
23Flappy Bird自主学习程序基本框架
Flappy Bird自主学习程序基本框架
用DQN实现
程序基本框架
程序与模拟器交互
训练过程也就是神经网络(agent)不断与游戏模拟器(Environment)进行交互,通过模拟器获得状态,给出动作,改变模拟器中的状态,获得反馈,依据反馈更新策略的过程。
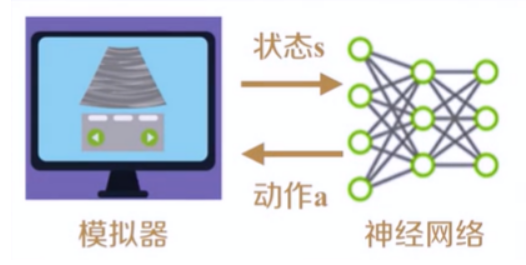
训练过程
训练过程过程主要分为以下三个阶段:
1、观察期(OBSERVE):程序与模拟器进行交互,随机给出动作,获取模拟器中的状态,将状态转移过程存放在D(Replay Memory)中;
2、探索期(EXPLORE):程序与模拟器交互的过程中,依据Replay Memory中存储的历史信息更新网络参数,并随训练过程降低随机探索率ε;
3、训练期(TRAIN): ε已经很小,不再发生改变,网络参数随着训练过程不断趋于稳定。
整体框架——观察期
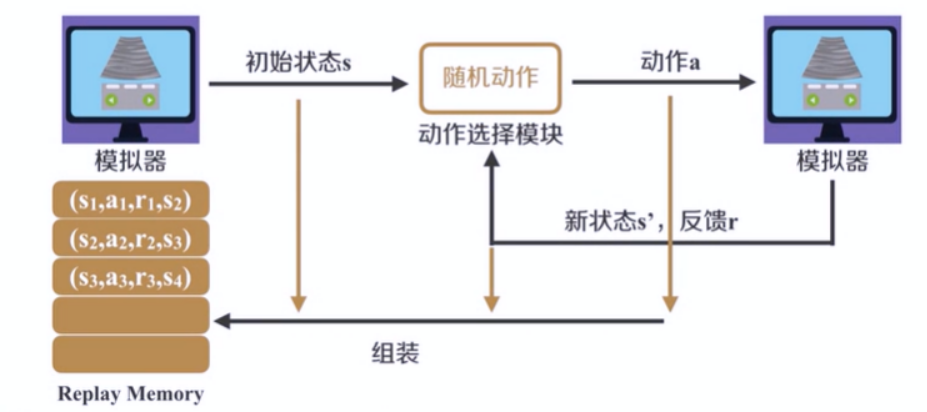
观察期的主要步骤:
-
在观察期,首先需要打开游戏模拟器,不需要执行跳跃动作,获取游戏的初始状态。
-
然后根据ε贪心策略获得一个动作,由于神经网络参数也是随机初始化的,在本阶段,参数也不会进行更新,所以统称为随即动作,并根据迭代次数,减小ε的大小。
-
由模拟器执行选择的动作,能够返回新的状态,和反馈奖励。将上一状态s、动作a,新状态s'、反馈r,组装成(s,a,s',r)放入(Replay Memory)D 中,用作以后的参数更新。
-
根据新的状态s',根据ε贪心策略,选择下一步执行的动作。
周而复始,直到迭代次数达到探索期。
整体框架——探索期
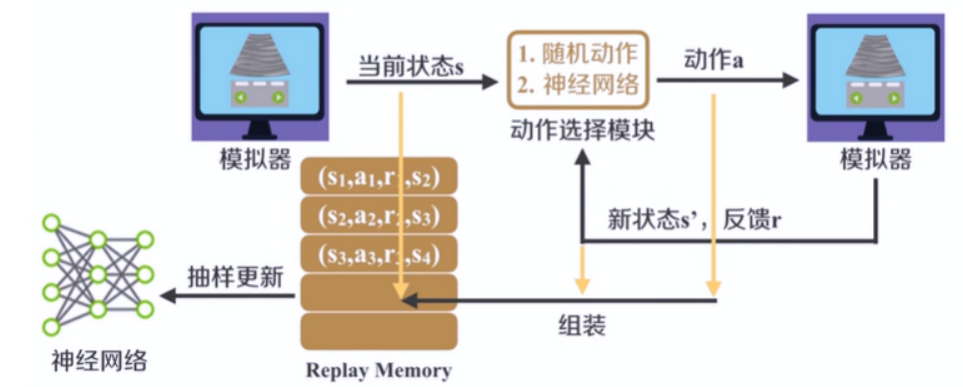
探索期的主要步骤:
- 探索期阶段,和上一阶段的唯一区别,在于会根据抽样对网络参数进行更新。
- 首先,当迭代次数达到一定数目的时候,程序进入探索期。就要根据当前状态s,使用ε贪心策略选择一个动作。可以是随机动作,或者由神经网络选择动作,并根据迭代次数,减小ε的值。
- 接下来由模拟器执行的动作,可以返回新的状态和反馈奖励。将上一状态s、动作a、新状态s‘、反馈r组装成(s,a,s',r)放入(Replay Memory)D 中,作为参数更新使用。
- 从(Replay Memory)D中抽取一定的样本,对神经网络的参数进行更新。根据新的状态s',根据ε贪心策略,选择下一步执行的动作。
周而复始,直到迭代次数达到训练期。
整体框架——训练期
当迭代次数达到一定的数目,程序进入训练期。
训练期阶段,和探索期的过程相同。只是在迭代过程中不再修改ε的值。
模拟器
游戏模拟器
使用Python的Pygame模块完成的FlappyBird游戏程序,为了配合训练过程,在原有的游戏程序基础上进行了修改。参考以下网址查看游戏源码:
链接:https://github.com/sourabhv/FlapPyBird
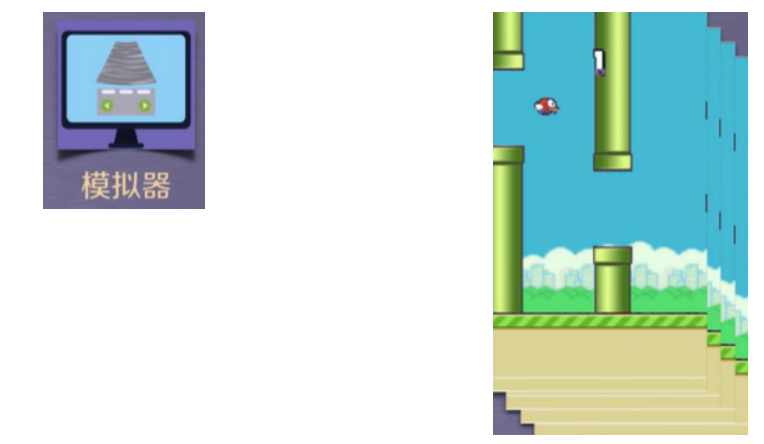
-
图示通过模拟器获取游戏的画面。
-
训练过程中使用连续4帧图像作为一个状态s,用于神经网络的输入。
动作选择模块
动作选择模块:为ε贪心策略的简单应用,以概率ε随机从动作空间A中选择动作,以1-ε概率依靠神经网络的输出选择动作:
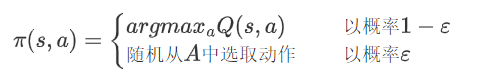
卷积神经网络CNN
DQN:用卷积神经网络对游戏画面进行特征提取,这个步骤可以理解为对状态空间的特征提取。
卷积神经网络(CNN):
-
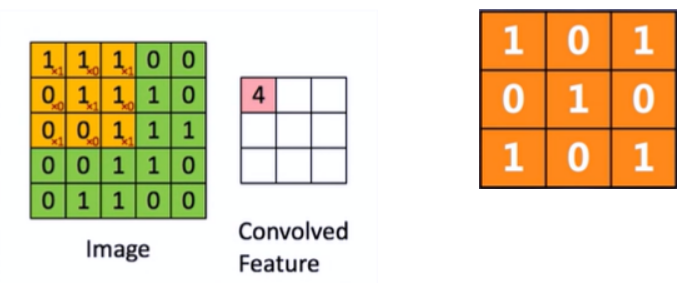
CNN-卷积核:这里的卷积核指的就是移动中3*3大小的矩阵。
-
CNN-卷积操作:使用卷积核与数据进行对应位置的乘积并加和,不断移动卷积核生成卷积后的特征。
-
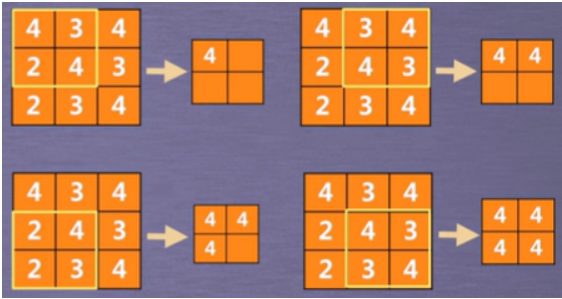
CNN-池化操作:对卷积的结果进行操作。最常用的是最大池化操作,即从卷积结果中批出最大值,如选择一个2×2大小的池化窗口。
卷积神经网络:
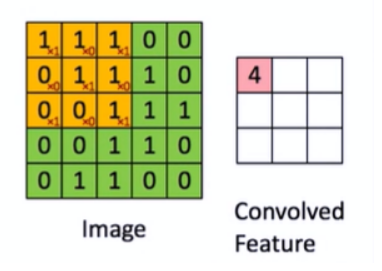
把Image矩阵中的每个元素当做一个神经元,那么卷积核就相当于输人神经元和输出神经元之间的链接权重,由此构建而成的网络被称作卷积神经网络。
Flappy Bird-深度神经网络
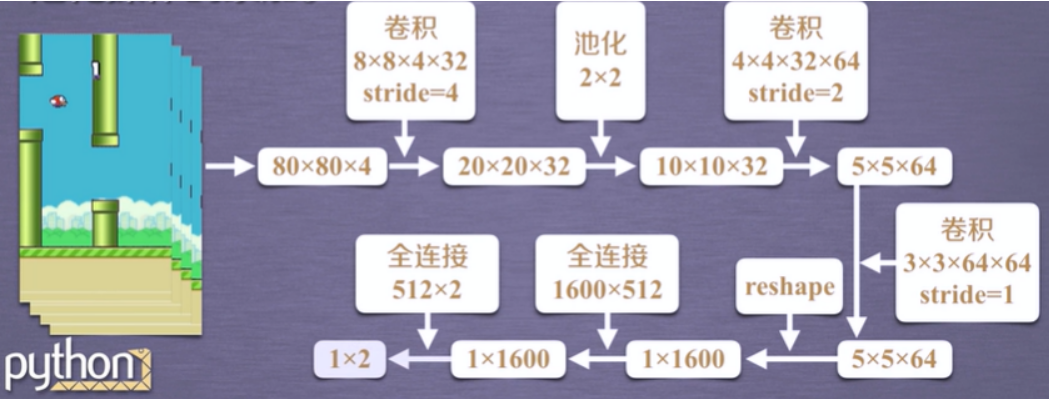
本实验中使用的深度神经网络结构就是多个卷积操作和池化操作的累加。
具体的步骤包括:
- 对采集的4张原始图像进行预处理,得到80x80x4大小的矩阵。
- 使用32个80x80x4大小步长为4的卷积核对以上矩阵进行卷积,得到20x20x32大小的矩阵。
- 需要注意的是,Tensor Flow当中需要使用四维向量来表示卷积和。他的基本模式为,输入通道数、高度、宽度、输出通道数,对应于上面的4、8、8、32,可以理解为32个8x8x4大小的卷积核。
- 接下来,需要对以上矩阵进行不重叠的池化操作,池化窗口大小为2x2,步长为2,这样就可以得到10x10x32大小的矩阵。
- 接着使用64个4x4x32大小步长为2的卷积核对以上矩阵进行卷积,得到5x5x64的矩阵。
- 接着使用64个3x3x64大小步长为1的卷积核对以上矩阵进行卷积,得到5x5x64的矩阵。
- 接着将输出的5x5x64大小的数组进行reshape,得到1x1600大小的矩阵。
- 在之后添加一个全连接层,神经元个数为512。
- 最后一层也是一个全连接层,神经元个数为2,对应的就是两个动作的动作值函数。
至此,神经网络的结构就就此清晰了。
通过获得输人s,神经网络就能够:
- 输出Q(s,a1)和Q(s,a2),比较两个值的大小,就能够评判采用动作a1和a2的优劣,从而选择要采取的动作;
- 在选择并执行完采用的动作后,模拟器会更新状态并返回回报值,然后将这个状态转移过程存储进(Replay Memory)D,进行采样更新网络参数。
网络参数的更新方式
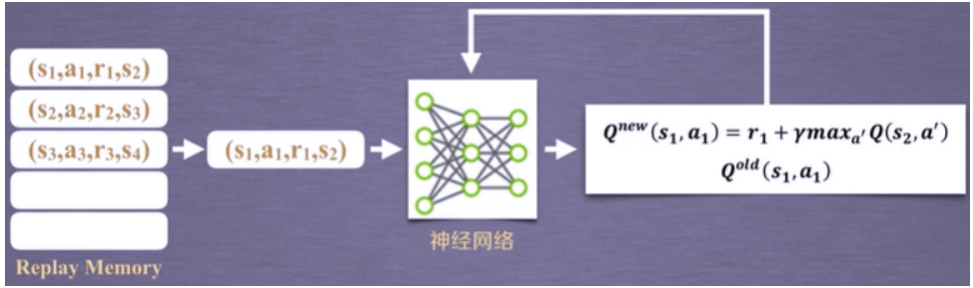
- 首先要从Replay Memory采样一部分状态对,比如这里拿到一条数据(s1,a1,r1,s2)。
- 然后根据神经网络计算Q值的最大值,用来获得Q(s1,a1)的新值。
- 在之后,通过神经网络获得Q(s1,a1)的旧值。
- 利用两者的差值,使用梯度下降的方法更新网络的参数。
好难啊啊啊啊啊啊啊

