Spark RPC通讯环境初始化源码分析
概述
spark在2.0前使用的scala的akka框架实现的rpc,由于很多用户会使用Akka做消息传递,会和Spark内嵌的版本产生冲突,所以在spark2.0以后通过netty实现了一个类似akka的actor模型替换akka成为spark的rpc通讯层;
Driver端通讯环境初始化
SparkContext
Driver端在初始化SparkContext时就会在构造方法中初始化SparkEnv初始化spark rpc的通讯环境;
...
private var _env: SparkEnv = _
...
_env = createSparkEnv(_conf, isLocal, listenerBus)
...
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master, conf))
}
...
SparkEnv
private[spark] def createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
...
create(
conf,
SparkContext.DRIVER_IDENTIFIER,
bindAddress,
advertiseAddress,
Option(port),
isLocal,
numCores,
ioEncryptionKey,
listenerBus = listenerBus,
mockOutputCommitCoordinator = mockOutputCommitCoordinator
)
}
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Option[Int],
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
...
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf,
securityManager, numUsableCores, !isDriver)
...
}
NettyRpcEnv
在SparkEnv层层调用,最终会通过RpcEnv的create方法来创建rpc通讯环境;
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config)
}
RpcEnv的create方法通过实例化NettyRpcEnvFactory来创建rpc环境,从名字我们就能看出spark底层的通讯框架是通过netty实现的;
NettyRpcEnvFactory是NettyRpcEnv的工厂类,实现了RpcEnvFactory特质,uml图如下:
NettyRpcEnvFactory的create方法如下:
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf
val javaSerializerInstance =
new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance]
// 初始化NettyRpcEnv
val nettyEnv =
new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) {
// NettyRpcEnv启动方法
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
// 启动工具类
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
NettyRpcEnvFactory的create方法会new一个NettyRpcEnv类实例,定义NettyRpcEnv启动方法startNettyRpcEnv,最后通过Utils的startServiceOnPort方法调用startNettyRpcEnv来启动NettyRpcEnv;
Utils的startServiceOnPort方法主要作用是尝试在指定端口启动,启动失败即在失败端口上+1继续尝试;
NettyRpcEnv实现了RpcEnv抽象类,通过实现RpcEnv抽象类及实现了RpcEnvFactory特质可以很方便更换spark底层通讯框架;
NettyRpcEnv uml图如下(可能是由于idea对于scala语言支持不佳,导致生成uml图丢失了继承关系,实际上NettyRpcEnv与RpcEnv是继承关系,uml图比较简单所以笔者也就没重新画了):
在NettyRpcEnv的构造方法中,初始化了两个非常重要的类
// 消息分发器初始化
private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores)
// 将dispatcher包装成NettyRpcHandler,用以将接收到的请求再次交给dispatcher处理
private val transportContext = new TransportContext(transportConf, new NettyRpcHandler(dispatcher, this, streamManager))
在startNettyRpcEnv方法中,会通过调用startServer启动服务,startServer方法源码如下:
def startServer(bindAddress: String, port: Int): Unit = {
val bootstraps: java.util.List[TransportServerBootstrap] =
if (securityManager.isAuthenticationEnabled()) {
java.util.Arrays.asList(new AuthServerBootstrap(transportConf, securityManager))
} else {
java.util.Collections.emptyList()
}
server = transportContext.createServer(bindAddress, port, bootstraps)
// 向消息分发器注册Endpoint
dispatcher.registerRpcEndpoint(
RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher))
}
RpcEndpoint
RpcEndpoint是一个可以响应请求的服务,在RpcEndpoint中定义了一系列生命周期函数:onStart()、receive*、onStop()、onConnected(remoteAddress: RpcAddress)、onDisconnected(remoteAddress: RpcAddress)分别会在rpc开启、收到消息、rpc停止、连接建立、连接断开被调用;
RpcEndpointRef
故名思意,RpcEndpointRef是RpcEndpoint的引用,用于发起请求,主要方法有send、ask*,send主要用于发送无返回的请求,而ask*用于发送有返回的请求;
NettyRpcHandler
在NettyRpcHandler中,接收到请求会调用dispatcher的postRemoteMessage方法,将请求包装再次交给dispatcher处理并分发;
override def receive(
client: TransportClient,
message: ByteBuffer,
callback: RpcResponseCallback): Unit = {
val messageToDispatch = internalReceive(client, message)
dispatcher.postRemoteMessage(messageToDispatch, callback)
}
override def receive(
client: TransportClient,
message: ByteBuffer): Unit = {
val messageToDispatch = internalReceive(client, message)
dispatcher.postOneWayMessage(messageToDispatch)
}
Dispatcher
上面说Dispatcher是个非常重要的类,具体我们来看看它是如何重要的;
Dispatcher构造方法中的四个重要变量:
// RpcEndpoint map
private val endpoints: ConcurrentMap[String, EndpointData] =
new ConcurrentHashMap[String, EndpointData]
// RpcEndpointRef map
private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] =
new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]
// 接收到的消息
private val receivers = new LinkedBlockingQueue[EndpointData]
// 定义了一个线程池,用于处理接收到的消息
private val threadpool: ThreadPoolExecutor = {
val availableCores =
if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, availableCores))
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}
map的泛型值类型EndpointData类定义如下:
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
Inbox译为收件箱,顾名思义就是处理接收到的消息的,接下来我们看看到底是如何处理去处理接收到消息的;
在上面NettyRpcHandler分析中,可以发现,接收到请求会交给Dispatcher的postOneWayMessage方法处理,postOneWayMessage源码如下
def postOneWayMessage(message: RequestMessage): Unit = {
postMessage(message.receiver.name, OneWayMessage(message.senderAddress, message.content),(e) => throw e)
}
private def postMessage(
endpointName: String,
message: InboxMessage,
callbackIfStopped: (Exception) => Unit): Unit = {
val error = synchronized {
val data = endpoints.get(endpointName)
if (stopped) {
Some(new RpcEnvStoppedException())
} else if (data == null) {
Some(new SparkException(s"Could not find $endpointName."))
} else {
data.inbox.post(message)
receivers.offer(data)
None
}
}
error.foreach(callbackIfStopped)
}
可以看到在Dispatcher中会从RpcEndpoint map去拿对应的EndpointData,并将获取到的EndpointData放入receivers map中;
在Inbox的post方法中仅仅只是将消息存放在一个list中,并未处理,具体源码如下:
protected val messages = new java.util.LinkedList[InboxMessage]()
def post(message: InboxMessage): Unit = inbox.synchronized {
if (stopped) {
// We already put "OnStop" into "messages", so we should drop further messages
onDrop(message)
} else {
messages.add(message)
false
}
}
那消息是在什么时候被处理的呢?还记得我们上面说到的Dispatcher初始化时在构造函数中初始化的四个重要变量么,消息是在Dispatcher初始化时创建的线程池时提交了个MessageLoop任务,消息就是在MessageLoop中被处理的,具体方法源码如下:
override def run(): Unit = {
try {
while (true) {
try {
val data = receivers.take()
if (data == PoisonPill) {
receivers.offer(PoisonPill)
return
}
data.inbox.process(Dispatcher.this)
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
...
}
}
可以看到,在线程池中提交的MessageLoop任务在不断从receivers获取任务,并调用Inbox的process方法去处理接收到的消息的;
在Inbox的process方法中,通过调用Inbox包装的RpcEndpoint的对应方法完成消息的处理,上面说的RpcEndpoint的生命周期函数也会在这里被调用:
def process(dispatcher: Dispatcher): Unit = {
...
while (true) {
safelyCall(endpoint) {
message match {
case RpcMessage(_sender, content, context) =>
...
case OneWayMessage(_sender, content) =>
...
case OnStart =>
...
case OnStop =>
...
case RemoteProcessConnected(remoteAddress) =>
...
case RemoteProcessDisconnected(remoteAddress) =>
...
case RemoteProcessConnectionError(cause, remoteAddress) =>
...
}
}
}
...
}
RpcEndpoint map中的EndpointData是通过Dispatcher的registerRpcEndpoint方法注册的,registerRpcEndpoint方法源码如下:
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data) // for the OnStart message
}
endpointRef
}
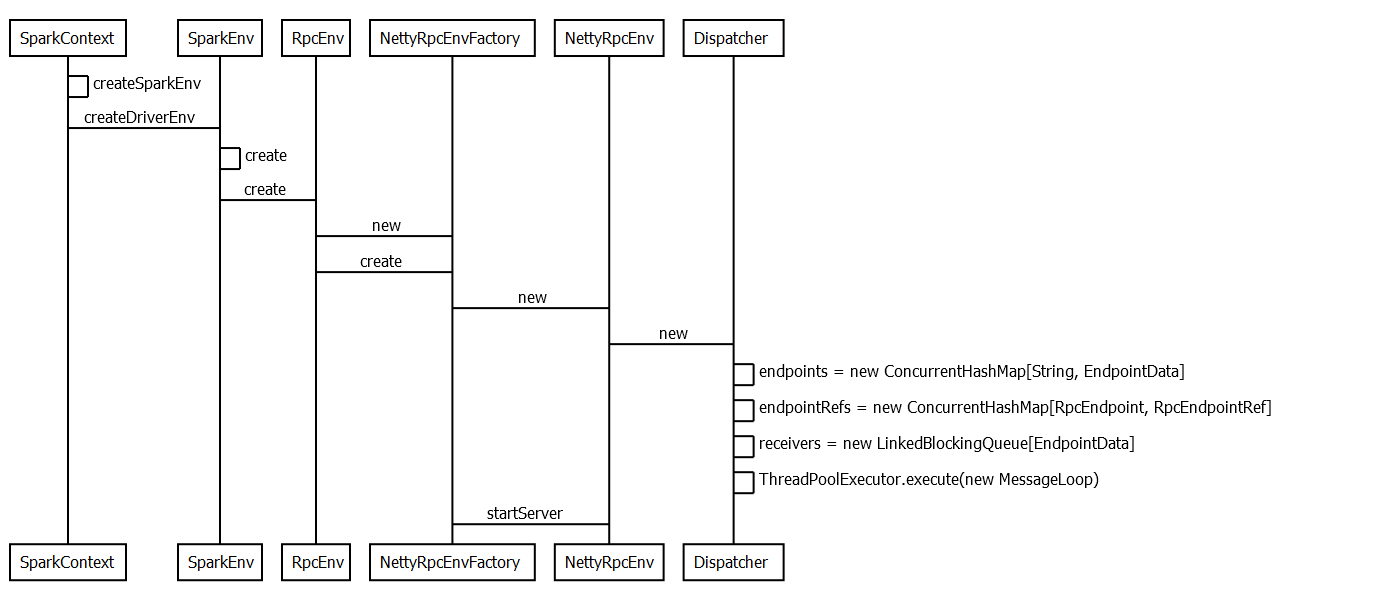
至此,driver端rpc环境初始化已经分析完毕,初始化时序图如下:
Executor端通讯环境初始化
Executor端通讯环境初始化,大部分都是和Driver端一样的,只是在调用的地方不同而已;
Executor端通讯环境初始化在Executor主类CoarseGrainedExecutorBackend中去调用SparkEnv的createExecutorEnv方法完成的,具体源码如下:
def main(args: Array[String]) {
...
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
System.exit(0)
}
private def run(...) {
...
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
}

