
03requests模块基本使用
requests模块
概念:基于网络请求的模块,作用是用来模拟浏览器发起请求。
编码流程:
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
环境安装:
pip install requests
实例学习:
-
基于requests模块的get请求
需求:爬取搜狗指定词条搜索后的页面数据https://www.sogou.com/
-
基于requests模块ajax的get请求
需求:爬取豆瓣电影分类排行榜中的电影详情数据https://movie.douban.com/
-
基于requests模块ajax的post请求
需求:爬取肯德基餐厅查询中指定地点的餐厅数据http://www.kfc.com.cn/kfccda/storelist/index.aspx
-
综合练习
需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据http://scxk.nmpa.gov.cn:81/xk/
实例1:爬取搜狗指定词条搜索后的页面数据
简单的代码如下:
import requests
# Step1
url = 'https://www.sogou.com/'
# Step2:返回值是一个响应对象
response = requests.get(url = url)
# Step3:text返回的是字符串形式的响应数据
page_text = response.text
# Step4
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
按Enter+Shift,运行可以看到,目录里已经有了一个sogou.html的文件,打开是这样的:
(没有css)

实例2:基于搜狗编写简易
简单的代码:
import requests
wd = input('输入关键字(Enter a key):')
url = 'https://www.sogou.com/web'
# 存储就是动态的请求参数
params = {
'query':wd
}
# 一定要将params作用到请求中
# paramas参数表示的是对请求url参数的封装
response = requests.get(url=url,params=params)
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(wd,'下载成功!')
运行后会生成一个对应的html文件,打开后截图:

上述程序出现的问题:
- 问题1:爬取到的数据出现乱码(虽然我没出现)
- 问题2:UA检测
解决1:中文乱码
对应代码:
# 手动修改相应数据的编码
response.encoding = 'utf-8'
解决2:UA伪装
request发送请求并没有收到指定的搜索结果
反爬机制:UA检测
反反爬机制:UA伪装
对应代码:
# 即将发起请求对应的头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'
}
# headers参数用来进行UA伪装
response = requests.get(url=url,params=params,headers=headers)
完整代码
import requests
wd = input('输入关键字(Enter a key):')
url = 'https://www.sogou.com/web'
# 存储就是动态的请求参数
params = {
'query':wd
}
# 即将发起请求对应的头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'
}
# 一定要将params作用到请求中
# paramas参数表示的是对请求url参数的封装
# headers参数用来进行UA伪装
response = requests.get(url=url,params=params,headers=headers)
# 手动修改相应数据的编码
response.encoding = 'utf-8'
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(wd,'下载成功!')
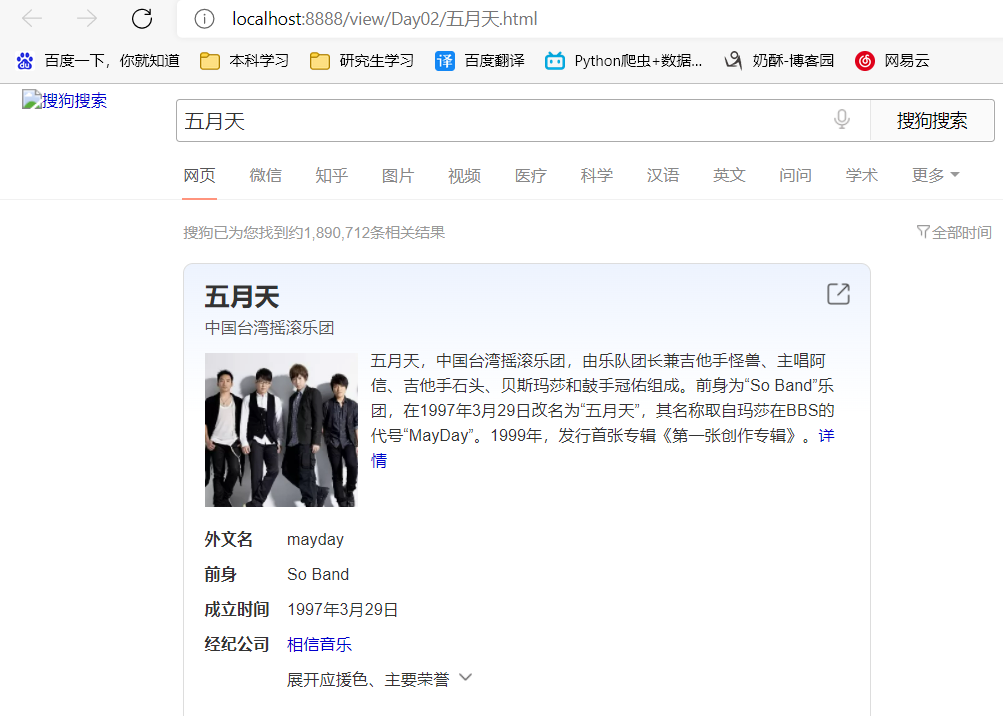
实验来搜索一下五月天,以下是运行截图:

实例3:爬取豆瓣电影排行榜数据
分析:当滚轮滑动到底部的时候,发起了一个Ajax的请求,且该请求请求到了一组电影数据
动态加载的数据:通过另一个额外的请求,请求到的数据
- Ajax生成动态加载的数据
- js生成动态加载的数据
找到对应的XHR:
相应返回的是一个json串
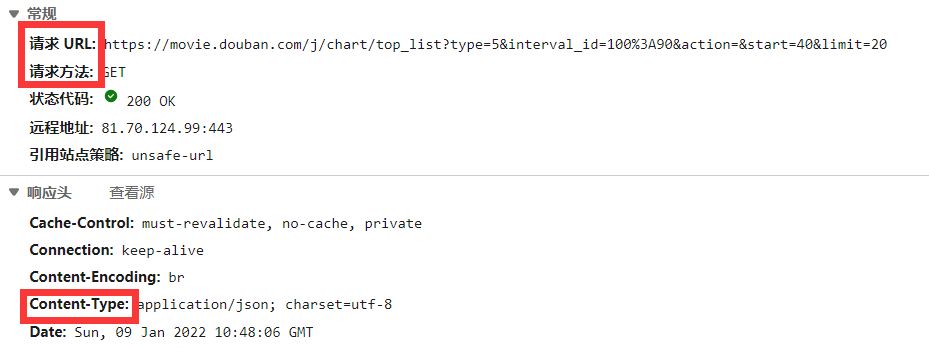
找到对应的Rseponse:

这里用一下json格式化工具:https://www.bejson.com/
格式化后:
[{
"rating": ["8.7", "45"],
"rank": 41,
"cover_url": "https://img2.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2614500883.jpg",
"is_playable": true,
"id": "11026735",
"types": ["喜剧", "动作", "科幻", "动画", "冒险"],
"regions": ["美国"],
"title": "超能陆战队",
"url": "https:\/\/movie.douban.com\/subject\/11026735\/",
"release_date": "2015-02-28",
"actor_count": 23,
"vote_count": 882325,
"score": "8.7",
"actors": ["斯科特·安第斯", "瑞恩·波特", "丹尼尔·海尼", "T·J·米勒", "郑智麟", "小达蒙·韦恩斯", "珍尼希斯·罗德里格兹", "詹姆斯·克伦威尔", "艾伦·图代克", "玛娅·鲁道夫", "亚布拉哈姆·本鲁比", "凯蒂·洛斯", "比利·布什", "丹尼尔·吉尔森", "保罗·布里格斯", "郝祥海", "查尔斯·阿德勒", "菅野美穗", "乔西·特立尼达", "Dan Howell", "斯坦·李", "大卫·肖内西", "夏洛特·古列齐"],
"is_watched": false
}.....
完整代码
import requests
# 反爬
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'
}
url='https://movie.douban.com/j/chart/top_list'
start = input('Enter a start:')
limit = input('Enter a limit:')
# 处理请求参数
params={
'type': '5',
'interval_id': '100:90',
'action': '',
'start': start,
'limit': limit,
}
response = requests.get(url=url,params=params,headers=headers)
# json返回的是序列化好的对象
data_list = response.json()
fp = open('douban.txt','w',encoding='utf-8')
for dic in data_list:
name = dic['title']
score=dic['score']
fp.write(name+''+score+'\n')
print(name,'爬取成功')
fp.close()
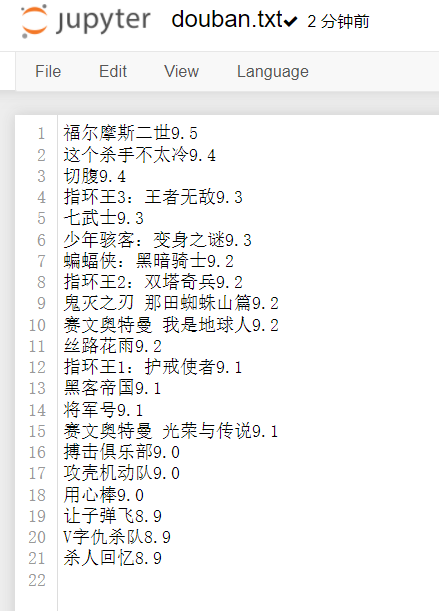
输出的结果,会生成一个douban.txt的文件里面有所有的信息:
拓展
想做一下朱全银老师的作业
# 反爬
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'
}
url='https://movie.douban.com/j/chart/top_list'
start = input('Enter a start:')
limit = input('Enter a limit:')
# 处理请求参数
params={
'type': '5',
'interval_id': '100:90',
'action': '',
'start': start,
'limit': limit,
}
response = requests.get(url=url,params=params,headers=headers)
# json返回的是序列化好的对象
data_list = response.json()
fp = open('ceshi.txt','w',encoding='utf-8')
for dic in data_list:
name = dic['title']
types = str(dic['types'])
regions = str(dic['regions'])
actors = str(dic['actors'])
date = dic['release_date']
score = dic['score']
vote = str(dic['vote_count'])
picture = dic['cover_url']
fp.write(name+';'+types+';'+regions+';'+actors+';'+date+score+';'+vote+';'+picture+'\n')
fp.close()
本来想爬10万条数据的,结果他只有375条,麻了
因为调试太多次了,被豆瓣拉黑了,麻了
遇到的问题:
- 如果原数据是int型或者数组,要把它变成字符串类型,str()
- 更新了requests包(好像是)
实例4:爬取肯德基餐厅位置查询
网址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
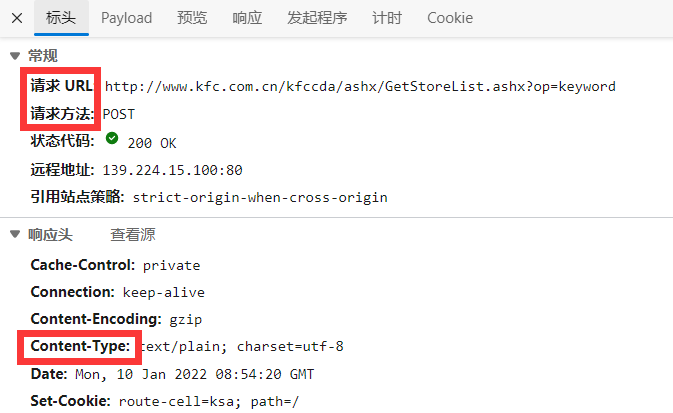
通过查询发现是一个POST请求:
找到Response,使用json格式化工具:
{
"Table": [{
"rowcount": 30
}],
"Table1": [{
"rownum": 1,
"storeName": "新苏站",
"addressDetail": "苏站路27号苏州站北广场北出站口东侧B1层出租车上车点方向",
"pro": "24小时,Wi-Fi,礼品卡",
"provinceName": "江苏省",
"cityName": "苏州市"
}......
完整代码:
import requests
# 反爬
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'
}
post_url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
city = input('输入所要查询的城市(Enter a city):')
data = {
'cname': '',
'pid':'' ,
'keyword': city,
'pageIndex': '1',
'pageSize': '10',
}
# data里放的就是get方法中的params
response = requests.post(url=post_url,data=data,headers=headers)
response.json()
能成功输出~
最后的思考
代码理解没有难度,就是要花时间看看能不能自己写出来
爬虫有风险,学习需谨慎,我被豆瓣拉黑了还没放出来
话说截图买的空气炸锅到了,用烤肠试了试,真棒,晚上炸薯条


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人