cs231n 随笔(1)
一、K最近邻算法(KNN)。
1. 有关K参数(统称超参数)选取,一种常见的方式是将数据集分为三部分,最大的训练集train set ,以及两个大小相当的验证集和测试集。通过训练集训练模型,再通过验证集选取合适的K参数,最终再用测试集去记录模型有效性。
2. KNN算法训练的时间较短,因为只需要记录训练集的数据,而对单个目标的检测时间较长,因为需要将测试用例与训练集中所有数据进行对比得到最近的结果。
3.选取近邻的方式有L1距离(每个像素位置作差再求和),欧氏距离(像素差平方和再开根)。两种方式其实都不太适合用来比较图像。
二、 线性分类器(linear classifier)
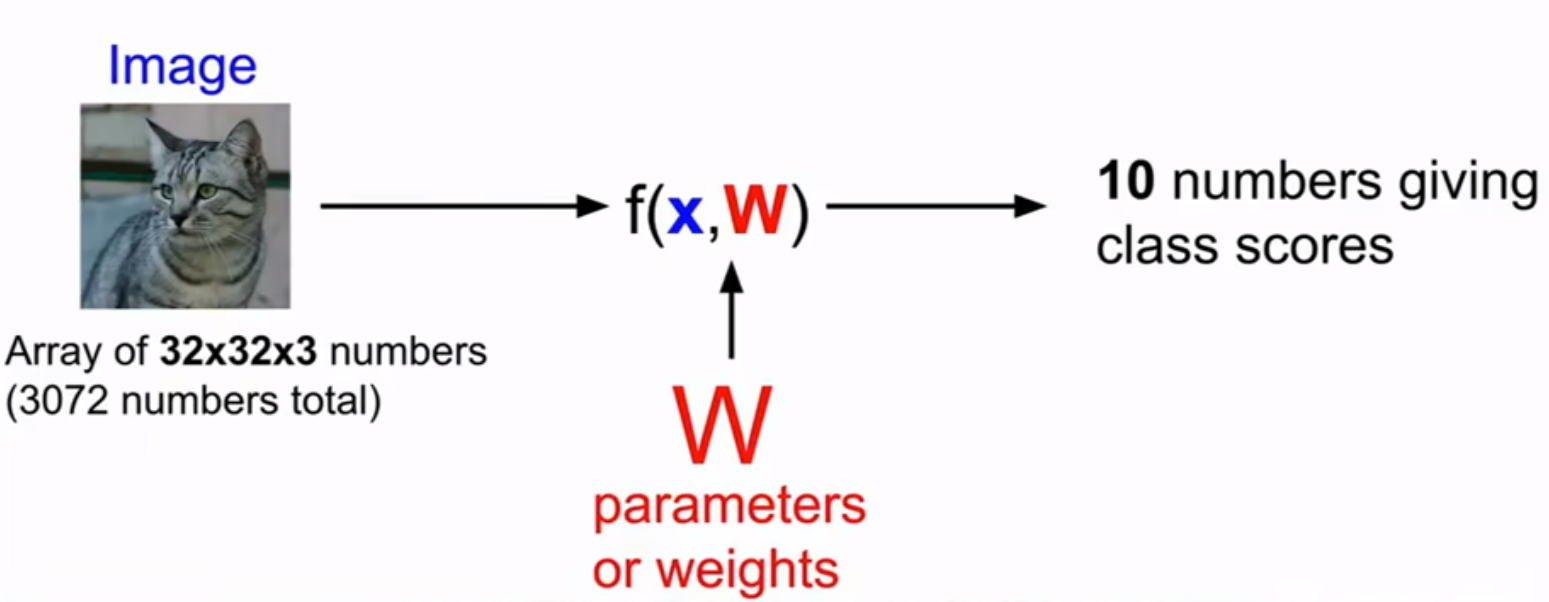
1. x为输入的图像数据,W为各种参数以及权重,最后得出输入图片的各项评分,更接近于什么图像。
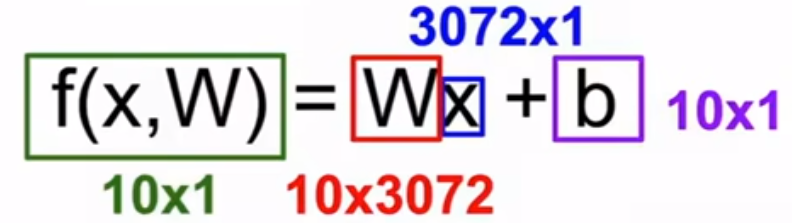
2. 要得出10个评分,需要10*3072的矩阵W与输入图像3072*1矩阵相乘。有时也会在最后添加偏好项b。
3.损失函数Li,用于评估线性分类器参数W的准确度
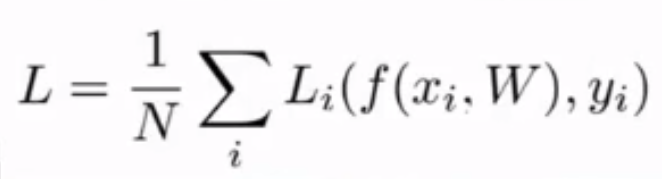
Li函数具体实现


 浙公网安备 33010602011771号
浙公网安备 33010602011771号