
成长笔记之博客统计第一篇
实习快两星期了,上的第一堂课就是学会观察,观察应该不仅仅局限于外面的事物,还应该有身边同学的起起伏伏。总结下这周收获更多的是态度:
1.态度上需要的是为什么而不是得到什么,如果你是为了完成什么和做什么,你会觉得遇到的所有困难是拦路虎,于是热情退却,而如果你觉得你遇到的所有困难都是走向成功的阶梯,恭喜你,你正在进步。
2.团队的力量往往比个人强大,一个人也能完成目标,但你始终走在自己的思维里,而一名不断进步的程序员需要不断的吸收他人的思维,接受新知识。
3.总结归纳更重要,这两天翻写了以前写过了代码,会发现自己以前的代码不堪入目,自己都觉得难以借鉴,所以复杂的事情简单做,简单的事情重复做,重复的事情认真做。
闲话就扯到这里,讲讲今天的重点,实习小实践:博客园博客统计。需求:不限语言,不限平台,根据姓名,博客地址,统计如下信息
![]()

谈谈思路:
第一步:第一反应当然是根据http://www.cnblogs.com/Sir-Lin/去寻找网页中的文本,这时你会发现很多网页上显示的内容,在源代码里并不能找到,这是因为这些调皮的元素来自于JavaScipt返回的数据,但别以为这样就能逃出我们的火眼金睛,借助工具HttpAnalyzerStdV7就能轻松找到这些JS请求的网址.例如我们要去寻找每篇文章的推荐数反对数。打开网页http://www.cnblogs.com/Sir-Lin/p/FirstStep.html,并运行HttpAnalyzerStdV7.
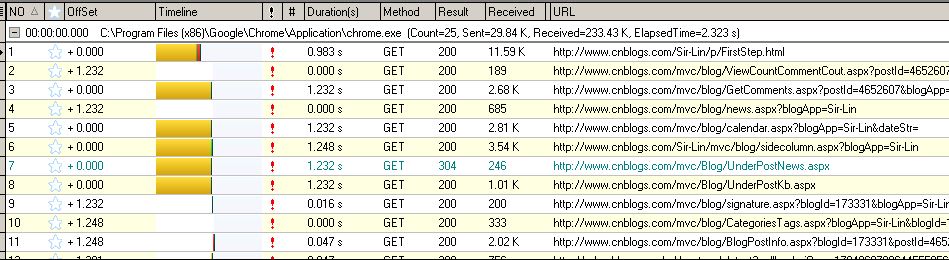
这里就获取到了所以该网页的数据包括JavaScript请求的数据

然后得到js访问的url也就是我们需要的url

再根据Jsoup来获取网页的源代码和我们需要的数据。简单介绍几个常用的方法
1 //从一个URL加载一个Document 2 Document doc = Jsoup.connect("http://example.com/").get(); 3 //这个时候就类似javascript获取element 4 Element content = doc.getElementById("content"); 5 6 Elements links = content.getElementsByTag("a"); 7 8 for (Element link : links) { 9 String linkHref = link.attr("href"); 10 String linkText = link.text(); 11 } 12 13 Elements links = doc.select("a[href]"); //带有href属性的a元素 14 15 Element masthead = doc.select("div.masthead").first(); 16 //class等于masthead的div标签 17 18 Elements resultLinks = doc.select("h3.r > a"); //在h3元素之后的a元素
具体关于Jsoup的介绍和学习可以参考下面的内容http://www.open-open.com/jsoup/。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号