21强化学习
强化学习
- 也称增强学习。
- 强化学习就是程序或智能体(agent)通过与环境不断地进行交互学习一个从环境到动作的映射,学习的目标就是使累计回报最大化。
- 强化学习是一种试错学习,因其在各种状态(环境)下需要尽量尝试所有可以选择的动作,通过环境给出的反馈(即奖励)来判断动作的优劣,最终获得环境和最优动作的映射关系(即策略)。
举例
吃豆游戏就可以转化为一个强化学习的任务。

基本组件:
- agent:大嘴小怪物
- 环境:整个迷宫中的所有信息
- 奖励:agent每走一步,需要扣除1分,吃掉小球得10分,吃掉敌人得200分,被吃掉游戏结束。
- 动作:在每种状态下,agent能够采用的动作,比如上下左右移动。
目标:
- 策略:在每种状态下,采取最优的动作。
- 学习目标:获得最优的策略,以使累计奖励最大(即Score)。
马尔可夫决策过程(MDP)
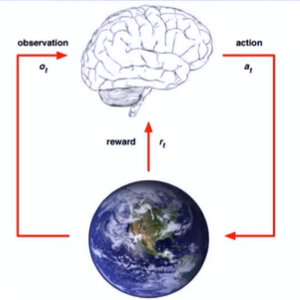
- 马尔可夫决策过程(MarkovDecision Process)通常用来描述一个强化学习问题。
- 智能体agent根据当前对环境的观察采取动作获得环境的反馈,并使环境发生改变的循环过程。
MDP基本元素
s∈S:有限状态state集合,s表示某个特定状态;
a∈A:有限动作action集合,a表示某个特定动作;
T(S, a, S') ~ Pr(S'|s,a):状态转移模型,根据当前状态s和动作a预测下一个状态s,这里的P,表示从s采取行动a转移到s’的概率;
R(s,a):表示agent采取某个动作后的即时奖励,它还有R(s,a,s'),R(s)等表现形式;
Policy Π(s)→a:根据当前state来产生action,可表现为a=T(s)或Π(als) = P(als),后者表示某种状态下执行某个动作的概率。
值函数
状态值函数V表示行策略n能得到的累计折扣奖励:
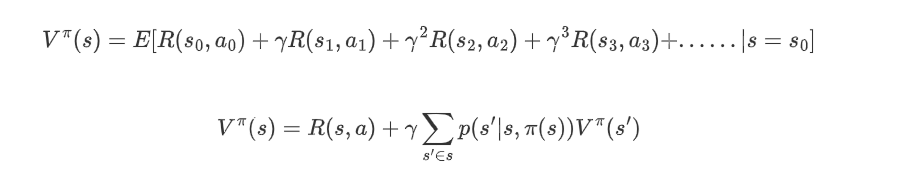
状态动作值函数Q(s,a)表示在状态s下执行动作a能得到的累计折扣奖励:
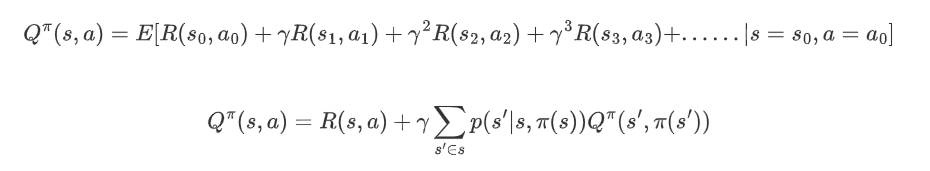
最优值函数
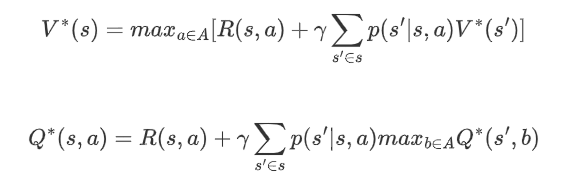
最优控制
在得到最优值函数之后,可以通过值函数的值得到状态s时应该采取的动作a:
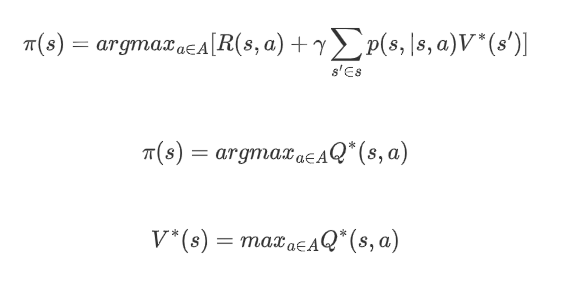
蒙特卡洛强化学习
蒙特卡洛强化学习
- 在现实的强化学习任务中,环境的转移概率、奖励函数往往很难得知,甚至很难得知环境中有多少状态。若学习算法不再依赖于环境建模,则称为免模型学习,蒙特卡洛强化学习就是其中的一种。
- 蒙特卡洛强化学习使用多次采样,然后求取平均累计奖赏作为期望累计奖赏的近似。
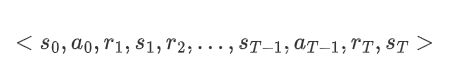
蒙特卡洛强化学习:直接对状态动作值函数Q(s,a)进行估计,每采样一条轨迹,就根据轨迹中的所有“状态-动作”利用下面的公式对来对值函数进行更新。
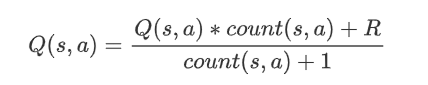
每次采样更新完所有的“状态-动作”对所对应的Q(s,a),就需要更新采样策略t。但由于策略可能是确定性的,即一个状态对应一个动作,多次采样可能获得相同的采样轨迹,因此需要借助ε贪心策略:

Q-learning算法
- 今蒙特卡洛强化学习算法需要采样一个完整的轨迹来更新值函数,效率较低,此外该算法没有充分利用强化学习任务的序贯决策结构。
- Q-learning算法结合了动态规划与蒙特卡洛方法的思想,使得学习更加高效。
Q-learning算法
假设对于状态动作对(s,a)基于t次采样估算出其值函数为:
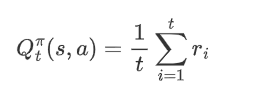
在进行t+1次采样后,依据增量更新得到:
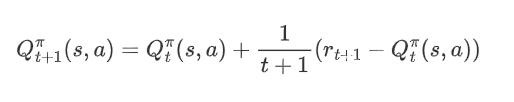
然后,将1/t+1替换成系数α(步长),得到:
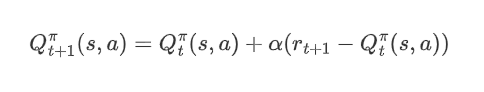
以γ折扣累计奖赏为例:
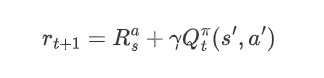
则值函数的更新方式如下:
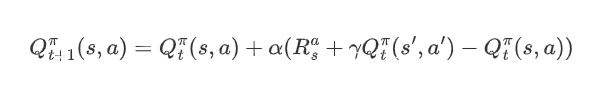
Q-learning算法流程:

深度强化学习(DRL)
深度强化学习
- 传统强化学习:真实环境中的状态数目过多,求解困难。
- 深度强化学习:将深度学习和强化学习结合在一起,通过深度神经网络直接学习环境(或观察)与状态动作值函数Q(s,a)之间的映射关系,简化问题的求解。
Deep Q Network (DQN)
- Deep Q Network (DQN):是将神经网络(neuralnetwork)和Q-learning结合,利用神经网络近似模拟函数Q(s,a),输入是问题的状态(e.g.,图形),输出是每个动作a对应的Q值,然后依据Q值大小选择对应状态执行的动作,以完成控制。
- 神经网络的参数:应用监督学习完成。
DQN学习过程学习流程:
- 1、状态s输入,获得所有动作对应的Q值Q(s,a);
- 2、选择对应Q值最大的动作a'并执行;
- 3、执行后环境发生改变,并能够获得环境的奖励r;
- 4、利用奖励r更新Q(s,a')--强化学习;利用新的Q(s,a')更新网络参数-监督学习。
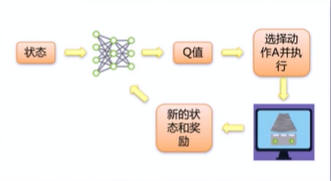
DQN算法流程

最后的思考
今天的笔记公式真多啊,对着视频敲公式,头都晕了,10分钟的视频看了一个多小时呜呜呜。
结果上传的时候公式还要一个个截图。
今天周一满课,好累。
想玩饥荒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号