05无监督学习-聚类Kmeans
K-means方法及应用
K-means聚类算法
k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
-
随机选择k个点作为初始的聚类中心。
-
对于剩下的点,根据其与聚类中心的距离,将其归人最近的簇。
-
对每个簇,计算所有点的均值作为新的聚类中心。
-
重复2、3直到聚类中心不再发生改变。
举例:这里计算距离用的是欧氏距离
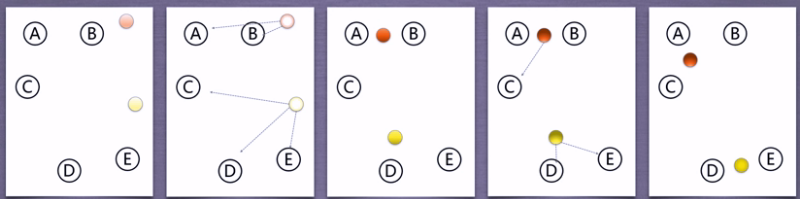
-
随机选红黄两个点作为初始的聚类中心(图1)
-
第一次聚类结果,AB离红点更近,CDE离黄点更近(图2)
所以在第一次分类中,被定义为AB为一个簇,CDE是一个簇
-
计算AB簇的聚类中心,标记为深红,计算CDE的聚类中心,标记为深黄(图3)
第二次聚类结果,ABC为一个簇,DE为一个簇(图4)
-
再第三次聚类,发现ABC一个簇,DE一个簇(图5)
已经稳定了,所以可以得到ABC是一个簇,DE是一个簇
K-means的应用数据介绍:
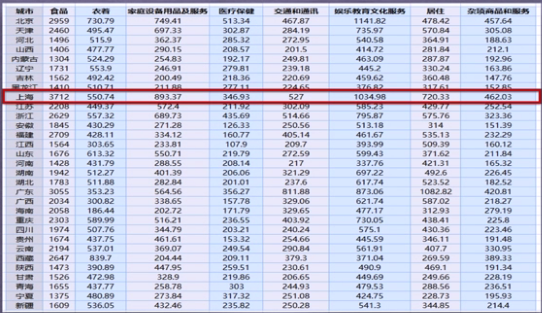
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
K-means的应用
实验目的:
通过聚类,了解1999年各个省份的消费水平在国内的情况。
技术路线:sklearn.cluster.Kmeans
数据实例:1999年全国31个省份城镇居民家庭平均每人全年消费性支出数据
使用算法:K-means聚类算法
实现过程:
1、建立工程,导人sklearn相关包。
import numpy as np
from sklearn.cluster import KMeans
2、加载数据,创建K-means算法实例,并进行训练,获得标签:
调用K-Means方法所需参数:
- n_clusters:用于指定聚类中心的个数
- init:初始聚类中心的初始化方法
- max iter:最大的迭代次数
- 一般调用时只用给出n_clusters即可,init默认是k-means++,max iter默认是300
其它参数:
- data:加载的数据
- label:聚类后各数据所属的标签
- fit_predict():计算簇中心以及为簇分配序号
重点方法解释:data,cityName = loadData('city.txt')
- 自己写了一个loadData的方法,用来获取文件中的信息(具体代码在后面)
- r+:读写打开一个文本文件
- readlines()一次读取整个文件(类似于.read() )
- retCityName:用来存储城市名称
- retData:用来存储城市的各项消费信息返回值:返回城市名称,以及该城市的各项消费信息
展示数据:
- 将城市按label分成设定的簇
- 将每个簇的城市输出
- 将每个簇的平均花费输出
3、输出标签,查看结果
将城市按照消费水平n_clusters类,消费水平相近的城市聚集在一类中。
expense:聚类中心点的数值加和,也就是平均消费水平。
详细代码注解:
# 1、建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import KMeans
# 定义loadData函数
def loadData(filePath):
fr = open(filePath, "r+")
lines = fr.readlines()
retData = [] # 用来存储城市的各项消费信息
retCityName = [] # 用来存储城市名称
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1, len(items))])
for i in range(1, len(items)):
return retData, retCityName # 返回值:返回城市名称,以及该城市的各项消费信息
# 2、加载数据(loadData函数),创建K-means算法实例,并进行训练,获得标签:
if __name__ == '__main__':
data, cityName = loadData("city.txt")
km = KMeans(n_clusters=2)
label = km.fit_predict(data) # 调用Kmeans()fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_, axis=1)
# print(expenses)
CityCluster = [[], [], []]
for i in range(len(cityName)): # 将城市按label分成设定的簇
CityCluster[label[i]].append(cityName[i]) # 将每个簇的城市输出
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses[i]) # 将每个簇的平均花费输出
print(CityCluster[i])
输出结果:
聚成3类:km=KMeans(n_clusters=2)
详细代码:
# 聚成2类:km=Kmeans(n_clusters=2)
if __name__ == '__main__':
data,cityName = loadData("city.txt")
km = KMeans(n_clusters=2)
label = km.fit_predict(data) #调用Kmeans()fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expenses)
CityCluster = [[],[]]
for i in range(len(cityName)): #将城市按label分成设定的簇
CityCluster[label[i]].append(cityName[i]) #将每个簇的城市输出
for i in range(len(CityCluster)):
print("Expenses:%.2f" %expenses[i]) #将每个簇的平均花费输出
print(CityCluster[i])
输出结果:
4040.4156521739133
['河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '江苏', '安徽', '江西', '山东', '河南', '湖南', '湖北', '广西', '海南', '四川', '贵州', '云南', '陕西', '甘肃', '青海', '宁夏', '新疆']
6457.133749999999
['北京', '天津', '上海', '浙江', '福建', '广东', '重庆', '西藏']
聚成3类:km=KMeans(n_clusters=3)
详细代码:
# 聚成3类:km=Kmeans(n_clusters=3)
if __name__ == '__main__':
data,cityName = loadData("city.txt")
km = KMeans(n_clusters=3)
label = km.fit_predict(data) #调用Kmeans()fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expenses)
CityCluster = [[],[],[]]
for i in range(len(cityName)): #将城市按label分成设定的簇
CityCluster[label[i]].append(cityName[i]) #将每个簇的城市输出
for i in range(len(CityCluster)):
print("Expenses:%.2f" %expenses[i]) #将每个簇的平均花费输出
print(CityCluster[i])
输出结果:
3827.8658823529413
['河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '安徽', '江西', '山东', '河南', '湖北', '贵州', '陕西', '甘肃', '青海', '宁夏', '新疆']
7754.656666666666
['北京', '上海', '广东']
5113.54
['天津', '江苏', '浙江', '福建', '湖南', '广西', '海南', '重庆', '四川', '云南', '西藏']
聚成4类:km=Kmeans(n_clusters=4)
详细代码:
# 聚成4类:km=Kmeans(n_clusters=4)
if __name__ == '__main__':
data,cityName = loadData("city.txt")
km = KMeans(n_clusters=4)
label = km.fit_predict(data) #调用Kmeans()fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expenses)
CityCluster = [[],[],[],[]]
for i in range(len(cityName)): #将城市按label分成设定的簇
CityCluster[label[i]].append(cityName[i]) #将每个簇的城市输出
for i in range(len(CityCluster)):
print("Expenses:%.2f" %expenses[i]) #将每个簇的平均花费输出
print(CityCluster[i])
输出结果:
Expenses:4512.27
['江苏', '安徽', '湖南', '湖北', '广西', '海南', '四川', '云南']
Expenses:7754.66
['北京', '上海', '广东']
Expenses:5678.62
['天津', '浙江', '福建', '重庆', '西藏']
Expenses:3788.76
['河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '江西', '山东', '河南', '贵州', '陕西', '甘肃', '青海', '宁夏', '新疆']
最后需要注意的地方
1、所准备的city.txt文件是我从网上复制下来的数据,保存的时候要注意txt的编码方式要改成ANSI,因为txt默认编码方式为UTF-8
2、city.txt文件所存放的路径,晚上直接放在和python文件一起的,所以路径没有变动
3、在聚成的簇数量不同时,不能只改一个数字,代码也要跟着有稍许变动
4、关于
if __name__ == '__main__':
这行代码,我本来查的网站上用的时is,没有用 == 会有报错
拓展和改进
计算两条数据相似性时,Sklearn的K-Means默认用的是欧式距离。虽然还有余弦相似度,马氏距离等多种方法,但没有设定计算距离方法的参数。
如果想要自定义计算距离的方式时,可以改变kmeans的源代码,可以使用scipy.spatial.distance.cdist方法。
如果要用余弦距离,可使用scipy.spatial.distance.cdist(A, B, metric='cosine')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号