

【C#数据结构系列】图
一:图
图状结构简称图,是另一种非线性结构,它比树形结构更复杂。树形结构中的结点是一对多的关系,结点间具有明显的层次和分支关系。每一层的结点可以和下一层的多个结点相关,但只能和上一层的一个结点相关。而图中的顶点(把图中的数据元素称为顶点)是多对多的关系,即顶点间的关系是任意的,图中任意两个顶点之间都可能相关。也就是说,图的顶点之间无明显的层次关系,这种关系在现实世界中大量存在。因此,图的应用相当广泛,在自然科学、社会科学和人文科学等许多领域都有着非常广泛的应用。
1.1:图的基本概念
1.1.1:图的定义
图(Graph)是由非空的顶点(Vertex)集合和描述顶点之间的关系——边(Edge)或弧(Arc)的集合组成。其形式化定义为:
G=(V,E)
V={v i |v i ∈某个数据元素集合}
E={(v i ,v j )|v i ,v j ∈V∧P(v i ,v j )}或E={<v i ,v j >|v i ,v j ∈V∧P(v i ,v j )}
其中,G 表示图,V 是顶点的集合,E 是边或弧的集合。在集合 E 中,P(vi,vj)表示顶点 vi 和顶点 vj 之间有边或弧相连。下图给出了图的示例。
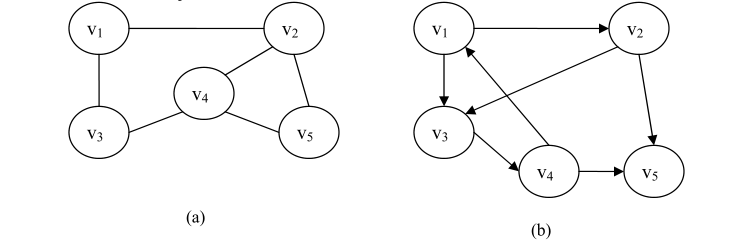
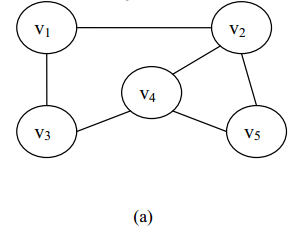
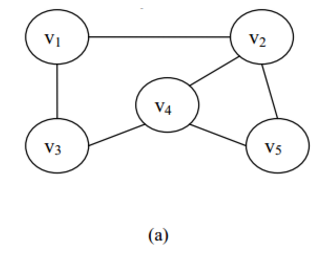
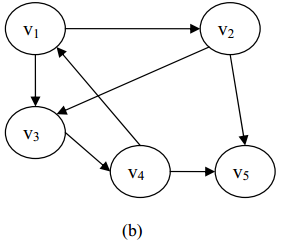
在图 (a)中,V={v 1 ,v 2 ,v 3 ,v 4 ,v 5 }E={(v 1 ,v 2 ),(v 1 ,v 3 ),(v 2 ,v 4 ),(v 2 ,v 5 ),(v 3 ,v 4 ),(v 4 ,v 5 )}
在图 (b)中,V={v 1 ,v 2 ,v 3 ,v 4 ,v 5 }E={<v 1 ,v 2 >,<v 1 ,v 3 >,<v 2 ,v 3 >,<v 2 ,v 5 ><v 3 ,v 4 >,<v 4 ,v 1 >,<v 4 ,v 5 >}。
注:无向边用小括号“()”表示,而有向边用尖括号“<>”表示。
1.1.2:图的基本术语
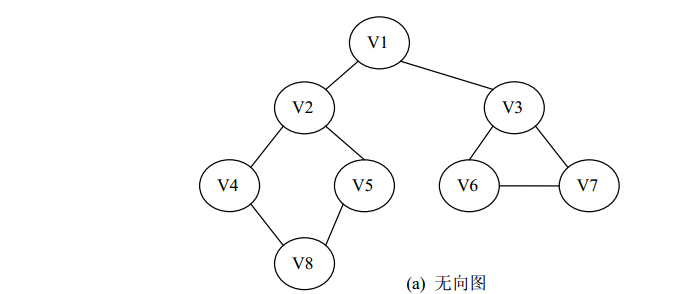
1、无向图:在一个图中,如果任意两个顶点v i 和v j 构成的偶对(v i ,v j )∈E是无序的,即顶点之间的连线没有方向,则该图称为无向图(Undirected Graph)。图 (a)是一个无向图。
2、有向图:在一个图中,如果任意两个顶点v i 和v j 构成的偶对<v i ,v j >∈E是有序的,即顶点之间的连线有方向,则该图称为有向图(Directed Graph)。图(b)是一个有向图。
3、边、弧、弧头、弧尾:无向图中两个顶点之间的连线称为边(Edge),边用顶点的无序偶对(v i ,v j )表示,称顶点v i 和顶点v j 互为邻接点(Adjacency Point),(v i ,v j )边依附与顶点v i 和顶点v j 。有向图中两个顶点之间的连线称为弧(Arc),弧用顶点的有序偶对<v i ,v j >表示,有序偶对的第一个结点v i 称为始点(或弧尾),在图中不带箭头的一端;有序偶对的第二个结点v j 称为终点(或弧头),在图中带箭头的一端。
4、无向完全图:在一个无向图中,如果任意两个顶点之间都有边相连,则称该图为无向完全图(Undirected Complete Graph)。可以证明,在一个含有 n 个顶点的无向完全图中,有 n(n-1)/2 条边。
5、有向完全图:在一个有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图(Directed Complete Graph)。可以证明,在一个含有 n 个顶点的有向完全图中,有 n(n-1)条弧。
6、顶点的度、入度、出度:在无向图中,顶点 v 的度(Degree)是指依附于顶点 v 的边数,通常记为 TD(v)。在有向图中,顶点的度等于顶点的入度(In Degree)与顶点的出度之和。顶点v的入度是指以该顶点v为弧头的弧的数目,记为ID(v);顶点 v 的出度(Out Degree)是指以该顶点 v 为弧尾的弧的数目,记为 OD(v)。所以,顶点 v 的度 TD(v)= ID(v)+ OD(v)。
例如,在无向图 (a)中有:
TD(v 1 )=2 TD(v 2 )=3 TD(v 3 )=2 TD(v 4 )=3 TD(v 5 )=2
在有向图 (b)中有:
ID(v 1 )=1 OD(v 1 )=2 TD(v 1 )=3
ID(v 2 )=1 OD(v 2 )=2 TD(v 2 )=3
ID(v 3 )=2 OD(v 3 )=1 TD(v 3 )=3
ID(v 4 )=1 OD(v 4 )=2 TD(v 4 )=3
ID(v 5 )=2 OD(v 5 )=0 TD(v 5 )=2
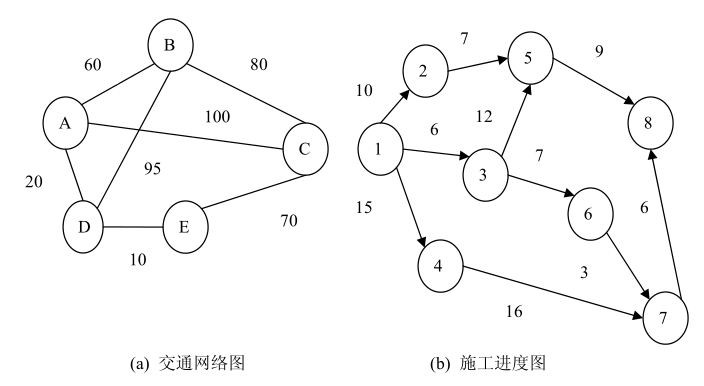
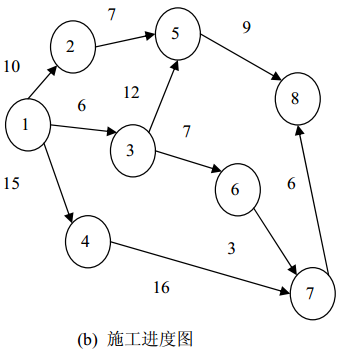
7、权、网:有些图的边(或弧)附带有一些数据信息,这些数据信息称为边(或弧)的权(Weight)。在实际问题中,权可以表示某种含义。比如,在一个地方的交通图中,边上的权值表示该条线路的长度或等级。在一个工程进度图中,弧上的权值可以表示从前一个工程到后一个工程所需要的时间或其它代价等。边(或弧)上带权的图称为网或网络(Network)。 下图是权图的示例图。
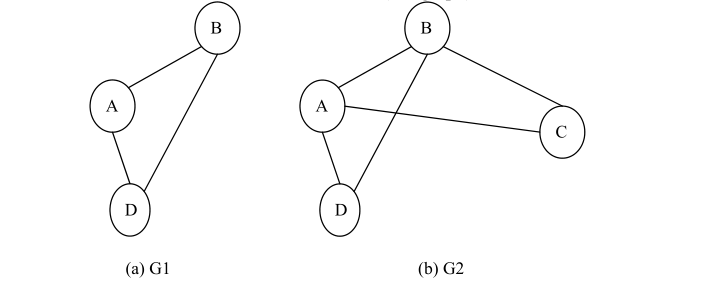
8、子图:设有两个图 G1=(V1,E1),G2=(V2,E2),如果 V1 是 V2 子集,E1 也是 E2 的子集,则称图 G1 是 G2 的子图(Subgraph)。下图是子图的示例图。
9、路径、路径长度:在无向图G中,若存在一个顶点序列V p ,V i1 ,V i2 ,…,V im ,V q ,使得(V p ,V i1 ),(V i1 ,V i2 ),…,(V im ,V q )均属于E(G)。则称顶点V p 到V q 存在一条路径(Path)。若G为有向图,则路径也是有向的。它由E(G)中的弧<V p ,V i1 >,<V i1 ,V i2 >,…,<V im ,V q >组成。路径长度(Path Length)定义为路径上边或弧的数目。在图 (a)交通网络图中,从顶点A到顶点B存在 4 条路径,长度分别为1、2、2、4。在图 (b)施工进度图中,从顶点 1 到顶点 7 存在 2 条路径,长度分别为 2 和3。
10、简单路径、回路、简单回路:若一条路径上顶点不重复出现,则称此路径为简单路径(Simple Path)。第一个顶点和最后一个顶点相同的路径称为回路(Cycle)或环。除第一个顶点和最后一个顶点相同其余顶点都不重复的回路称为简单回路(Simple Cycle),或者简单环。
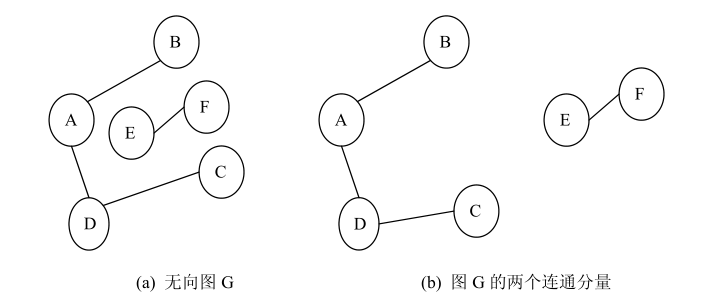
11、连通、连通图、连通分量:在无向图中,若两个顶点之间有路径,则称这两个顶点是连通的(Connect)。如果无向图 G 中任意两个顶点之间都是连通的,则称图 G 是连通图(Connected Graph)。连通分量(Connected Compenent)是无向图 G的极大连通子图。极大连通子图是一个图的连通子图,该子图不是该图的其它连通子图的子图。图 (a)G1和图(b)G2是连通图,图的连通分量的示例见下图所示。图 6.4(a)中的图 G 有两个连通分量。
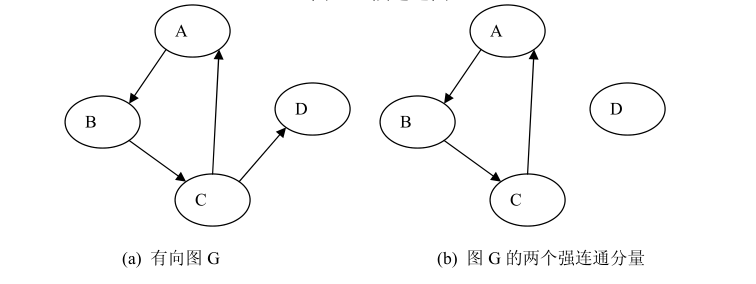
12、强连通图、强连通分量:在有向图中,若图中任意两个顶点之间都存在从一个顶点到另一个顶点的路径,则称该有向图是强连通图(Strongly ConnectedGraph) 。 有 向 图 的 极 大 强 连 通 子 图 称 为 强 连 通 分 量 (Strongly ConnectedComponent)。极大强连通子图是一个有向图的强连通子图,该子图不是该图的其它强连通子图的子图。左图是强连通图,右图是强连通分量的示例图。图(a)中的有向图 G 有两个强连通分量。
13、生成树:所谓连通图 G 的生成树(Spanning Tree)是指 G 的包含其全部顶点的一个极小连通子图。所谓极小连通子图是指在包含所有顶点并且保证连通的前提下包含原图中最少的边。一棵具有 n 个顶点的连通图 G 的生成树有且仅有 n-1条边,如果少一条边就不是连通图,如果多一条边就一定有环。但是,有 n-1 条边的图不一定是生成树。图 6.7 就是图 6.3(a)的一棵生成树。
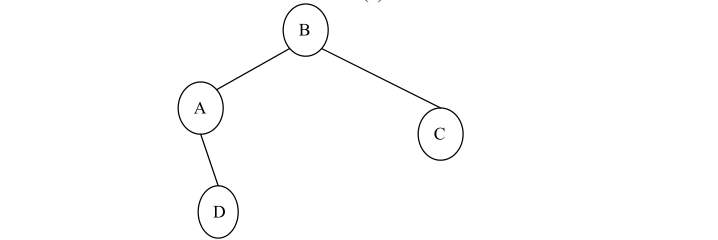
14、生成森林:在非连通图中,由每个连通分量都可得到一个极小连通子图,即一棵生成树。这些连通分量的生成树就组成了一个非连通图的生成森林(Spanning Forest)。
1.1.3:图的基本操作
图的基本操作用一个接口来表示,为表示图的基本操作,同时给出了顶点类的实现。由于顶点只保存自身信息,所以顶点类 Node<T>很简单,里面只有一个字段 data。
顶点的类 Node<T>的实现如下所示。


1 public class Node<T> 2 { 3 private T data; //数据域 4 //构造器 5 public Node(T v) 6 { 7 data = v; 8 } 9 //数据域属性 10 public T Data 11 { 12 get 13 { 14 return data; 15 } 16 set 17 { 18 data = value; 19 } 20 } 21 }
图的接口IGraph<T>的定义如下所示。
1 public interface IGraph<T> 2 { 3 //获取顶点数 4 int GetNumOfVertex(); 5 //获取边或弧的数目 6 int GetNumOfEdge(); 7 //在两个顶点之间添加权为v的边或弧 8 void SetEdge(Node<T> v1, Node<T> v2, int v); 9 //删除两个顶点之间的边或弧 10 void DelEdge(Node<T> v1, Node<T> v2); 11 //判断两个顶点之间是否有边或弧 12 bool IsEdge(Node<T> v1, Node<T> v2); 13 }
1.2:图的存储结构
图是一种复杂的数据结构,顶点之间是多对多的关系,即任意两个顶点之间都可能存在联系。所以,无法以顶点在存储区的位置关系来表示顶点之间的联系,即顺序存储结构不能完全存储图的信息,但可以用数组来存储图的顶点信息。要存储顶点之间的联系必须用链式存储结构或者二维数组。图的存储结构有多种,这里只介绍两种基本的存储结构:邻接矩阵和邻接表。
1.2.1: 邻接矩阵
邻接矩阵(Adjacency Matrix)是用两个数组来表示图,一个数组是一维数组,存储图中顶点的信息,一个数组是二维数组,即矩阵,存储顶点之间相邻的信息,也就是边(或弧)的信息,这是邻接矩阵名称的由来。
假设图G=(V, E)中有n个顶点,即V={v0,v1,…,vn-1},用矩阵A[i][j]表示边(或弧)的信息。矩阵A[i][j]是一个n×n的矩阵,矩阵的元素为:
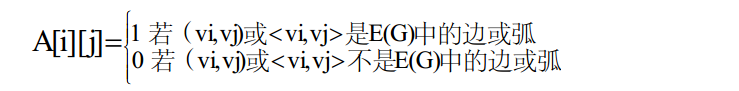
若 G 是网,则邻接矩阵可定义为:

其中, wij 表示边(vi,vj)或弧<vi,vj>上的权值;∞表示一个计算机允许的大于所有边上权值的数。
下面三张图分别对应邻接矩阵如下:




从图的邻接矩阵表示法可以看出这种表示法的特点是:
(1)无向图或无向网的邻接矩阵一定是一个对称矩阵。因此,在具体存放邻接矩阵时只需存放上(或下)三角矩阵的元素即可。
(2)可以很方便地查找图中任一顶点的度。对于无向图或无向网而言,顶点 vi 的度就是邻接矩阵中第 i 行或第 i 列中非 0 或非∞的元素的个数。对于有向图或有向网而言,顶点 vi 的入度是邻接矩阵中第 i 列中非 0 或非∞的元素的个数,顶点 vi 的出度是邻接矩阵中第 i 行中非 0 或非∞的元素的个数。
(3)可以很方便地查找图中任一条边或弧的权值,只要 A[i][j]为 0 或∞,就说明顶点 vi 和 vj 之间不存在边或弧。但是,要确定图中有多少条边或弧,则必须按行、按列对每个元素进行检测,所花费的时间代价是很大的。这是用邻接矩阵存储图的局限性。
无向图邻接矩阵类 GraphAdjMatrix<T>中有三个成员字段,一个是 Node<T>类型的一维数组 nodes,存放图中的顶点信息;一个是整型的二维数组 matirx,表示图的邻接矩阵,存放边的信息;一个是整数 numEdges,表示图中边的数目。因为图的邻接矩阵存储结构对于确定图中边或弧的数目要花费很大的时间代价,所以设了这个字段。
无向图邻接矩阵类 GraphAdjMatrix<T>的实现如下所示。
1 /// <summary> 2 /// 无向图邻接矩阵类 GraphAdjMatrix<T>的实现 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class GraphAdjMatrix<T> : IGraph<T> 6 { 7 private Node<T>[] nodes;//顶点数组 8 private int[,] matrix;//邻接矩阵数组 9 private int numEdges;//边的数目 10 11 public GraphAdjMatrix(int n) 12 { 13 nodes = new Node<T>[n]; 14 matrix = new int[n, n]; 15 numEdges = 0; 16 } 17 18 //获取索引为index的顶点的信息 19 public Node<T> GetNode(int index) 20 { 21 return nodes[index]; 22 } 23 24 //设置索引为index的顶点的信息 25 public void SetNode(int index, Node<T> v) 26 { 27 nodes[index] = v; 28 } 29 30 //获取matrix[index1, index2]的值 31 public int GetMatrix(int index1, int index2) 32 { 33 return matrix[index1, index2]; 34 } 35 36 //设置matrix[index1, index2]的值 37 public void SetMatrix(int index1, int index2) 38 { 39 matrix[index1, index2] = 1; 40 } 41 42 //边的数目属性 43 public int NumEdges 44 { 45 get { return numEdges; } 46 set { numEdges = value; } 47 } 48 49 //获取顶点的数目 50 public int GetNumOfVertex() 51 { 52 return nodes.Length; 53 } 54 55 //获取边的数目 56 public int GetNumOfEdge() 57 { 58 return numEdges; 59 } 60 61 //判断v是否是图的顶点 62 public bool IsNode(Node<T> v) 63 { 64 //遍历顶点数组 65 foreach (Node<T> nd in nodes) 66 { 67 //如果顶点nd与v相等,则v是图的顶点,返回true 68 if (v.Equals(nd)) 69 { 70 return true; 71 } 72 } 73 74 return false; 75 } 76 77 //获取顶点v在顶点数组中的索引 78 public int GetIndex(Node<T> v) 79 { 80 int i = -1; 81 //遍历顶点数组 82 for (i = 0; i < nodes.Length; ++i) 83 { 84 //如果顶点v与nodes[i]相等,则v是图的顶点,返回索引值i。 85 if (nodes[i].Equals(v)) 86 { 87 return i; 88 } 89 } 90 return i; 91 } 92 93 //在顶点v1和v2之间添加权值为v的边 94 public void SetEdge(Node<T> v1, Node<T> v2, int v) 95 { 96 if (!IsNode(v1) || !IsNode(v2)) 97 { 98 Console.WriteLine("Node is not belong to Graph!"); 99 return; 100 } 101 102 //不是无向图 103 if (v != 1) 104 { 105 Console.WriteLine("Weight is not right!"); 106 return; 107 } 108 109 //矩阵是对称矩阵 110 matrix[GetIndex(v1), GetIndex(v2)] = v; 111 matrix[GetIndex(v2), GetIndex(v1)] = v; 112 ++numEdges; 113 } 114 115 //删除顶点v1和v2之间的边 116 public void DelEdge(Node<T> v1, Node<T> v2) 117 { 118 //v1或v2不是图的顶点 119 if (!IsNode(v1) || !IsNode(v2)) 120 { 121 Console.WriteLine("Node is not belong to Graph!"); 122 return; 123 } 124 125 //顶点v1与v2之间存在边 126 if (matrix[GetIndex(v1), GetIndex(v2)] == 1) 127 { 128 //矩阵是对称矩阵 129 matrix[GetIndex(v1), GetIndex(v2)] = 0; 130 matrix[GetIndex(v2), GetIndex(v1)] = 0; 131 --numEdges; 132 } 133 } 134 135 //判断顶点v1与v2之间是否存在边 136 public bool IsEdge(Node<T> v1, Node<T> v2) 137 { 138 //v1或v2不是图的顶点 139 if (!IsNode(v1) || !IsNode(v2)) 140 { 141 Console.WriteLine("Node is not belong to Graph!"); 142 return false; 143 } 144 145 //顶点v1与v2之间存在边 146 if (matrix[GetIndex(v1), GetIndex(v2)] == 1) 147 { 148 return true; 149 } 150 else //不存在边 151 { 152 return false; 153 } 154 } 155 156 }
1.2.2: 邻接表
邻接表(Adjacency List)是图的一种顺序存储与链式存储相结合的存储结构,类似于树的孩子链表表示法。顺序存储指的是图中的顶点信息用一个顶点数组来存储,一个顶点数组元素是一个顶点结点,顶点结点有两个域,一个是数据域data,存放与顶点相关的信息,一个是引用域 firstAdj,存放该顶点的邻接表的第一个结点的地址。顶点的邻接表是把所有邻接于某顶点的顶点构成的一个表,它是采用链式存储结构。所以,我们说邻接表是图的一种顺序存储与链式存储相结合的存储结构。其中,邻接表中的每个结点实际上保存的是与该顶点相关的边或弧的信息,它有两个域,一个是邻接顶点域 adjvex,存放邻接顶点的信息,实际上就是邻接顶点在顶点数组中的序号;一个是引用域 next,存放下一个邻接顶点的结点的地址。顶点结点和邻接表结点的结构如下图所示。

而对于网的邻接表结点还需要存储边上的信息(如权值),所以结点应增设 一个域 info。网的邻接表结点的结构如下图 所示。
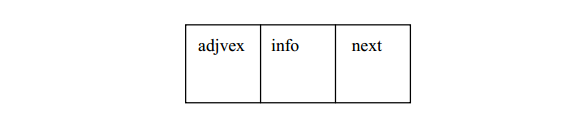
图 (a)的邻接表如下图 所示。
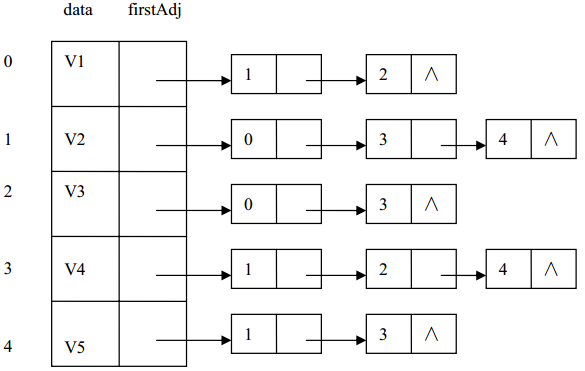
若无向图中有 n 个顶点和 e 条边,则它的邻接表需 n 个顶点结点和 2e 个邻接表结点,在边稀疏 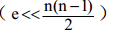 的情况下,用邻接表存储图比用邻接矩阵节省存储空间,当与边相关的信息较多时更是如此。
的情况下,用邻接表存储图比用邻接矩阵节省存储空间,当与边相关的信息较多时更是如此。
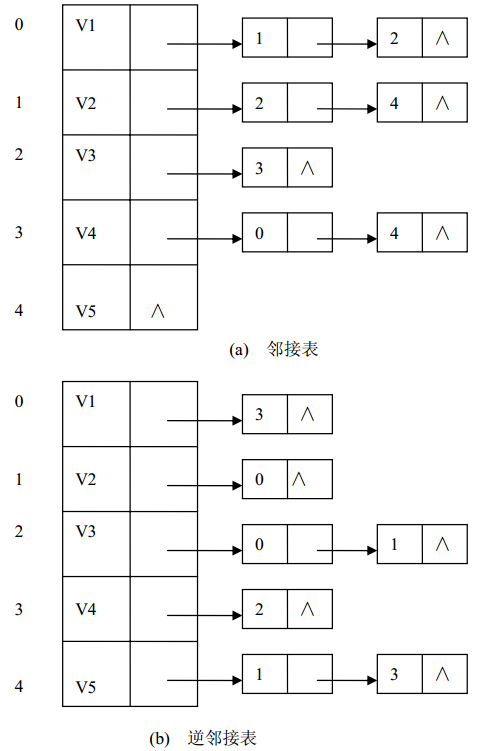
在无向图的邻接表中,顶点 vi 的度恰为第 i 个邻接表中的结点数;而在有向图中,第 i 的邻接表中的结点数只是顶点 vi 的出度,为求入度,必须遍历整个邻接表。在所有邻接表中其邻接顶点域的值为 i 的结点的个数是顶点 vi 的入度。有时,为了便于确定顶点的入度或者以顶点 vi 为头的弧,可以建立一个有向图的逆邻接表,即对每个顶点 vi 建立一个以 vi 为头的弧的邻接表。下图(b)是(a)邻接表和(b)逆邻接表。
在建立邻接表或逆邻接表时,若输入的顶点信息即为顶点的编号,则建立邻接表的时间复杂度为 O(n+e),否则,需要查找才能得到顶点在图中的位置,则时间复杂度为 O(n*e)。
在邻接表上很容易找到任一顶点的第一个邻接点和下一个邻接点。但要判定任意两个顶点(vi 和 v j)之间是否有边或弧相连,则需查找第 i 个或 j 个邻接表,因此,不如邻接矩阵方便。
下面以无向图邻接表类的实现来说明图的邻接表类的实现。
无向图邻接表的邻接表结点类 adjListNode<T>有两个成员字段,一个是adjvex,存储邻接顶点的信息,类型是整型;一个是 next,存储下一个邻接表结点的地址,类型是 adjListNode<T>。 adjListNode<T>的实现如下所示。
1 /// <summary> 2 /// 无向图邻接表类的实现 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class adjListNode<T> 6 { 7 private int adjvex;//邻接顶点 8 private adjListNode<T> next;//下一个邻接表结点 9 10 //邻接顶点属性 11 public int Adjvex 12 { 13 get { return adjvex; } 14 set { adjvex = value; } 15 } 16 17 //下一个邻接表结点属性 18 public adjListNode<T> Next 19 { 20 get { return next; } 21 set { next = value; } 22 } 23 24 public adjListNode(int vex) 25 { 26 adjvex = vex; 27 next = null; 28 } 29 }
无向图邻接表的顶点结点类 VexNode<T>有两个成员字段,一个 data,它存储图的顶点本身的信息,类型是 Node<T>;一个是 firstAdj, 存储顶点的邻接表的第 1 个结点的地址,类型是 adjListNode<T>。 VexNode<T>的实现如下所示。
1 /// <summary> 2 /// 无向图邻接表的顶点结点类 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class VexNode<T> 6 { 7 private Node<T> data; //图的顶点 8 private adjListNode<T> firstAdj; //邻接表的第1个结点 9 10 public Node<T> Data 11 { 12 get { return data; } 13 set { data = value; } 14 } 15 16 //邻接表的第1个结点属性 17 public adjListNode<T> FirstAdj 18 { 19 get { return firstAdj; } 20 set { firstAdj = value; } 21 } 22 23 //构造器 24 public VexNode() 25 { 26 data = null; 27 firstAdj = null; 28 } 29 30 //构造器 31 public VexNode(Node<T> nd) 32 { 33 data = nd; 34 firstAdj = null; 35 } 36 37 //构造器 38 public VexNode(Node<T> nd, adjListNode<T> alNode) 39 { 40 data = nd; 41 firstAdj = alNode; 42 } 43 }
无向图邻接表类 GraphAdjList<T>有一个成员字段 adjList, 表示邻接表数组,数组元素的类型是 VexNode<T>。 GraphAdjList<T>实现了接口 IGraph<T>中的方法。与无向图邻接矩阵类 GraphAdjMatrix<T>一样, GraphAdjList<T>实现了两个成员方法 IsNode 和 GetIndex。功能与 GraphAdjMatrix<T>一样。无向图邻接表类 GraphAdjList<T>的实现如下所示。
1 /// <summary> 2 /// 无向图邻接表类 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class GraphAdjList<T> : IGraph<T> 6 { 7 //邻接表数组 8 private VexNode<T>[] adjList; 9 10 //索引器 11 public VexNode<T> this[int index] 12 { 13 get 14 { 15 return adjList[index]; 16 } 17 set 18 { 19 adjList[index] = value; 20 } 21 } 22 23 //构造器 24 public GraphAdjList(Node<T>[] nodes) 25 { 26 adjList = new VexNode<T>[nodes.Length]; 27 for (int i = 0; i < nodes.Length; ++i) 28 { 29 adjList[i].Data = nodes[i]; 30 adjList[i].FirstAdj = null; 31 } 32 } 33 34 //获取顶点的数目 35 public int GetNumOfVertex() 36 { 37 return adjList.Length; 38 } 39 40 //获取边的数目 41 public int GetNumOfEdge() 42 { 43 int i = 0; 44 45 foreach (VexNode<T> nd in adjList) 46 { 47 adjListNode<T> p = nd.FirstAdj; 48 while (p != null) 49 { 50 ++i; 51 p = p.Next; 52 } 53 } 54 55 return i / 2;//无向图 56 } 57 58 //判断v是否是图的顶点 59 public bool IsNode(Node<T> v) 60 { 61 //遍历邻接表数组 62 foreach (VexNode<T> nd in adjList) 63 { 64 //如果v等于nd的data,则v是图中的顶点,返回true 65 if (v.Equals(nd.Data)) 66 { 67 return true; 68 } 69 } 70 return false; 71 } 72 73 //获取顶点v在邻接表数组中的索引 74 public int GetIndex(Node<T> v) 75 { 76 int i = -1; 77 //遍历邻接表数组 78 for (i = 0; i < adjList.Length; ++i) 79 { 80 //邻接表数组第i项的data值等于v,则顶点v的索引为i 81 if (adjList[i].Data.Equals(v)) 82 { 83 return i; 84 } 85 } 86 return i; 87 } 88 89 //判断v1和v2之间是否存在边 90 public bool IsEdge(Node<T> v1, Node<T> v2) 91 { 92 //v1或v2不是图的顶点 93 if (!IsNode(v1) || !IsNode(v2)) 94 { 95 Console.WriteLine("Node is not belong to Graph!"); 96 return false; 97 } 98 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 99 while (p != null) 100 { 101 if (p.Adjvex == GetIndex(v2)) 102 { 103 return true; 104 } 105 106 p = p.Next; 107 } 108 109 return false; 110 } 111 112 //在顶点v1和v2之间添加权值为v的边 113 public void SetEdge(Node<T> v1, Node<T> v2, int v) 114 { 115 //v1或v2不是图的顶点或者v1和v2之间存在边 116 if (!IsNode(v1) || !IsNode(v2) || IsEdge(v1, v2)) 117 { 118 Console.WriteLine("Node is not belong to Graph!"); 119 return; 120 } 121 122 //权值不对 123 if (v != 1) 124 { 125 Console.WriteLine("Weight is not right!"); 126 return; 127 } 128 129 //处理顶点v1的邻接表 130 adjListNode<T> p = new adjListNode<T>(GetIndex(v2)); 131 132 if (adjList[GetIndex(v1)].FirstAdj == null) 133 { 134 adjList[GetIndex(v1)].FirstAdj = p; 135 } 136 //顶点v1有邻接顶点 137 else 138 { 139 p.Next = adjList[GetIndex(v1)].FirstAdj; 140 adjList[GetIndex(v1)].FirstAdj = p; 141 } 142 143 //处理顶点v2的邻接表 144 p = new adjListNode<T>(GetIndex(v1)); 145 146 //顶点v2没有邻接顶点 147 if (adjList[GetIndex(v2)].FirstAdj == null) 148 { 149 adjList[GetIndex(v2)].FirstAdj = p; 150 } 151 152 //顶点v2有邻接顶点 153 else 154 { 155 p.Next = adjList[GetIndex(v2)].FirstAdj; 156 adjList[GetIndex(v2)].FirstAdj = p; 157 } 158 } 159 160 //删除顶点v1和v2之间的边 161 public void DelEdge(Node<T> v1, Node<T> v2) 162 { 163 //v1或v2不是图的顶点 164 if (!IsNode(v1) || !IsNode(v2)) 165 { 166 Console.WriteLine("Node is not belong to Graph!"); 167 return; 168 } 169 170 //顶点v1与v2之间有边 171 if (IsEdge(v1, v2)) 172 { 173 //处理顶点v1的邻接表中的顶点v2的邻接表结点 174 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 175 adjListNode<T> pre = null; 176 177 while (p != null) 178 { 179 if (p.Adjvex != GetIndex(v2)) 180 { 181 pre = p; 182 p = p.Next; 183 } 184 } 185 pre.Next = p.Next; 186 187 //处理顶点v2的邻接表中的顶点v1的邻接表结点 188 p = adjList[GetIndex(v2)].FirstAdj; 189 pre = null; 190 191 while (p != null) 192 { 193 if (p.Adjvex != GetIndex(v1)) 194 { 195 pre = p; 196 p = p.Next; 197 } 198 } 199 pre.Next = p.Next; 200 } 201 } 202 }
1.3:图的遍历
图的遍历是指从图中的某个顶点出发,按照某种顺序访问图中的每个顶点,使每个顶点被访问一次且仅一次。图的遍历与树的遍历操作功能相似。图的遍历是图的一种基本操作,图的许多其他操作都是建立在遍历操作的基础之上的。
然而,图的遍历要比树的遍历复杂得多。这是因为图中的顶点之间是多对多的关系,图中的任何一个顶点都可能和其它的顶点相邻接。所以,在访问了某个顶点之后,从该顶点出发,可能沿着某条路径遍历之后,又回到该顶点上。例如,在图 (b)的图中,由于图中存在回路,因此在访问了 v1、 v3、 v4 之后,沿着边<v4, v1>又回到了 v1 上。为了避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点。为此,可以设一个辅助数组 visited[n], n 为图中顶点的数目。数组中元素的初始值全为 0,表示顶点都没有被访问过,如果顶点vi 被访问, visited[i-1]为 1。
图的遍历有深度优先遍历和广度优先遍历两种方式,它们对图和网都适用。
1.3.1:深度优先遍历(DFS)
图的深度优先遍历(Depth_First Search)类似于树的先序遍历,是树的先序遍历的推广。
假设初始状态是图中所有顶点未曾被访问过,则深度优先遍历可从图中某个顶点 v 出发,访问此顶点,然后依次从 v 的未被访问的邻接顶点出发深度优先遍历图,直至图中所有和 v 有路径相通的顶点都被遍历过。若此时图中尚有未被访问的顶点,则另选图中一个未被访问的顶点作为起始点,重复上述过程,直到图中所有顶点都被访问到为止。
按深度优先遍历算法对图 (a)进行遍历。
图 6.13(a)所示的无向图的深度优先遍历的过程如图 6.13(b)所示。假设从顶点 v1 出发,在访问了顶点 v1 之后,选择邻接顶点 v2,因为 v2 未被访问过,所以从 v2 出发进行深度优先遍历。依次类推,接着从 v4、 v8、 v5 出发进行深度优先遍历。当访问了 v5 之后,由于 v5 的邻接顶点 v2 和 v8 都已被访问,所以遍历退回到 v8。由于同样的理由,遍历继续退回到 v4、 v2 直到 v1。由于 v1 的另一个邻接顶点 v3 未被访问,所以又从 v3 开始进行深度优先遍历,这样得到该图的深度优先遍历的顶点序列为 v1→v2→v4→v8→v5→v3→v6→v7。
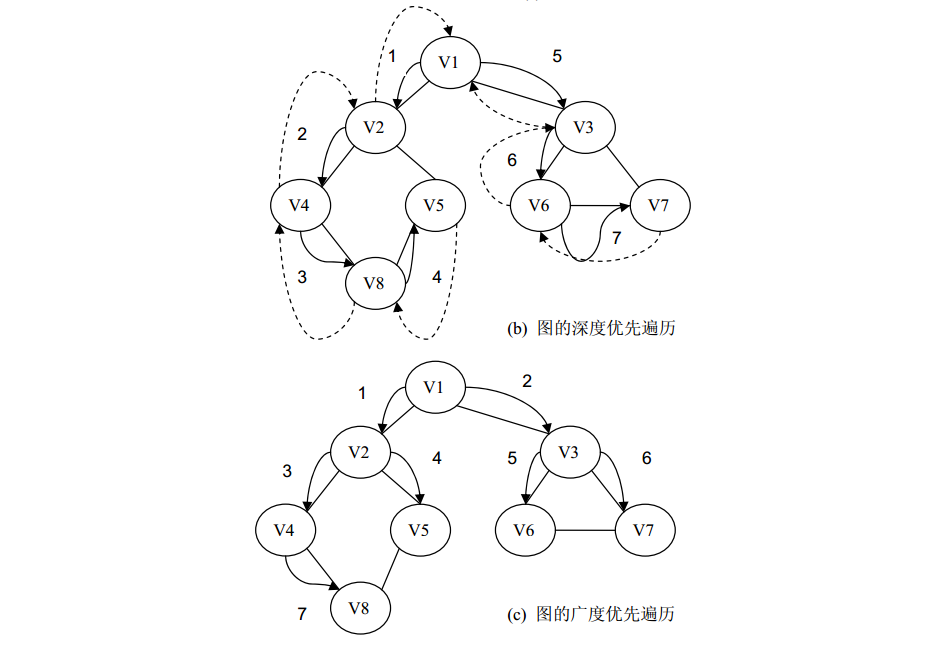
显然,这是一个递归的过程。下面以无向图的邻接表存储结构为例来实现图的深度优先遍历算法。在类中增设了一个整型数组的成员字段 visited,它的初始值全为 0,表示图中所有的顶点都没有被访问过。如果顶点 vi 被访问, visited[i-1]为 1。并且,把该算法作为无向图的邻接表类 GraphAdjList<T>的成员方法。
对无向图的邻接表类 GraphAdjList<T>进行修改后的算法实现如下:
1 /// <summary> 2 /// 无向图邻接表类 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class GraphAdjList<T> : IGraph<T> 6 { 7 //邻接表数组 8 private VexNode<T>[] adjList; 9 10 //记录图中所有顶点的访问情况 11 private int[] visited; 12 13 //索引器 14 public VexNode<T> this[int index] 15 { 16 get 17 { 18 return adjList[index]; 19 } 20 set 21 { 22 adjList[index] = value; 23 } 24 } 25 26 //构造器 27 public GraphAdjList(Node<T>[] nodes) 28 { 29 adjList = new VexNode<T>[nodes.Length]; 30 for (int i = 0; i < nodes.Length; ++i) 31 { 32 adjList[i].Data = nodes[i]; 33 adjList[i].FirstAdj = null; 34 } 35 36 visited = new int[adjList.Length]; 37 for (int i = 0; i < visited.Length; ++i) 38 { 39 visited[i] = 0; 40 } 41 } 42 43 //获取顶点的数目 44 public int GetNumOfVertex() 45 { 46 return adjList.Length; 47 } 48 49 //获取边的数目 50 public int GetNumOfEdge() 51 { 52 int i = 0; 53 54 foreach (VexNode<T> nd in adjList) 55 { 56 adjListNode<T> p = nd.FirstAdj; 57 while (p != null) 58 { 59 ++i; 60 p = p.Next; 61 } 62 } 63 64 return i / 2;//无向图 65 } 66 67 //判断v是否是图的顶点 68 public bool IsNode(Node<T> v) 69 { 70 //遍历邻接表数组 71 foreach (VexNode<T> nd in adjList) 72 { 73 //如果v等于nd的data,则v是图中的顶点,返回true 74 if (v.Equals(nd.Data)) 75 { 76 return true; 77 } 78 } 79 return false; 80 } 81 82 //获取顶点v在邻接表数组中的索引 83 public int GetIndex(Node<T> v) 84 { 85 int i = -1; 86 //遍历邻接表数组 87 for (i = 0; i < adjList.Length; ++i) 88 { 89 //邻接表数组第i项的data值等于v,则顶点v的索引为i 90 if (adjList[i].Data.Equals(v)) 91 { 92 return i; 93 } 94 } 95 return i; 96 } 97 98 //判断v1和v2之间是否存在边 99 public bool IsEdge(Node<T> v1, Node<T> v2) 100 { 101 //v1或v2不是图的顶点 102 if (!IsNode(v1) || !IsNode(v2)) 103 { 104 Console.WriteLine("Node is not belong to Graph!"); 105 return false; 106 } 107 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 108 while (p != null) 109 { 110 if (p.Adjvex == GetIndex(v2)) 111 { 112 return true; 113 } 114 115 p = p.Next; 116 } 117 118 return false; 119 } 120 121 //在顶点v1和v2之间添加权值为v的边 122 public void SetEdge(Node<T> v1, Node<T> v2, int v) 123 { 124 //v1或v2不是图的顶点或者v1和v2之间存在边 125 if (!IsNode(v1) || !IsNode(v2) || IsEdge(v1, v2)) 126 { 127 Console.WriteLine("Node is not belong to Graph!"); 128 return; 129 } 130 131 //权值不对 132 if (v != 1) 133 { 134 Console.WriteLine("Weight is not right!"); 135 return; 136 } 137 138 //处理顶点v1的邻接表 139 adjListNode<T> p = new adjListNode<T>(GetIndex(v2)); 140 141 if (adjList[GetIndex(v1)].FirstAdj == null) 142 { 143 adjList[GetIndex(v1)].FirstAdj = p; 144 } 145 //顶点v1有邻接顶点 146 else 147 { 148 p.Next = adjList[GetIndex(v1)].FirstAdj; 149 adjList[GetIndex(v1)].FirstAdj = p; 150 } 151 152 //处理顶点v2的邻接表 153 p = new adjListNode<T>(GetIndex(v1)); 154 155 //顶点v2没有邻接顶点 156 if (adjList[GetIndex(v2)].FirstAdj == null) 157 { 158 adjList[GetIndex(v2)].FirstAdj = p; 159 } 160 161 //顶点v2有邻接顶点 162 else 163 { 164 p.Next = adjList[GetIndex(v2)].FirstAdj; 165 adjList[GetIndex(v2)].FirstAdj = p; 166 } 167 } 168 169 //删除顶点v1和v2之间的边 170 public void DelEdge(Node<T> v1, Node<T> v2) 171 { 172 //v1或v2不是图的顶点 173 if (!IsNode(v1) || !IsNode(v2)) 174 { 175 Console.WriteLine("Node is not belong to Graph!"); 176 return; 177 } 178 179 //顶点v1与v2之间有边 180 if (IsEdge(v1, v2)) 181 { 182 //处理顶点v1的邻接表中的顶点v2的邻接表结点 183 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 184 adjListNode<T> pre = null; 185 186 while (p != null) 187 { 188 if (p.Adjvex != GetIndex(v2)) 189 { 190 pre = p; 191 p = p.Next; 192 } 193 } 194 pre.Next = p.Next; 195 196 //处理顶点v2的邻接表中的顶点v1的邻接表结点 197 p = adjList[GetIndex(v2)].FirstAdj; 198 pre = null; 199 200 while (p != null) 201 { 202 if (p.Adjvex != GetIndex(v1)) 203 { 204 pre = p; 205 p = p.Next; 206 } 207 } 208 pre.Next = p.Next; 209 } 210 } 211 212 //无向图的深度优先遍历算法的实现 213 public void DFS() 214 { 215 for (int i = 0; i < visited.Length; ++i) 216 { 217 if (visited[i] == 0) 218 { 219 DFSAL(i); 220 } 221 } 222 } 223 224 //从某个顶点出发进行深度优先遍历 225 public void DFSAL(int i) 226 { 227 visited[i] = 1; 228 adjListNode<T> p = adjList[i].FirstAdj; 229 while (p != null) 230 { 231 if (visited[p.Adjvex] == 0) 232 { 233 DFSAL(p.Adjvex); 234 } 235 p = p.Next; 236 } 237 238 } 239 }
分析上面的算法,在遍历图时,对图中每个顶点至多调用一次DFS方法,因为一旦某个顶点被标记成已被访问,就不再从它出发进行遍历。因此,遍历图的过程实质上是对每个顶点查找其邻接顶点的过程。其时间复杂度取决于所采用的存储结构。当图采用邻接矩阵作为存储结构时,查找每个顶点的邻接顶点的时间复杂度为O(n2),其中,n为图的顶点数。而以邻接表作为图的存储结构时,查找邻接顶点的时间复杂度为O(e),其中,e为图中边或弧的数目。因此,当以邻接表作为存储结构时,深度优先遍历图的时间复杂度为O(n+e)。
1.3.2:广度优先遍历(BFS)
图的广度优先遍历(Breadth_First Search)类似于树的层序遍历。
假设从图中的某个顶点 v 出发,访问了 v 之后,依次访问 v 的各个未曾访问的邻接顶点。然后分别从这些邻接顶点出发依次访问它们的邻接顶点,并使“先被访问的顶点的邻接顶点”先于“后被访问的顶点的邻接顶点”被访问,直至图中所有已被访问的顶点的邻接顶点都被访问。若此时图中尚有顶点未被访问,则另选图中未被访问的顶点作为起点,重复上述过程,直到图中所有的顶点都被访问为止。换句话说,广度优先遍历图的过程是以某个顶点 v 作为起始点,由近至远,依次访问和 v 有路径相通且路径长度为 1, 2,…的顶点。
按广度优先遍历算法对上图 (a)进行遍历
上图 (a)所示的无向图的广度优先遍历的过程如上图 (c)所示。假设从顶点 v1 开始进行广度优先遍历,首先访问顶点 v1 和它的邻接顶点 v2 和 v3,然后依次访问 v2 的邻接顶点 v4 和 v5,以及 v3 的邻接顶点 v6 和 v7,最后访问 v4的邻接顶点 v8。由于这些顶点的邻接顶点都已被访问,并且图中所有顶点都已被访问,由此完成了图的遍历,得到的顶点访问序列为: v1→v2→v3→v4→v5→v6→v7→v8,其遍历过程如图 (c)所示。
和深度优先遍历类似,在广度优先遍历中也需要一个访问标记数组,我们采用与深度优先遍历同样的数组。并且,为了顺序访问路径长度为 1, 2,…的顶点,需在算法中附设一个队列来存储已被访问的路径长度为 1, 2,…的顶点。
以邻接表作为存储结构的无向图的广度优先遍历算法的实现如下,队列是循环顺序队列。
对无向图的邻接表类 GraphAdjList<T>进行修改后的算法实现如下:
1 /// <summary> 2 /// 无向图邻接表类 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class GraphAdjList<T> : IGraph<T> 6 { 7 //邻接表数组 8 private VexNode<T>[] adjList; 9 10 //记录图中所有顶点的访问情况 11 private int[] visited; 12 13 //索引器 14 public VexNode<T> this[int index] 15 { 16 get 17 { 18 return adjList[index]; 19 } 20 set 21 { 22 adjList[index] = value; 23 } 24 } 25 26 //构造器 27 public GraphAdjList(Node<T>[] nodes) 28 { 29 adjList = new VexNode<T>[nodes.Length]; 30 for (int i = 0; i < nodes.Length; ++i) 31 { 32 adjList[i].Data = nodes[i]; 33 adjList[i].FirstAdj = null; 34 } 35 36 visited = new int[adjList.Length]; 37 for (int i = 0; i < visited.Length; ++i) 38 { 39 visited[i] = 0; 40 } 41 } 42 43 //获取顶点的数目 44 public int GetNumOfVertex() 45 { 46 return adjList.Length; 47 } 48 49 //获取边的数目 50 public int GetNumOfEdge() 51 { 52 int i = 0; 53 54 foreach (VexNode<T> nd in adjList) 55 { 56 adjListNode<T> p = nd.FirstAdj; 57 while (p != null) 58 { 59 ++i; 60 p = p.Next; 61 } 62 } 63 64 return i / 2;//无向图 65 } 66 67 //判断v是否是图的顶点 68 public bool IsNode(Node<T> v) 69 { 70 //遍历邻接表数组 71 foreach (VexNode<T> nd in adjList) 72 { 73 //如果v等于nd的data,则v是图中的顶点,返回true 74 if (v.Equals(nd.Data)) 75 { 76 return true; 77 } 78 } 79 return false; 80 } 81 82 //获取顶点v在邻接表数组中的索引 83 public int GetIndex(Node<T> v) 84 { 85 int i = -1; 86 //遍历邻接表数组 87 for (i = 0; i < adjList.Length; ++i) 88 { 89 //邻接表数组第i项的data值等于v,则顶点v的索引为i 90 if (adjList[i].Data.Equals(v)) 91 { 92 return i; 93 } 94 } 95 return i; 96 } 97 98 //判断v1和v2之间是否存在边 99 public bool IsEdge(Node<T> v1, Node<T> v2) 100 { 101 //v1或v2不是图的顶点 102 if (!IsNode(v1) || !IsNode(v2)) 103 { 104 Console.WriteLine("Node is not belong to Graph!"); 105 return false; 106 } 107 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 108 while (p != null) 109 { 110 if (p.Adjvex == GetIndex(v2)) 111 { 112 return true; 113 } 114 115 p = p.Next; 116 } 117 118 return false; 119 } 120 121 //在顶点v1和v2之间添加权值为v的边 122 public void SetEdge(Node<T> v1, Node<T> v2, int v) 123 { 124 //v1或v2不是图的顶点或者v1和v2之间存在边 125 if (!IsNode(v1) || !IsNode(v2) || IsEdge(v1, v2)) 126 { 127 Console.WriteLine("Node is not belong to Graph!"); 128 return; 129 } 130 131 //权值不对 132 if (v != 1) 133 { 134 Console.WriteLine("Weight is not right!"); 135 return; 136 } 137 138 //处理顶点v1的邻接表 139 adjListNode<T> p = new adjListNode<T>(GetIndex(v2)); 140 141 if (adjList[GetIndex(v1)].FirstAdj == null) 142 { 143 adjList[GetIndex(v1)].FirstAdj = p; 144 } 145 //顶点v1有邻接顶点 146 else 147 { 148 p.Next = adjList[GetIndex(v1)].FirstAdj; 149 adjList[GetIndex(v1)].FirstAdj = p; 150 } 151 152 //处理顶点v2的邻接表 153 p = new adjListNode<T>(GetIndex(v1)); 154 155 //顶点v2没有邻接顶点 156 if (adjList[GetIndex(v2)].FirstAdj == null) 157 { 158 adjList[GetIndex(v2)].FirstAdj = p; 159 } 160 161 //顶点v2有邻接顶点 162 else 163 { 164 p.Next = adjList[GetIndex(v2)].FirstAdj; 165 adjList[GetIndex(v2)].FirstAdj = p; 166 } 167 } 168 169 //删除顶点v1和v2之间的边 170 public void DelEdge(Node<T> v1, Node<T> v2) 171 { 172 //v1或v2不是图的顶点 173 if (!IsNode(v1) || !IsNode(v2)) 174 { 175 Console.WriteLine("Node is not belong to Graph!"); 176 return; 177 } 178 179 //顶点v1与v2之间有边 180 if (IsEdge(v1, v2)) 181 { 182 //处理顶点v1的邻接表中的顶点v2的邻接表结点 183 adjListNode<T> p = adjList[GetIndex(v1)].FirstAdj; 184 adjListNode<T> pre = null; 185 186 while (p != null) 187 { 188 if (p.Adjvex != GetIndex(v2)) 189 { 190 pre = p; 191 p = p.Next; 192 } 193 } 194 pre.Next = p.Next; 195 196 //处理顶点v2的邻接表中的顶点v1的邻接表结点 197 p = adjList[GetIndex(v2)].FirstAdj; 198 pre = null; 199 200 while (p != null) 201 { 202 if (p.Adjvex != GetIndex(v1)) 203 { 204 pre = p; 205 p = p.Next; 206 } 207 } 208 pre.Next = p.Next; 209 } 210 } 211 212 //无向图的深度优先遍历算法的实现 213 public void DFS() 214 { 215 for (int i = 0; i < visited.Length; ++i) 216 { 217 if (visited[i] == 0) 218 { 219 DFSAL(i); 220 } 221 } 222 } 223 224 //从某个顶点出发进行深度优先遍历 225 public void DFSAL(int i) 226 { 227 visited[i] = 1; 228 adjListNode<T> p = adjList[i].FirstAdj; 229 while (p != null) 230 { 231 if (visited[p.Adjvex] == 0) 232 { 233 DFSAL(p.Adjvex); 234 } 235 p = p.Next; 236 } 237 238 } 239 240 //无向图的广度优先遍历算法的实现 241 public void BFS() 242 { 243 for (int i = 0; i < visited.Length; ++i) 244 { 245 if (visited[i] == 0) 246 { 247 BFSAL(i); 248 } 249 } 250 } 251 252 //从某个顶点出发进行广度优先遍历 253 public void BFSAL(int i) 254 { 255 visited[i] = 1; 256 CSeqQueue<int> cq = new CSeqQueue<int>(visited.Length); 257 cq.In(i); 258 while (!cq.IsEmpty()) 259 { 260 int k = cq.Out(); 261 adjListNode<T> p = adjList[k].FirstAdj; 262 263 while(p != null) 264 { 265 if (visited[p.Adjvex] == 0) 266 { 267 visited[p.Adjvex] = 1; 268 cq.In(p.Adjvex); 269 } 270 271 p = p.Next; 272 } 273 } 274 } 275 }
分析上面的算法,每个顶点至多入队列一次。遍历图的过程实质上是通过边或弧查找邻接顶点的过程,因此,广度优先遍历算法的时间复杂度与深度优先遍历相同,两者的不同之处在于对顶点的访问顺序不同。
1.4:图的应用
1.4.1:最小生成树
1、 最小生成树的基本概念
由生成树的定义可知,无向连通图的生成树不是唯一的,对连通图的不同遍历就得到不同的生成树。下图所示是图 (a)所示的无向连通图的部分生成树。

如果是一个无向连通网,那么它的所有生成树中必有一棵边的权值总和最小的生成树,我们称这棵生成树为最小代价生成树(Minimum Cost Spanning Tree),简称最小生成树。
许多应用问题都是一个求无向连通网的最小生成树问题。例如,要在 n 个城市之间铺设光缆,铺设光缆的费用很高,并且各个城市之间铺设光缆的费用不同。一个目标是要使这 n 个城市的任意两个之间都可以直接或间接通信,另一个目标是要使铺设光缆的总费用最低。如果把 n 个城市看作是图的 n 个顶点,两个城市之间铺设的光缆看作是两个顶点之间的边,这实际上就是求一个无向连通网的最小生成树问题。
由最小生成树的定义可知,构造有 n 个顶点的无向连通网的最小生成树必须满足以下三个条件:
(1)构造的最小生成树必须包括 n 个顶点;
(2)构造的最小生成树有且仅有 n-1 条边;
(3)构造的最小生成树中不存在回路。
构造最小生成树的方法有许多种,典型的方法有两种,一种是普里姆(Prim)算法,一种是克鲁斯卡尔(Kruskal)算法。
2、 普里姆(Prim)算法
假设 G=(V, E)为一无向连通网,其中, V 为网中顶点的集合, E 为网中边的集合。设置两个新的集合 U 和 T,其中, U 为 G 的最小生成树的顶点的集合, T 为 G 的最小生成树的边的集合。普里姆算法的思想是:令集合 U 的初值为 U={u1}(假设构造最小生成树时从顶点 u1 开始),集合 T 的初值为 T={}。从所有的顶点 u∈U 和顶点 v∈V-U 的带权边中选出具有最小权值的边(u,v),将顶点 v 加入集合 U 中,将边(u,v)加入集合 T 中。如此不断地重复直到 U=V 时,最小生成树构造完毕。此时,集合 U 中存放着最小生成树的所有顶点,集合 T中存放着最小生成树的所有边。
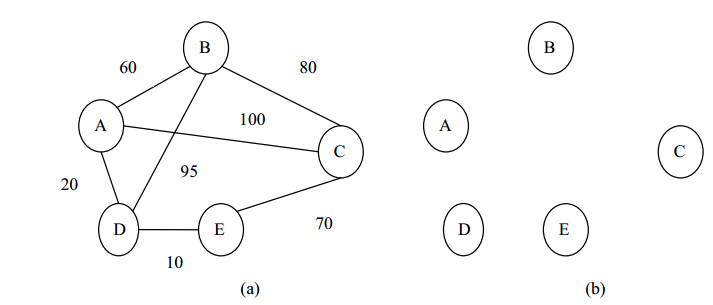
以下图(a)为例,说明用普里姆算法构造图的无向连通网的最小生成树的过程。
为了分析问题的方便,把图 (a)中所示的无向连通网重新画在下图 中,如图 (a)所示。初始时,算法的集合 U={A},集合 V-U={B,C,D,E},集合 T={},如图 (b)所示。在所有 u 为集合 U 中顶点、 v 为集合 V-U 中顶点的边(u,v)中寻找具有最小权值的边,寻找到的边是(A,D),权值为 20,把顶点 B 加入到集合U 中,把边(A,D)加入到集合 T 中,如图 (c)所示。在所有 u 为集合 U 中顶点、v 为集合 V-U 中顶点的边(u,v)中寻找具有最小权值的边,寻找到的边是(D,E),权值为 10,把顶点 E 加入到集合 U 中,把边(D,E)加入到集合 T 中,如图 (d)所示。随后依次从集合 V-U 中加入到集合 U 中的顶点为 B、 C,依次加入到集合T 中的边为(A,B)(权值为 60)、 (E,C) (权值为 70),分别如图 (e)、 (f)所示。最后得到的图 (f)所示就是原无向连通网的最小生成树。

本 文以 无 向 网 的 邻 接 矩 阵 类 NetAdjMatrix<T> 来 实 现 普 里 姆 算 法 。NetAdjMatrix<T>类的成员字段与无向图邻接矩阵类 GraphAdjMatrix<T>的成员字段一样,不同的是,当两个顶点间有边相连接时, matirx 数组中相应元素的值是边的权值,而不是 1。
无向网邻接矩阵类 NetAdjMatrix<T>的实现如下所示。
1 /// <summary> 2 /// 无向网邻接矩阵类 NetAdjMatrix<T>的实现如下所示。 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class NetAdjMatrix<T> : IGraph<T> 6 { 7 private Node<T>[] nodes;//顶点数组 8 private int numEdges;//边的数目 9 private int[,] matrix;//邻接矩阵数组 10 11 public NetAdjMatrix(int n) 12 { 13 nodes = new Node<T>[n]; 14 matrix = new int[n, n]; 15 numEdges = 0; 16 } 17 18 //获取索引为index的顶点的信息 19 public Node<T> GetNode(int index) 20 { 21 return nodes[index]; 22 } 23 24 //设置索引为index的顶点的信息 25 public void SetNode(int index, Node<T> v) 26 { 27 nodes[index] = v; 28 } 29 30 //获取matrix[index1, index2]的值 31 public int GetMatrix(int index1, int index2) 32 { 33 return matrix[index1, index2]; 34 } 35 36 //设置matrix[index1, index2]的值 37 public void SetMatrix(int index1, int index2, int v) 38 { 39 matrix[index1, index2] = v; 40 } 41 42 //边的数目属性 43 public int NumEdges 44 { 45 get { return numEdges; } 46 set { numEdges = value; } 47 } 48 49 //获取顶点的数目 50 public int GetNumOfVertex() 51 { 52 return nodes.Length; 53 } 54 55 //获取边的数目 56 public int GetNumOfEdge() 57 { 58 return numEdges; 59 } 60 61 //判断v是否是网的顶点 62 public bool IsNode(Node<T> v) 63 { 64 //遍历顶点数组 65 foreach (Node<T> nd in nodes) 66 { 67 //如果顶点nd与v相等,则v是图的顶点,返回true 68 if (v.Equals(nd)) 69 { 70 return true; 71 } 72 } 73 74 return false; 75 } 76 77 //获取顶点v在顶点数组中的索引 78 public int GetIndex(Node<T> v) 79 { 80 int i = -1; 81 82 //遍历顶点数组 83 for (i = 0; i < nodes.Length; ++i) 84 { 85 //如果顶点v与nodes[i]相等,则v是网的顶点,返回索引值i。 86 if (nodes[i].Equals(v)) 87 { 88 return i; 89 } 90 } 91 return i; 92 } 93 94 //在顶点v1和v2之间添加权值为v的边 95 public void SetEdge(Node<T> v1, Node<T> v2, int v) 96 { 97 if (!IsNode(v1) || !IsNode(v2)) 98 { 99 Console.WriteLine("Node is not belong to Net!"); 100 return; 101 } 102 103 //矩阵是对称矩阵 104 matrix[GetIndex(v1), GetIndex(v2)] = v; 105 matrix[GetIndex(v2), GetIndex(v1)] = v; 106 ++numEdges; 107 } 108 109 //删除顶点v1和v2之间的边 110 public void DelEdge(Node<T> v1, Node<T> v2) 111 { 112 //v1或v2不是无线网的顶点 113 if (!IsNode(v1) || !IsNode(v2)) 114 { 115 Console.WriteLine("Node is not belong to Net!"); 116 return; 117 } 118 119 //顶点v1与v2之间存在边 120 if (matrix[GetIndex(v1), GetIndex(v2)] != int.MaxValue) 121 { 122 //矩阵是对称矩阵 123 matrix[GetIndex(v1), GetIndex(v2)] = 0; 124 matrix[GetIndex(v2), GetIndex(v1)] = 0; 125 --numEdges; 126 } 127 } 128 129 //判断顶点v1与v2之间是否存在边 130 public bool IsEdge(Node<T> v1, Node<T> v2) 131 { 132 //v1或v2不是无向网的顶点 133 if (!IsNode(v1) || !IsNode(v2)) 134 { 135 Console.WriteLine("Node is not belong to Net!"); 136 return false; 137 } 138 139 //顶点v1与v2之间存在边 140 if (matrix[GetIndex(v1), GetIndex(v2)] != int.MaxValue) 141 { 142 return true; 143 } 144 else //不存在边 145 { 146 return false; 147 } 148 } 149 }
为实现普里姆算法,需要设置两个辅助一维数组 lowcost 和 closevex, lowcost用来保存集合 V-U 中各顶点与集合 U 中各顶点构成的边中具有最小权值的边的权值; closevex 用来保存依附于该边的在集合 U 中的顶点。假设初始状态时,U={u1}(u1 为出发的顶点),这时有 lowcost[0]=0,它表示顶点 u1 已加入集合 U中。数组 lowcost 元素的值是顶点 u1 到其他顶点所构成的直接边的权值。然后不断选取权值最小的边(ui,uk)(ui∈U,uk∈V-U),每选取一条边,就将 lowcost[k]置为 0,表示顶点 uk 已加入集合 U 中。由于顶点 uk 从集合 V-U 进入集合 U 后,这两个集合的内容发生了变化,就需要依据具体情况更新数组 lowcost 和 closevex中部分元素的值。把普里姆算法 Prim 作为 NetAdjMatrix<T>类的成员方法。
普里姆算法 Prim 的实现如下:
1 public int[] Prim() 2 { 3 int[] lowcost = new int[nodes.Length];//权值数组 4 int[] closevex = new int[nodes.Length];//顶点数组 5 int mincost = int.MaxValue;//最小权值 6 7 //辅助数组初始化 8 for (int i = 1; i < nodes.Length; ++i) 9 { 10 lowcost[i] = matrix[0, i]; 11 closevex[i] = 0; 12 } 13 14 //某个顶点加入集合U 15 lowcost[0] = 0; 16 closevex[0] = 0; 17 18 for (int i = 0; i < nodes.Length; ++i) 19 { 20 int k = 1; 21 int j = 1; 22 //选取权值最小的边和相应的顶点 23 while (j < nodes.Length) 24 { 25 if (lowcost[j] < mincost && lowcost[j] != 0) 26 { 27 k = j; 28 } 29 ++j; 30 } 31 //新顶点加入集合U 32 lowcost[k] = 0; 33 //重新计算该顶点到其余顶点的边的权值 34 for (j = 1; j < nodes.Length; ++j) 35 { 36 if (matrix[k, j] < lowcost[j]) 37 { 38 lowcost[j] = matrix[k, j]; 39 closevex[j] = k; 40 } 41 } 42 } 43 44 return closevex; 45 }
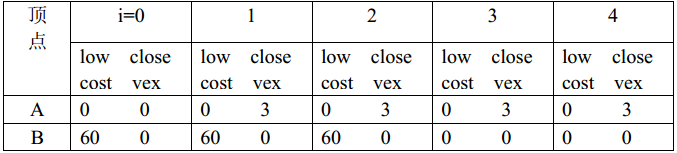
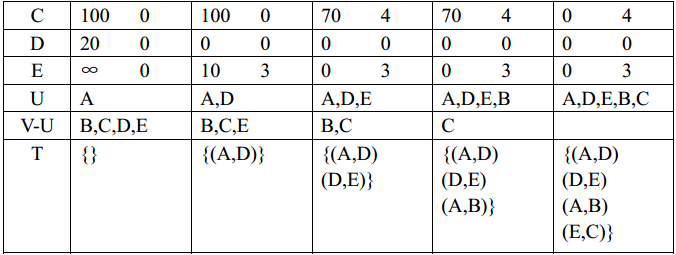
下表给出了在用普里姆算法构造图 (a)的最小生成树的过程中数组closevex 和 lowcost 及集合 U, V-U 的变化情况,读者可进一步加深对普里姆算法的理解。
在普里姆算法中,第一个for循环的执行次数为n-1,第二个for循环中又包括了一个while循环和一个for循环,执行次数为 2(n-1)2,所以普里姆算法的时间复杂度为O(n2)。
下表在用普里姆算法构造图 (a)的最小生成树的过程中参数变化
3、 克鲁斯卡尔(Kruskal)算法
克鲁斯卡尔算法的基本思想是:对一个有 n 个顶点的无向连通网,将图中的边按权值大小依次选取,若选取的边使生成树不形成回路,则把它加入到树中;若形成回路,则将它舍弃。如此进行下去,直到树中包含有 n-1 条边为止。
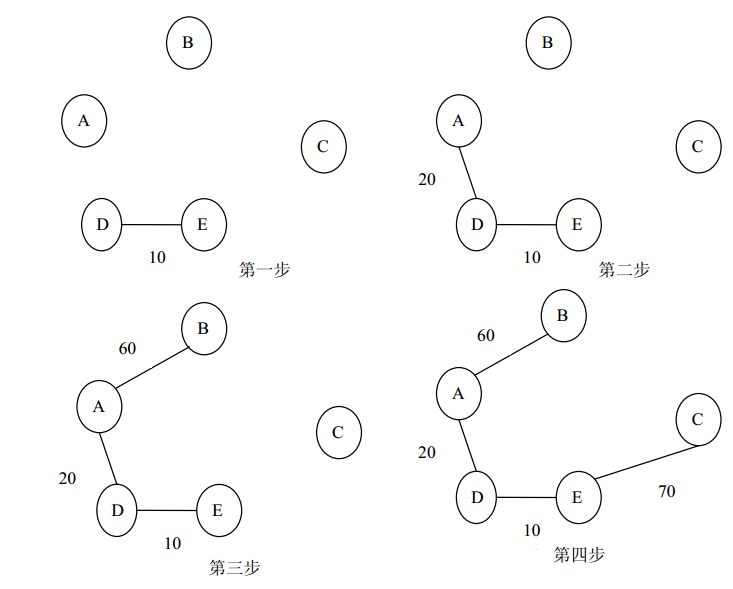
以(a)为例说明用克鲁斯卡尔算法求无向连通网最小生成树的过程。
第一步:首先比较网中所有边的权值,找到最小的权值的边(D,E),加入到生成树的边集 TE 中, TE={(D,E)}。
第二步:再比较图中除边(D,E)的边的权值,又找到最小权值的边(A,D)并且不会形成回路,加入到生成树的边集 TE 中, TE={(A,D),(D,E)}。
第三步:再比较图中除 TE 以外的所有边的权值,找到最小的权值的边(A,B)并且不会形成回路,加入到生成树的边集 TE 中, TE={(A,D),(D,E),(A,B)}。
第四步:再比较图中除 TE 以外的所有边的权值,找到最小的权值的边(E,C)并且不会形成回路,加入到生成树的边集 TE 中, TE={(A,D),(D,E),(A,B),(E,C)}。
此时,边集 TE 中已经有 n-1 条边,所以求图 (a)的无向连通网的最小生成树的过程已经完成,如下图所示。这个结果与用普里姆算法得到的结果相同。
1.4.2:最短路径
1、 最短路径的概念
最短路径问题是图的又一个比较典型的应用问题。例如, n 个城市之间的一个公路网,给定这些城市之间的公路的距离,能否找到城市 A 到城市 B 之间一条距离最近的通路呢?如果城市用顶点表示,城市间的公路用边表示,公路的长度作为边的权值。那么,这个问题就可归结为在网中求顶点 A 到顶点 B 的所有路径中边的权值之和最小的那一条路径,这条路径就是两个顶点之间的最短路径(Shortest Path),并称路径上的第一个顶点为源点(Source),最后一个顶点为终点(Destination)。在不带权的图中,最短路径是指两个顶点之间经历的边数最少的路径。
网分为无向网和有向网,当把无向网中的每一条边(vi,vj)都定义为弧<vi,vj>和弧<vj,vi>,则有向网就变成了无向网。因此,不失一般性,我们这里只讨论有向网上的最短路径问题。
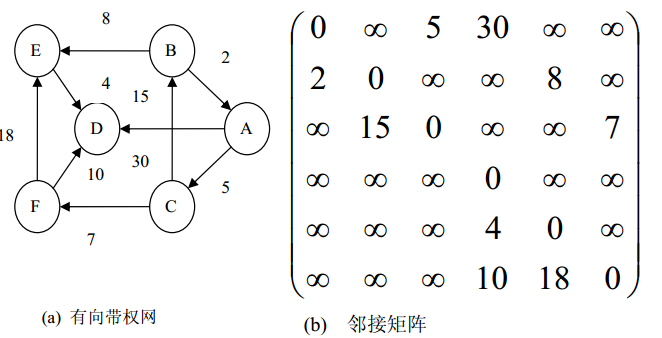
下图 是一个有向网及其邻接矩阵。该网从顶点 A 到顶点 D 有 4 条路径,分别是:路径(A,D),其带权路径长度为 30;路径(A,C,F,D),其带权路径长度为 22;路径(A,C,B,E,D),其带权路径长度为 32;路径(A,C,F,E,D),其带权路径长度为 34。路径(A,C,F,D)称为最短路径,其带权路径长度 22 称为最短距离。
2、 狄克斯特拉(Dikastra)算法
对于求单源点的最短路径问题,狄克斯特拉(Dikastra)提出了一个按路径长度递增的顺序逐步产生最短路径的构造算法。狄克斯特拉的算法思想是:设置两个顶点的集合 S 和 T,集合 S 中存放已找到最短路径的顶点,集合 T 中存放当前还未找到最短路径的顶点。初始状态时,集合 S 中只包含源点,设为 v0,然后从集合 T 中选择到源点 v0 路径长度最短的顶点 u 加入到集合 S 中,集合 S 中每加入一个新的顶点 u 都要修改源点 v0 到集合 T 中剩余顶点的当前最短路径长度值,集合 T 中各顶点的新的最短路径长度值为原来的当前最短路径长度值与从源点过顶点 u 到达该顶点的新的最短路径长度中的较小者。此过程不断重复,直到集合 T 中的顶点全部加到集合 S 中为止。
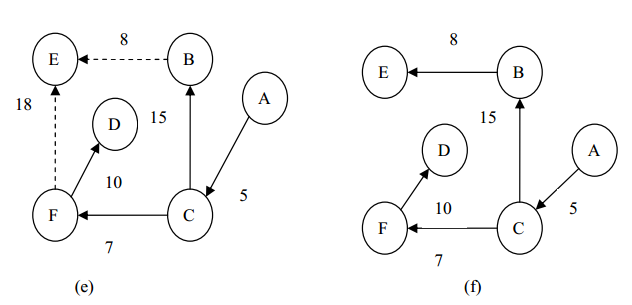
以上图 为例说明用狄克斯特拉算法求有向网的从某个顶点到其余顶点最短路径的过程。
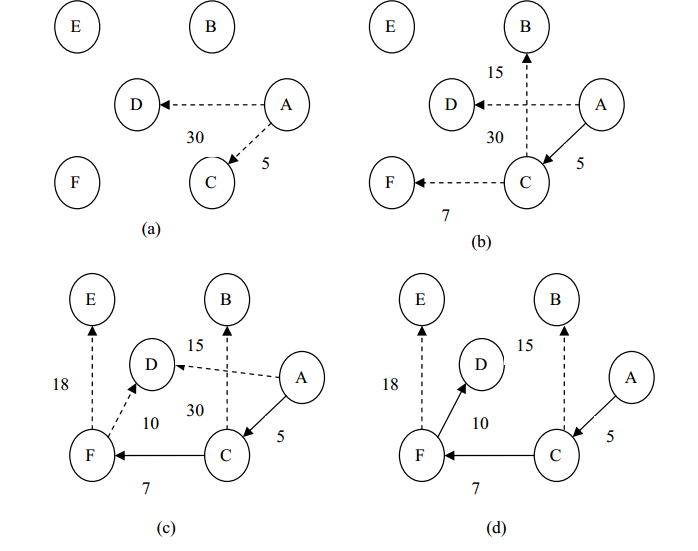
下图(a)~(f)给出了狄克斯特拉算法求从顶点 A 到其余顶点的最短路径的过程。图中虚线表示当前可选择的边,实线表示算法已确定包括到集合 S 中所有顶点所对应的边。
第一步:列出顶点 A 到其余各顶点的路径长度,它们分别为 0、∞、 5、 30、∞、∞。从中选取路径长度最小的顶点 C(从源点到顶点 C 的最短路径为 5)。
第二步:找到顶点 C 后,再观察从源点经顶点 C 到各个顶点的路径是否比第一步所找到的路径要小(已选取的顶点则不必考虑),可发现,源点到顶点 B的路径长度更新为 20(A, C, B),源点到顶点 F 的路径长度更新为 12(A, C,F),其余的路径则不变。然后, 从已更新的路径中找出路径长度最小的顶点 F(从源点到顶点 F 的最短路径为 12)。
第三步:找到顶点 C、 F 以后,再观察从源点经顶点 C、 F 到各顶点的路径是否比第二步所找到的路径要小(已被选取的顶点不必考虑),可发现,源点到顶点 D 的路径长度更新为 22(A, C, F, D),源点到顶点 E 的路径长度更新为30(A, C, F, E),其余的路径不变。然后,从已更新的路径中找出路径长短最小的顶点 D(从源点到顶点 D 的最短路径为 22)。
第四步:找到顶点 C、 F、 D 后,现在只剩下最后一个顶点 E 没有找到最短路径了,再观察从源点经顶点 C、 F、 D 到顶点 E 的路径是否比第三步所找到的路径要小(已选取的顶点则不必考虑),可以发现,源点到顶点 E 的路径长度更新为 28(A, C,B, E),其余的路径则不变。然后,从已更新的路径中找出路径长度最小的顶点 E(从源点到顶点 E 的最短路径为 28)。
3、 有向网的邻接矩阵类的实现
本文以有向网的邻接矩阵类 DirecNetAdjMatrix<T>来实现狄克斯特拉算法。DirecNetAdjMatrix<T>有三个成员字段,一个是 Node<T>类型的一维数组 nodes,存放有向网中的顶点信息,一个是整型的二维数组 matirx,表示有向网的邻接矩阵,存放弧的信息,一个是整数 numArcs,表示有向网中弧的数目,有向网的邻接矩阵类 DirecNetAdjMatrix<T>的实现如下所示。
1 /// <summary> 2 /// 有向网的邻接矩阵类 3 /// </summary> 4 /// <typeparam name="T"></typeparam> 5 public class DirecNetAdjMatrix<T> : IGraph<T> 6 { 7 private Node<T>[] nodes; //有向网的顶点数组 8 private int numArcs; //弧的数目 9 private int[,] matrix; //邻接矩阵数组 10 11 public DirecNetAdjMatrix(int n) 12 { 13 nodes = new Node<T>[n]; 14 matrix = new int[n, n]; 15 numArcs = 0; 16 } 17 18 //获取索引为index的顶点的信息 19 public Node<T> GetNode(int index) 20 { 21 return nodes[index]; 22 } 23 24 //设置索引为index的顶点的信息 25 public void SetNode(int index, Node<T> v) 26 { 27 nodes[index] = v; 28 } 29 30 //获取matrix[index1, index2]的值 31 public int GetMatrix(int index1, int index2) 32 { 33 return matrix[index1, index2]; 34 } 35 36 //设置matrix[index1, index2]的值 37 public void SetMatrix(int index1, int index2, int v) 38 { 39 matrix[index1, index2] = v; 40 } 41 42 //弧的数目属性 43 public int NumArcs 44 { 45 get { return numArcs; } 46 set { numArcs = value; } 47 } 48 49 //获取顶点的数目 50 public int GetNumOfVertex() 51 { 52 return nodes.Length; 53 } 54 55 //获取弧的数目 56 public int GetNumOfEdge() 57 { 58 return numArcs; 59 } 60 61 //判断v是否是网的顶点 62 public bool IsNode(Node<T> v) 63 { 64 //遍历顶点数组 65 foreach (Node<T> nd in nodes) 66 { 67 //如果顶点nd与v相等,则v是网的顶点,返回true 68 if (v.Equals(nd)) 69 { 70 return true; 71 } 72 } 73 74 return false; 75 } 76 77 //获取顶点v在顶点数组中的索引 78 public int GetIndex(Node<T> v) 79 { 80 int i = -1; 81 82 //遍历顶点数组 83 for (i = 0; i < nodes.Length; ++i) 84 { 85 //如果顶点v与nodes[i]相等,则v是网的顶点,返回索引值i。 86 if (nodes[i].Equals(v)) 87 { 88 return i; 89 } 90 } 91 return i; 92 } 93 94 //在顶点v1和v2之间添加权值为v的弧 95 public void SetEdge(Node<T> v1, Node<T> v2, int v) 96 { 97 if (!IsNode(v1) || !IsNode(v2)) 98 { 99 Console.WriteLine("Node is not belong to Net!"); 100 return; 101 } 102 103 //有向 104 matrix[GetIndex(v1), GetIndex(v2)] = v; 105 ++numArcs; 106 } 107 108 //删除顶点v1和v2之间的弧 109 public void DelEdge(Node<T> v1, Node<T> v2) 110 { 111 //v1或v2不是无线网的顶点 112 if (!IsNode(v1) || !IsNode(v2)) 113 { 114 Console.WriteLine("Node is not belong to Net!"); 115 return; 116 } 117 118 //有向 119 if (matrix[GetIndex(v1), GetIndex(v2)] != int.MaxValue) 120 { 121 matrix[GetIndex(v1), GetIndex(v2)] = int.MaxValue; 122 --numArcs; 123 } 124 } 125 126 //判断顶点v1与v2之间是否存在弧 127 public bool IsEdge(Node<T> v1, Node<T> v2) 128 { 129 //v1或v2不是无向网的顶点 130 if (!IsNode(v1) || !IsNode(v2)) 131 { 132 Console.WriteLine("Node is not belong to Net!"); 133 return false; 134 } 135 136 //顶点v1与v2之间存在弧 137 if (matrix[GetIndex(v1), GetIndex(v2)] != int.MaxValue) 138 { 139 return true; 140 } 141 else //不存在弧 142 { 143 return false; 144 } 145 } 146 }
4、 狄克斯特拉算法的实现
为实现狄克斯特拉算法,引入两个数组,一个一维数组 ShortPathArr,用来保存从源点到各个顶点的最短路径的长度,一个二维数组 PathMatrixArr,用来保存从源点到某个顶点的最短路径上的顶点,如 PathMatrix[v][w]为 true,则 w为从源点到顶点 v 的最短路径上的顶点。为了该算法的结果被其他算法使用,把这两个数组作为算法的参数使用。另外,为了表示某顶点的最短路径是否已经找到,在算法中设了一个一维数组 final,如果 final[i]为 true,则表示已经找到第 i 个顶点的最短路径。 i 是该顶点在邻接矩阵中的序号。同样,把该算法作为类DirecNetAdjMatrix<T>的成员方法来实现。
1 /// <summary> 2 /// 狄克斯特拉算法 3 /// </summary> 4 /// <param name="pathMatricArr">保存从源点到某个顶点的最短路径上的顶点,如 PathMatrix[v][w]为 true,则 w为从源点到顶点 v 的最短路径上的顶点</param> 5 /// <param name="shortPathArr"保存从源点到各个顶点的最短路径的长度></param> 6 /// <param name="n">源点</param> 7 public void Dijkstra(ref bool[,] pathMatricArr, ref int[] shortPathArr, Node<T> n) 8 { 9 int k = 0; 10 bool[] final = new bool[nodes.Length]; 11 12 //初始化 13 for (int i = 0; i < nodes.Length; ++i) 14 { 15 final[i] = false; 16 shortPathArr[i] = matrix[GetIndex(n), i]; 17 18 for (int j = 0; j < nodes.Length; ++j) 19 { 20 pathMatricArr[i, j] = false; 21 } 22 23 if (shortPathArr[i] != 0 && shortPathArr[i] < int.MaxValue) 24 { 25 pathMatricArr[i, GetIndex(n)] = true; 26 pathMatricArr[i, i] = true; 27 28 } 29 } 30 31 // n为源点 32 shortPathArr[GetIndex(n)] = 0; 33 final[GetIndex(n)] = true; 34 35 //处理从源点到其余顶点的最短路径 36 for (int i = 0; i < nodes.Length; ++i) 37 { 38 int min = int.MaxValue; 39 40 //比较从源点到其余顶点的路径长度 41 for (int j = 0; j < nodes.Length; ++j) 42 { 43 //从源点到j顶点的最短路径还没有找到 44 if (!final[j]) 45 { 46 //从源点到j顶点的路径长度最小 47 if (shortPathArr[j] < min) 48 { 49 k = j; 50 min = shortPathArr[j]; 51 } 52 } 53 } 54 55 //源点到顶点k的路径长度最小 56 final[k] = true; 57 58 //更新当前最短路径及距离 59 for (int j = 0; j < nodes.Length; ++j) 60 { 61 if (!final[j] && (min + matrix[k, j] < shortPathArr[j])) 62 { 63 shortPathArr[j] = min + matrix[k, j]; 64 for (int w = 0; w < nodes.Length; ++w) 65 { 66 pathMatricArr[j, w] = pathMatricArr[k, w]; 67 } 68 pathMatricArr[j, j] = true; 69 } 70 } 71 } 72 }
1.4.3:拓扑排序
拓扑排序(Topological Sort)是图中重要的运算之一,在实际中应用很广泛。例如,很多工程都可分为若干个具有独立性的子工程,我们把这些子工程称为“活动”。每个活动之间有时存在一定的先决条件关系,即在时间上有着一定的相互制约的关系。也就是说,有些活动必须在其它活动完成之后才能开始,即某项活动的开始必须以另一项活动的完成为前提。在有向图中,若以图中的顶点表示活动,以弧表示活动之间的优先关系,这样的有向图称为 AOV 网(Active On VertexNetwork)。
在 AOV 网中,若从顶点 vi 到顶点 vj 之间存在一条有向路径,则称 vi 是 vj的前驱, vj 是 vi 的后继。若<vi,vj>是 AOV 网中的弧,则称 vi 是 vj 的直接前驱,vj 是 vi 的直接后继。
例如,一个软件专业的学生必须学习一系列的基本课程(如下表所示)。其中,有些课程是基础课,如“高等数学”、“程序设计基础”,这些课程不需要先修课程,而另一些课程必须在先学完某些课程之后才能开始学习。如通常在学完“程序设计基础”和“离散数学”之后才开始学习“数据结构”等等。因此,可以用 AOV 网来表示各课程及其之间的关系。

在 AOV 网中,不应该出现有向环路,因为有环意味着某项活动以自己作为先决条件,这样就进入了死循环。如果图 6.19 的有向图出现了有向环路,则教学计划将无法编排。因此,对给定的 AOV 网应首先判定网中是否存在环。检测的办法是对有向图进行拓扑排序(Topological Sort),若网中所有顶点都在它的拓扑有序序列中,则 AOV 网中必定不存在环。
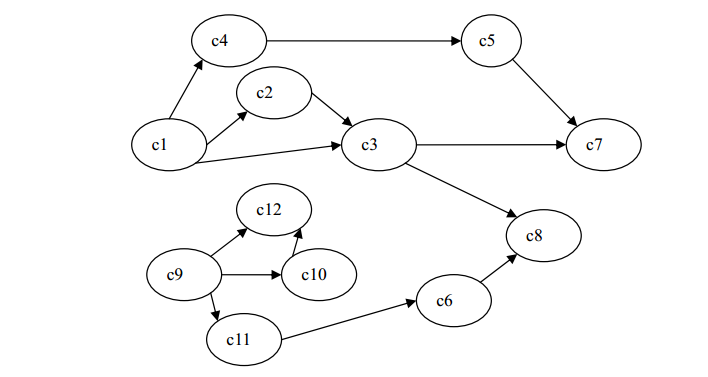
实现一个有向图的拓扑有序序列的过程称为拓扑排序。可以证明,任何一个有向无环图,其全部顶点都可以排成一个拓扑序列,而其拓扑有序序列不一定是唯一的。例如,上图的有向图的拓扑有序序列有多个,这里列举两个如下:
(c1,c2,c3,c4,c5,c7,c8,c9,c10,c11,c6,c12,c8)和 (c9,c10,c11,c6,c1,c12,c4,c2,c3,c5,c7,c8)
由上面两个序列可知,对于图中没有弧相连的两个顶点,它们在拓扑排序的序列中出现的次序没有要求。例如,第一个序列中 c1 先于 c9,第二个则反之。拓扑排序的任何一个序列都是一个可行的活动执行顺序,它可以检测到图中是否存在环,因为如果有环,则环中的顶点无法输出,所以得到的拓扑有序序列没有包含图中所有的顶点。
下面是拓扑排序算法的描述:
(1)在有向图中选择一个入度为 0 的顶点(即没有前驱的顶点),由于该顶点没有任何先决条件,输出该顶点;
(2)从图中删除所有以它为尾的弧;
(3)重复执行(1)和(2),直到找不到入度为 0 的顶点,拓扑排序完成。如果图中仍有顶点存在,却没有入度为 0 的顶点,说明 AOV 网中有环路,否则没有环路。
如果图中仍有顶点存在,却没有入度为 0 的顶点,说明 AOV 网中有环路,否则没有环路。
以下图 (a)为例求出它的一个拓扑有序序列。
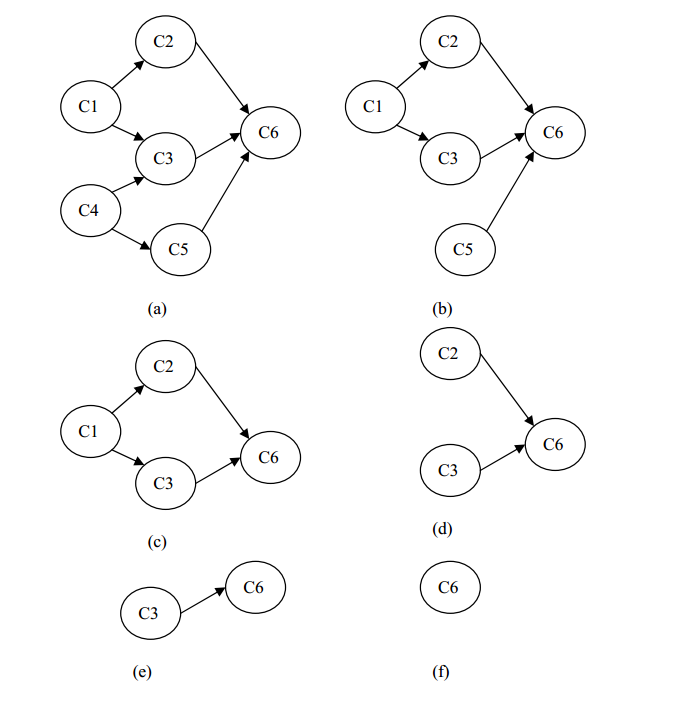
第一步:在图 (a)所示的有向图中选取入度为 0 的顶点 c4,删除顶点 c4及与它相关联的弧<c4,c3>, <c4,c5>,得到图 (b)所示的结果,并得到第一个拓扑有序序列顶点 c4。
第二步:再在图 (b)中选取入度为 0 的顶点 c5,删除顶点 c5 及与它相关联的弧<c5,c6>,得到图 (c)所示的结果,并得到两个拓扑有序序列顶点 c4,c5。
第三步:再在图 (c)中选取入度为 0 的顶点 c1,删除顶点 c1 及与它相关联的弧<c1,c2>, <c1,c3>,得到图 (d)所示的结果,并得到三个拓扑有序序列顶点 c4, c5, c1。
第四步:再在图 (d)中选取入度为 0 的顶点 c2,删除顶点 c2 及与它相关联的弧<c2,c6>,得到图 (e)所示的结果,并得到四个拓扑有序序列顶点 c4,c5, c1, c2。
第五步:再在图 (e)中选取入度为 0 的顶点 c3,删除顶点 c3 及与它相关联的弧<c3,c6>,得到图 (f)所示的结果,并得到五个拓扑有序序列顶点 c4,c5, c1, c2, c3。
第六步:最后选取仅剩下的最后一个顶点 c6,拓扑排序结束,得到图 (a)的一个拓扑有序序列(c4, c5, c1, c2, c3, c6)。
1.5:本章小结
图是另一种比树形结构更复杂的非线性数据结构,图中的数据元素称为顶点,顶点之间是多对多的关系。图分为有向图和无向图,带权值的图称为网。
图的存储结构很多,一般采用数组存储图中顶点的信息,邻接矩阵采用矩阵也就是二维数组存储顶点之间的关系。无向图的邻接矩阵是对称的,所以在存储时可以只存储上三角矩阵或下三角矩阵的数据;有向图的邻接矩阵不是对称的。邻接表用一个链表来存储顶点之间的关系,所以邻接表是顺序存储与链式存储相结合的存储结构。
图的遍历方法有两种:深度优先遍历和广度优先遍历。图的深度优先遍历类似于树的先序遍历,是树的先序遍历的推广,它访问顶点的顺序是后进先出,与栈一样。图的广度优先遍历类似于树的层序遍历,它访问顶点的顺序是先进先出,与队列一样。
图的应用很广,本章重点介绍了三个方面的应用。最小生成树是一个无向连通网中边的权值总和最小的生成树。构造最小生成树必须包括 n 个顶点、 n-1 条边及不存在回路。构造最小生成树的常用算法有普里姆算法和克鲁斯卡尔算法两种。
最短路径问题是图的一个比较典型的应用问题。最短路径是网中求一个顶点到另一个顶点的所有路径中边的权值之和最小的路径。可以求从一个顶点到网中其余顶点的最短路径,这称之为单源点问题,也可以求网中任意两个顶点之间的最短路径。本章只讨论了单源点问题。解决单源点问题的算法是狄克斯特拉算法。
拓扑排序是图中重要的运算之一,在实际中应用很广泛。 AOV 网是顶点之间存在优先关系的有向图。拓扑排序是解决 AOV 网中是否存在环路的有效手段,若拓扑有序序列中包含 AOV 网中所有的顶点,则 AOV 网中不存在环路,否则存在环路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号