Spark任务提交源码分析
用户端执行
以下是一个以spark on yarn Cluster模式提交命令,本系列文章所有分析都是基于spark on yarn Cluster模式,spark版本:2.4.0
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 512M \
--num-executors 1 \
/opt/cloudera/parcels/CDH/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.3.2.jar
spark-submit是一个shell脚本,其内容如下:
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
spark-submit提交的参数最终都会通过exec命令调用org.apache.spark.deploy.SparkSubmit传入。
SparkSubmit类
main方法
SparkSubmit的main方法在其伴生类中,源码简略版如下:
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
self =>
override protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
...
}
override protected def logInfo(msg: => String): Unit = printMessage(msg)
override protected def logWarning(msg: => String): Unit = printMessage(s"Warning: $msg")
override def doSubmit(args: Array[String]): Unit = {
...
super.doSubmit(args)
...
}
}
submit.doSubmit(args)
}
可以看到,在main方法中,通过调用SparkSubmit类的doSubmit方法实现任务提交的,doSubmit方法如下:
def doSubmit(args: Array[String]): Unit = {
...
val appArgs = parseArguments(args)
...
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
在doSubmit方法中,解析spark-submit命令提交的参数后,通过模式匹配实现不同命令走不同方法的,而我们上面的命令是submit,所以到这里执行的是submit方法。
submit方法
submit源码简略如下:
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
// 参数解析,拿到执行的childMainClass值
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
// 执行runMain方法
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
})
} catch {
...
}
} else {
// 执行runMain方法
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
}
if (args.isStandaloneCluster && args.useRest) {
try {
doRunMain()
} catch {
...
}
} else {
doRunMain()
}
}
可以看到submit方法中,主要是解析用户提交的参数,然后执行doRunMain,通过doRunMain方法执行runMain方法,
这样做的原因是:在执行runMain方法前做了一次判断,判断是不是StandaloneCluster模式,
如果是StandaloneCluster模式,在任务提交时,有两种提交方式,一种是用org.apache.spark.deploy.Client包装后通过传统的rpc方式提交,
另一种是spark1.3以后引入的rest方式提交,而rest方式提交是spark1.3以后StandaloneCluster模式的默认提交方式,
而如果master不支持rest模式则会报错,在这里做了一个判断,在报错后会通过传统rpc的方式去调用。
参数解析prepareSubmitEnvironment方法中,有一段重要的代码如下:
...
private[deploy] val YARN_CLUSTER_SUBMIT_CLASS =
"org.apache.spark.deploy.yarn.YarnClusterApplication"
...
private[deploy] def prepareSubmitEnvironment(...)
: (Seq[String], Seq[String], SparkConf, String) = {
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
...
}
...
(childArgs, childClasspath, sparkConf, childMainClass)
}
这段代码的作用是判断当前模式是不是YarnCluster模式,是YarnCluster模式的话,则将“org.apache.spark.deploy.yarn.YarnClusterApplication”赋值给变量“childMainClass”;
而在prepareSubmitEnvironment方法外,submit中可以看到,childMainClass变量的值通过模式匹配拿到后传给了runMain方法;
runMain方法
runMain方法源码如下:
private def runMain(...): Unit = {
...
var mainClass: Class[_] = null
try {
// 通过反射拿到YarnClusterApplication类
mainClass = Utils.classForName(childMainClass)
} catch {
...
}
// 判断拿到的mainClass类是不是SparkApplication的子类,是SparkApplication的子类就实例化mainClass,不是的话则通过JavaMainApplication包装一下mainClass
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
...
new JavaMainApplication(mainClass)
}
...
try {
app.start(childArgs.toArray, sparkConf)
} catch {
...
}
}
runMain方法中,主要是通过反射去拿到参数childMainClass的class,而childMainClass正是我们前面的“org.apache.spark.deploy.yarn.YarnClusterApplication”类,而YarnClusterApplication是实现了SparkApplication特质的;
最后拿到了YarnClusterApplication的实例后调用YarnClusterApplication的start方法。
YarnClusterApplication类
start方法
YarnClusterApplication的start方法很简单,源码如下:
override def start(args: Array[String], conf: SparkConf): Unit = {
new Client(new ClientArguments(args), conf).run()
}
Client类
Client是spark任务提交在提交用户的计算机上跑的最后一个类,Client完成了与hadoop yarn通信并提交application master的任务。
在Client类的构造函数中,实例化了yarn的client,以及获取到了amMemory等诸多的参数;
Client的构造函数中重要参数初始化如下:
private val yarnClient = YarnClient.createYarnClient
private val hadoopConf = new YarnConfiguration(SparkHadoopUtil.newConfiguration(sparkConf))
private val isClusterMode = sparkConf.get("spark.submit.deployMode", "client") == "cluster"
private val amMemory = if (isClusterMode) {
sparkConf.get(DRIVER_MEMORY).toInt
} else {
sparkConf.get(AM_MEMORY).toInt
}
private val amMemoryOverhead = {
val amMemoryOverheadEntry = if (isClusterMode) DRIVER_MEMORY_OVERHEAD else AM_MEMORY_OVERHEAD
sparkConf.get(amMemoryOverheadEntry).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * amMemory).toLong, MEMORY_OVERHEAD_MIN)).toInt
}
private val amCores = if (isClusterMode) {
sparkConf.get(DRIVER_CORES)
} else {
sparkConf.get(AM_CORES)
}
private val executorMemory = sparkConf.get(EXECUTOR_MEMORY)
private val executorMemoryOverhead = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toLong, MEMORY_OVERHEAD_MIN)).toInt
run方法
run方法源码如下:
def run(): Unit = {
this.appId = submitApplication()
...
}
run方法主要是通过调用Client类的submitApplication方法获取到应用的appId,而主要的提交方法都在submitApplication方法中;
submitApplication方法
submitApplication方法的源码如下:
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
launcherBackend.connect()
// yarn client启动
yarnClient.init(hadoopConf)
yarnClient.start()
// 向yarn申请唯一的app id
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
...
// yarn提交的容器命令准备
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
...
// 容器提交
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
appId
} catch {
...
}
createContainerLaunchContext方法
createContainerLaunchContext的主要源码如下:
private def createContainerLaunchContext(...) : ContainerLaunchContext = {
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
...
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file", buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE))
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
val securityManager = new SecurityManager(sparkConf)
amContainer.setApplicationACLs(
YarnSparkHadoopUtil.getApplicationAclsForYarn(securityManager).asJava)
setupSecurityToken(amContainer)
amContainer
}
从上面的源码可以看到,createContainerLaunchContext方法主要是把“/bin/java -server + javaOpts + amArgs”组成commands包装成amContainer提交给了yarn;
而amArgs参数通过上面源码可以发现在ClusterMode下是:org.apache.spark.deploy.yarn.ApplicationMaster,在ClientMode下是:org.apache.spark.deploy.yarn.ExecutorLauncher
本文仅讨论ClusterMode模式,至此,ClusterMode模式下所有在提交任务的用户的计算机上运行的代码全部以及跑完,下面的所有的代码全部运行在yarn的容器中。
方法执行时序图
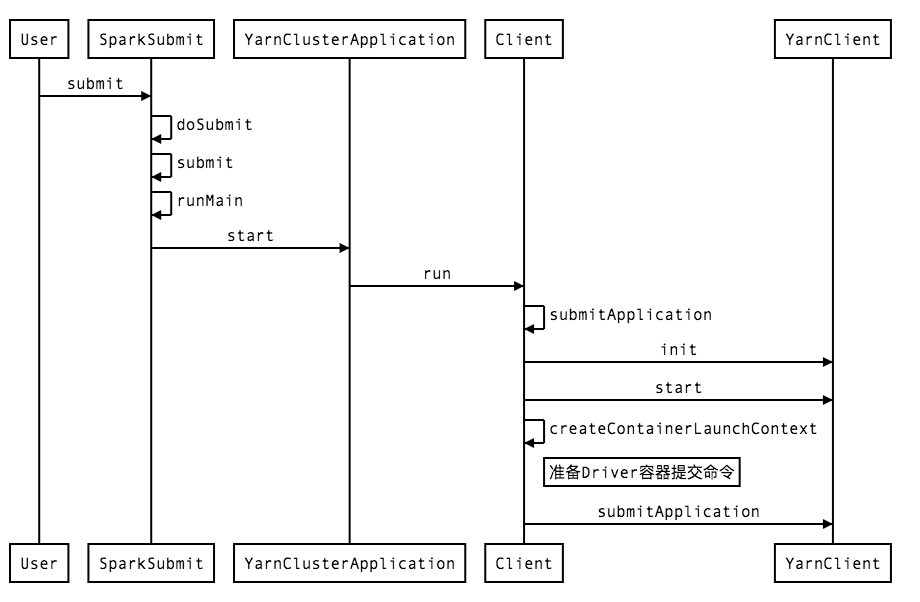
Driver
ApplicationMaster类
main方法
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
master = new ApplicationMaster(amArgs)
System.exit(master.run())
}
run方法
final def run(): Int = {
doAsUser {
runImpl()
}
exitCode
}
runImpl方法
runImpl方法关键代码如下:
private def runImpl(): Unit = {
try {
val appAttemptId = client.getAttemptId()
var attemptID: Option[String] = None
...
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
} catch {
...
} finally {
...
}
}
ApplicationMaster类中,层层调用,main中实例化一个ApplicationMaster对象,然后在调用ApplicationMaster的run方法,run方法通过runImpl实现;
在runImpl方法中,判断了一下是不是ClusterMode,是ClusterMode的话调用runDriver,Client模式的话调用runExecutorLauncher;
本文讨论ClusterMode模式。
runDriver方法
private def runDriver(): Unit = {
// 执行用户提交的main方法
userClassThread = startUserApplication()
...
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
rpcEnv = sc.env.rpcEnv
...
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
// 获取容器,并运行Executor
createAllocator(driverRef, userConf)
} else {
...
}
resumeDriver()
userClassThread.join()
} catch {
...
} finally {
resumeDriver()
}
}
在runDriver方法中,通过调用startUserApplication方法来创建一个线程执行用户程序的main方法,同时会通过createAllocator方法向yarn申请资源并运行Executor
startUserApplication方法
private def startUserApplication(): Thread = {
var userArgs = args.userArgs
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
val userThread = new Thread {
override def run() {
try {
if (!Modifier.isStatic(mainMethod.getModifiers)) {
logError(s"Could not find static main method in object ${args.userClass}")
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_EXCEPTION_USER_CLASS)
} else {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running user class")
}
} catch {
...
} finally {
...
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}
在startUserApplication方法中,首先会去解析参数,拿到我们在提交命令中的“--class”指定的类,然后判断该类是否有参数为“Array[String]”的静态“main”方法,即Scala/Java程序的入口函数,随后会在一个名为“Driver”的线程中通过反射执行用户程序的main方法,至此,我们通过源码分析的方式知道了我们常说的“Driver”实际上是一个用来执行用户程序名为“Driver”的线程。
执行用户程序的main方法时会初始化SparkContext,初始化SparkContext时在其构造函数中,会创建TaskScheduler,然后调用TaskScheduler的postStartHook()方法将SparkContext自身又返回给到ApplicationMaster中,方便后续的调用,源码如下:
// SparkContext init
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
......
_taskScheduler.postStartHook()
// YarnClusterScheduler
override def postStartHook() {
ApplicationMaster.sparkContextInitialized(sc)
super.postStartHook()
logInfo("YarnClusterScheduler.postStartHook done")
}
// ApplicationMaster
private[spark] def sparkContextInitialized(sc: SparkContext): Unit = {
master.sparkContextInitialized(sc)
}
private def sparkContextInitialized(sc: SparkContext) = {
sparkContextPromise.synchronized {
// Notify runDriver function that SparkContext is available
sparkContextPromise.success(sc)
// Pause the user class thread in order to make proper initialization in runDriver function.
sparkContextPromise.wait()
}
}
createAllocator方法
createAllocator方法是Driver用于向yarn通信申请资源并在申请的容器中运行Executor,接下来我们看看他是如何实现的,由于createAllocator方法中的调用栈太深,所以精简下createAllocator方法的调用,createAllocator方法的简略源码如下:
private def createAllocator(driverRef: RpcEndpointRef, _sparkConf: SparkConf): Unit = {
val appId = client.getAttemptId().getApplicationId().toString()
val driverUrl = RpcEndpointAddress(driverRef.address.host, driverRef.address.port,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
// 获取YarnAllocator,通过YarnAllocator与yarn通讯
allocator = client.createAllocator(
yarnConf,
_sparkConf,
driverUrl,
driverRef,
securityMgr,
localResources)
credentialRenewer.foreach(_.setDriverRef(driverRef))
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
// 资源申请
allocator.allocateResources()
...
}
def allocateResources(): Unit = synchronized {
updateResourceRequests()
val progressIndicator = 0.1f
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
allocatorBlacklistTracker.setNumClusterNodes(allocateResponse.getNumClusterNodes)
if (allocatedContainers.size > 0) {
...
handleAllocatedContainers(allocatedContainers.asScala)
}
...
}
def handleAllocatedContainers(allocatedContainers: Seq[Container]): Unit = {
// 省略一系列容器校验
...
runAllocatedContainers(containersToUse)
}
private def runAllocatedContainers(containersToUse: ArrayBuffer[Container]): Unit = {
for (container <- containersToUse) {
...
if (runningExecutors.size() < targetNumExecutors) {
numExecutorsStarting.incrementAndGet()
if (launchContainers) {
// 通过线程执行提交Executor的操作
launcherPool.execute(new Runnable {
override def run(): Unit = {
try {
new ExecutorRunnable(
Some(container),
conf,
sparkConf,
driverUrl,
executorId,
executorHostname,
executorMemory,
executorCores,
appAttemptId.getApplicationId.toString,
securityMgr,
localResources
).run() // 实际提交Executor的方法
updateInternalState()
} catch {
...
}
}
})
} else {
updateInternalState()
}
} else {
...
}
}
}
从上面一系列方法可以看到,spark将Executor任务提交分装成了4个步骤,分别是获取yarnClient、与yarn通讯拿到可申请的容器数、容器校验、容器提交;
而运行多少Executor是如何确定的呢?在YarnAllocator类中有个targetNumExecutors值,在初始化YarnAllocator类时就确定了要创建多少个Executor,在runAllocatedContainers方法时会确定running的Executor是否小于targetNumExecutors数,小于的话就会去创建Executor直到等于targetNumExecutors数,targetNumExecutors值确定源码如下:
// YarnAllocator
@volatile private var targetNumExecutors =
SchedulerBackendUtils.getInitialTargetExecutorNumber(sparkConf)
// SchedulerBackendUtils
val DEFAULT_NUMBER_EXECUTORS = 2
def getInitialTargetExecutorNumber(
conf: SparkConf,
numExecutors: Int = DEFAULT_NUMBER_EXECUTORS): Int = {
if (Utils.isDynamicAllocationEnabled(conf)) {
val minNumExecutors = conf.get(DYN_ALLOCATION_MIN_EXECUTORS)
val initialNumExecutors = Utils.getDynamicAllocationInitialExecutors(conf)
val maxNumExecutors = conf.get(DYN_ALLOCATION_MAX_EXECUTORS)
require(initialNumExecutors >= minNumExecutors && initialNumExecutors <= maxNumExecutors,
s"initial executor number $initialNumExecutors must between min executor number " +
s"$minNumExecutors and max executor number $maxNumExecutors")
initialNumExecutors
} else {
conf.get(EXECUTOR_INSTANCES).getOrElse(numExecutors)
}
}
ExecutorRunnable类
run方法
def run(): Unit = {
...
startContainer()
}
def startContainer(): java.util.Map[String, ByteBuffer] = {
...
val commands = prepareCommand()
ctx.setCommands(commands.asJava)
...
try {
nmClient.startContainer(container.get, ctx)
} catch {
...
}
}
在ExecutorRunnable的run方法中我们又看到了熟悉命令准备操作,实际上向yarn提交任务也都是向yarn提交一系列命令实现的;
prepareCommand方法
private def prepareCommand(): List[String] = {
...
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++
Seq("org.apache.spark.executor.CoarseGrainedExecutorBackend",
"--driver-url", masterAddress,
"--executor-id", executorId,
"--hostname", hostname,
"--cores", executorCores.toString,
"--app-id", appId) ++
userClassPath ++
Seq(
s"1>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stdout",
s"2>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stderr")
commands.map(s => if (s == null) "null" else s).toList
}
可以看到,Executor任务实际执行的是“org.apache.spark.executor.CoarseGrainedExecutorBackend”这个类;
至此任务提交所有的Driver的工作已经完成。
方法执行时序图
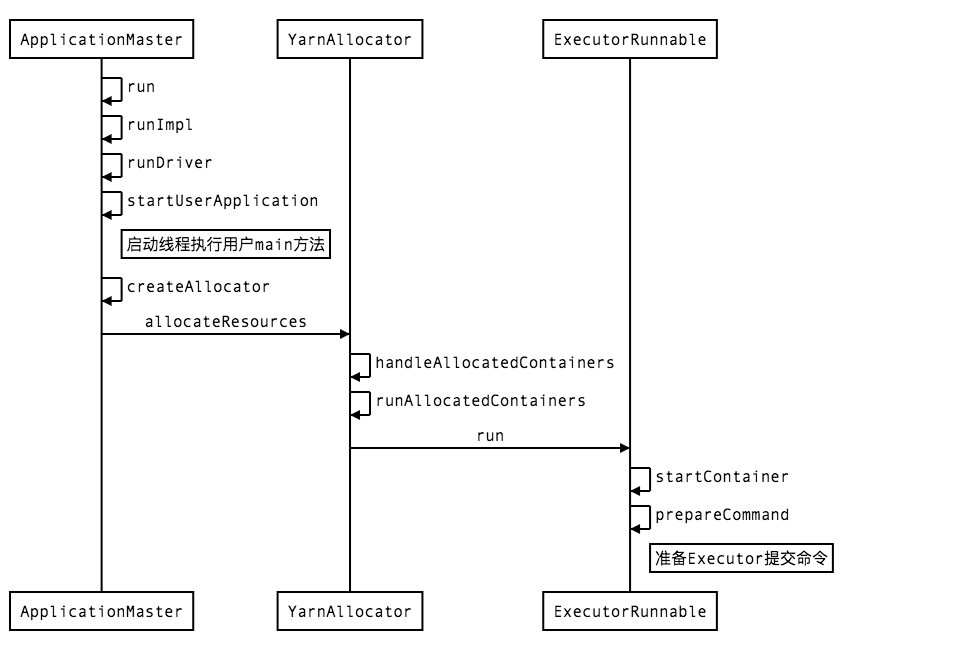
Executor
在上面的Driver分析中,我们发现Driver创建Executor任务实际上是向yarn提交了一个执行“org.apache.spark.executor.CoarseGrainedExecutorBackend”类的命令,
CoarseGrainedExecutorBackend类
Executor启动的一系列方法
def main(args: Array[String]) {
...
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
System.exit(0)
}
private def run(...) {
...
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
}
}
在Executor启动的一系列方法中,我们会发现实际上我们常说的Executor指的是一个名为“Executor”的Endpoint,Endpoint是属于spark通讯中的actor模型中的概念,我们将在下一篇文章中专门讲这个,此时我们只需要知道,在注册完这个Endpoint后,被注册的Endpoint的onStart方法会被调用;
CoarseGrainedExecutorBackend类
onStart方法
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
// Always receive `true`. Just ignore it
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
在onStart方法中,CoarseGrainedExecutorBackend向CoarseGrainedSchedulerBackend发送了一条名为“RegisterExecutor”的消息用于注册,CoarseGrainedSchedulerBackend收到消息后,回复一条“RegisteredExecutor”消息,CoarseGrainedExecutorBackend接收到后开始初始化Executor;
方法执行时序图
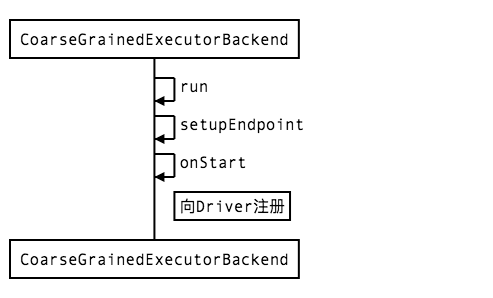

 浙公网安备 33010602011771号
浙公网安备 33010602011771号