极的句子,这表明它成功地整合了第一个消极从句的信息。我们单独测试了“though the plot is interesting”。RNN模型将其标记为正。因此,尽管第一个小句中的单词显著性得分较低,但RNN设法依赖该小句并淡化来自后一个积极小句的信息——尽管后一个词的显著性得分较高。这说明了显著性可视化的局限性。一阶导数并不能捕捉到我们想要看到的所有信息,这可能是因为它们只是一个粗略的近似,可能不足以处理高度非线性的情况。相比之下,LSTM强调第一个子句,大大削弱了第二个子句的影响,而Bi-LSTM既强调“hate the movie”,又强调“plot is interesting”。
Results on Sequence-to-Sequence Autoencoder
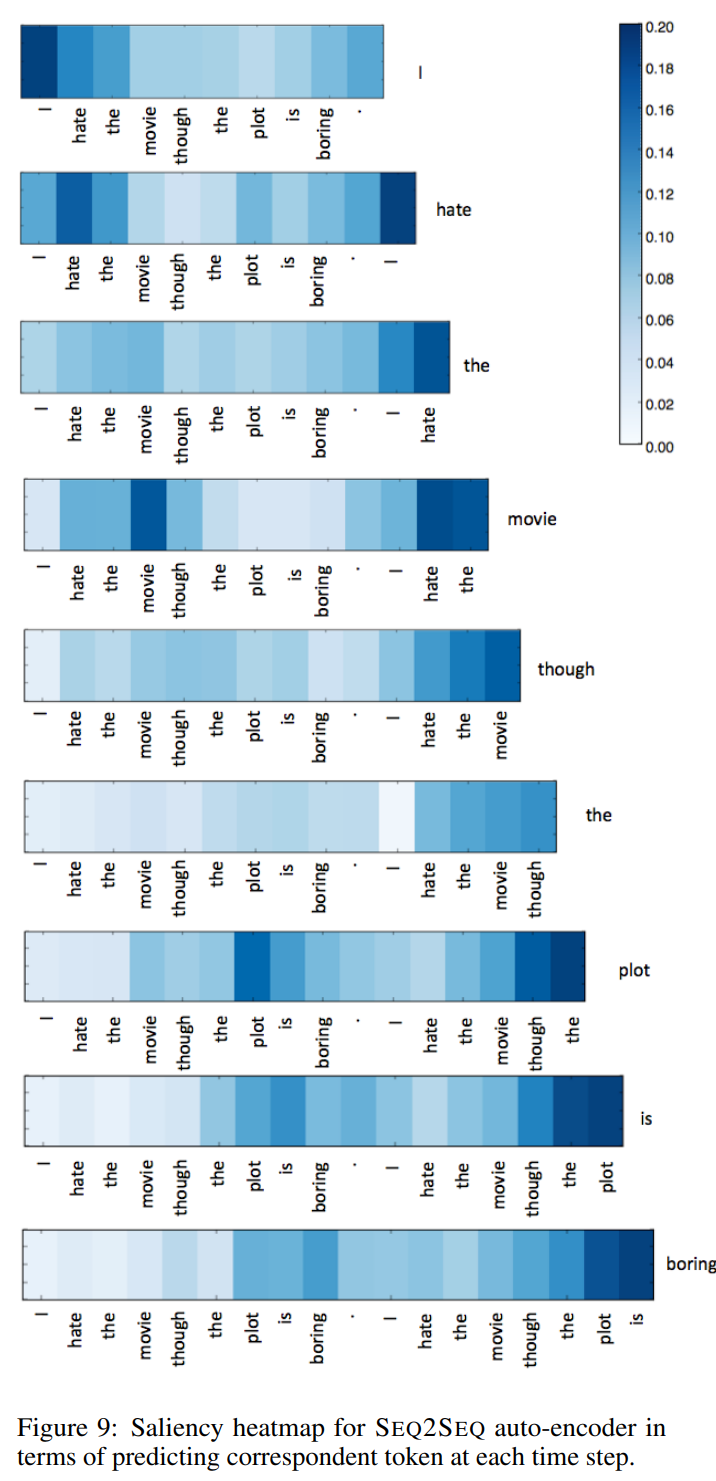
图9为seq2seq auto-encoder在每个时间步中预测对应token的显著性热图。当解码进行时,我们通过反向传播计算前一个单词的一阶导数。每个网格对应于每个1000维字向量的平均显著值的大小。热图清楚地概述了解码过程中神经模型的行为。观察结果可归纳如下:
- 在预测词时会更多的考虑输入中上下文词
- 解码时会依赖已经解码的词,并且随着预测的词愈多,已预测词的作用愈多,说明更依赖语言模型。
Average and Variance
对于将单词embedding作为从头开始优化的参数(与使用预训练的embedding相反)的设置,我们提出了一个可视化的指标。我们首先计算句子中所有单词的单词embedding的平均值。衡量一个词的显著性的标准是它对这个平均值的偏离。其想法是,在训练过程中,模型将学会呈现不同于非指示词的指示词,使它们即使在许多层计算之后也能脱颖而出。
图8显示了方差的映射;每个网格对应的值为\(||e_{i,j}-\frac{1}{N_S}\Sigma_{i'\in N_S} e_{i',j}||^2\) ,其中\(e_{i,j}\) 是单词i的第j维,N是句子里token的数量
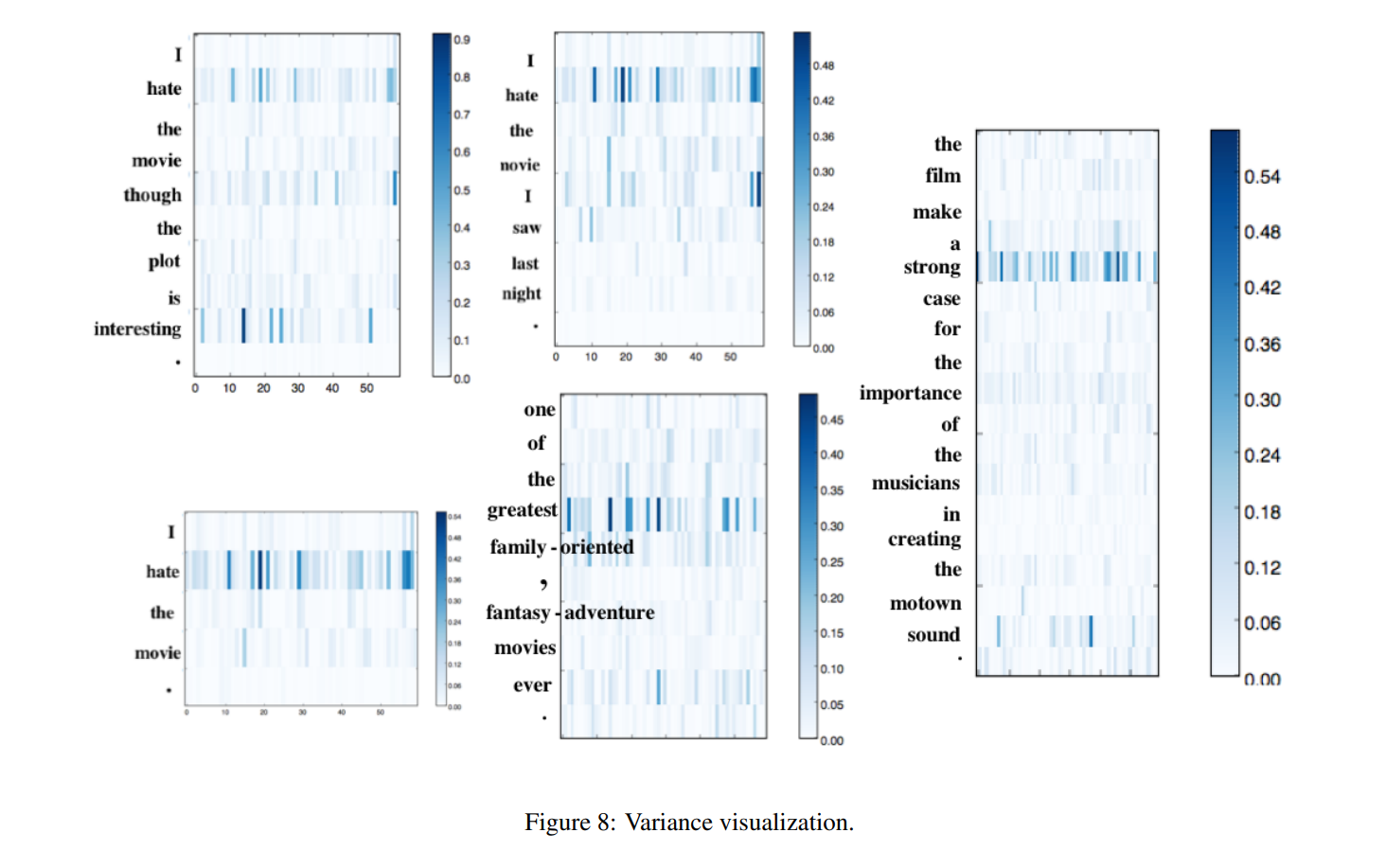
如图所示,基于方差的显著性测量在强调相关情感词方面也做得很好。该模型也有不足之处:
- 它只能用于将单词embedding作为学习参数的场景
- 很明显,该模型不能够很好地可视化局部组成。
Conclusion
在本文中,我们提供了几种方法来帮助可视化和解释神经模型,以理解神经模型如何能够组成含义,证明否定的不对称性,并解释lstm在这些任务中的某些方面的强表现。
虽然我们的尝试只触及神经模型的表面问题,而且每种方法都有其优点和缺点,但总的来说,它们可能为基于语言的任务中的神经模型行为提供一些见解,为理解它们如何在自然语言处理中实现意义组合迈出了第一步。我们未来的工作包括使用可视化的结果进行错误分析,并了解不同神经模型的强度限制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号