
手写数字识别
手写数字识别
一、实验目的
掌握分类识别问题的本质,了解各种分类问题的机器学习方法,并至少掌握一种,熟悉Python编程。
二、实验内容
对实验提供的手写数据库MNIST进行训练和测试,最终能够较为准确的识别数据库中的手写体数字。
三、实验原理
神经网络又称人工神经网络 (ANN) 或模拟神经网络 (SNN),是机器学习的子集,同时也是深度学习算法的核心。人工神经网络 (ANN) 由节点层组成,包含一个输入层、一个或多个隐藏层和一个输出层。 每个节点也称为一个人工神经元,它们连接到另一个节点,具有相关的权重和阈值。如果任何单个节点的输出高于指定的阈值,那么会激活该节点,并将数据发送到网络的下一层。否则,不会将数据传递到网络的下一层。
卷积神经网络由输入层,卷积层,池化层,全连接层,输出层等组成。输入层处理输入的图像数据,在卷积层经过二维卷积运算提取特征,在经过池化层对提取到的特征进行选择和过滤,最终通过全连接层经过梯度运算迭代结果。因此,在卷积神经网络中图形的特征可以自动提取,并不需要对所分类图形的处理具有先验知识。
四.源代码
四、源代码
1.net.py
查看代码
import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
# in_channels = 1, out_channles=32, kernel_size=3, stride=1, padding=1
torch.nn.Conv2d(1, 32, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(64 * 3 * 3, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 10)
)
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out2.train.py
查看代码
import torch
import torchvision
import torch.utils.data.dataloader as Data
from torch.utils.tensorboard import SummaryWriter
from net import Net
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 验证是否能调用GPU训练
saved_model_path = "net.pth"
if os.path.exists(saved_model_path):
model = torch.load(saved_model_path)
else:
model = Net()
model.to(device)
model.eval()
lr = 0.001 # 学习率
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = torch.nn.CrossEntropyLoss().to(device)
def train_epoch(
epoch, train_loader, train_data, model, optimizer, train_loss=0.0, train_acc=0.0
):
iter = 0
# batch_x是图片, batch_y是标签
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
out = model(batch_x) # 64*1*28*28
loss = loss_func(out, batch_y)
train_loss += loss.data.item()
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
iter = iter + 1
if iter % 100 == 0:
print(
f"Train epoch {epoch}: ["
f"{iter * len(batch_y)}/{len(train_loader.dataset)}"
f" ({100. * iter * len(batch_y) / len(train_loader.dataset):.0f}%)]"
f"\tLoss: {train_loss / (iter * len(batch_y)):.6f}"
f"\tAccuracy: {train_acc / (iter * len(batch_y)):.6f}"
)
return train_loss / (len(train_data))
def test_epoch(epoch, test_loader, test_data, model, eval_loss=0.0, eval_acc=0.0):
model.eval()
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.data.item()
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.data.item()
print(
f"\nTest epoch {epoch}: "
f"\tAverageLoss: {eval_loss / (len(test_data)):.6f}"
f"\tAverageAccuracy: {eval_acc / (len(test_data)):.6f}\n"
)
return eval_acc / (len(test_data))
def main():
best_accu = 1e-10
# 数据集定义,没有会自动下载
train_data = torchvision.datasets.MNIST(
"./mnist",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True,
)
test_data = torchvision.datasets.MNIST(
"./mnist", train=False, transform=torchvision.transforms.ToTensor()
)
print("train_data:", train_data.train_data.size())
print("train_labels:", train_data.train_labels.size())
print("test_data:", test_data.test_data.size())
# 定义dataloader
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader = Data.DataLoader(dataset=test_data, batch_size=64)
# 定义Adam优化器
optimizer = torch.optim.Adam(model.parameters())
# 如果存在训练好的模型,可直接加载
# 定义tensorboard可视化
writer = SummaryWriter("./boardlog")
for epoch in range(100):
train_loss = train_epoch(epoch, train_loader, train_data, model, optimizer)
accu = test_epoch(epoch, test_loader, test_data, model)
# 记录train loss和测试集上的识别准确度
writer.add_scalar("train_loss", train_loss, global_step=epoch, walltime=None)
writer.add_scalar("val_loss", accu, global_step=epoch, walltime=None)
if accu > best_accu:
# 保存最佳模型及参数
best_accu = accu
print("This epoch trained the best loss")
torch.save(model, "net.pth")
if __name__ == "__main__":
main()3.test.py
查看代码
import torch
import torchvision
from torch.autograd import Variable
import torch.utils.data.dataloader as Data
from net import Net
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
test_data = torchvision.datasets.MNIST('./mnist', train=False, transform=torchvision.transforms.ToTensor())
test_loader = Data.DataLoader(dataset=test_data, batch_size=1)
Record=torch.ones(len(test_loader.dataset))
eval_acc=0
model = torch.load('net.pth')
model.to(device)
model.eval()
with torch.no_grad():
iter = 0
for batch_x, batch_y in test_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
out = model(batch_x)
pred = torch.max(out, 1)[1]
if pred == batch_y:
Record[iter] = 0
eval_acc += 1
else:
print(f'The mismatch appears in image No.{iter + 1} '
f'\tThe predicted result is {pred.item()}'
f'\tThe true label is {batch_y.item()}')
iter += 1
record_image = torch.reshape(Record, (100, 100))
image = torchvision.transforms.ToPILImage()(record_image)
image.save("result.jpg")
print(f'There are {len(test_data)-eval_acc} mismatches, and the accuracy of this method is:{eval_acc / (len(test_data))}')四、实验结果与分析
在配置完成pytorch环境后,使用命令行conda.activate激活刚才配置好的 pytorch 环境。
1.搭建CNN神经网络
通过堆叠卷积层和全连接层,逐渐提取图像特征,并通过全连接层进行分类。
(1)初始化方法 __init__:通过super(Net, self).__init__()调用父类的初始化方法,确保模型的初始化得以完成。
(2)卷积层 conv1、conv2 和 conv3:conv1包括一个卷积层、ReLU激活函数和最大池化层。该卷积层的输入通道数是1,输出通道数是32,卷积核大小是3x3,步幅为1,填充为1。然后是ReLU激活函数和最大池化层,池化核大小为2x2。conv2和conv3类似,但输入通道数为32(来自上一层的输出通道数),输出通道数分别为64和64。
(3)全连接层 dense:这个部分包括两个全连接层。首先,通过view操作将卷积层的输出展平为一维向量。第一个全连接层的输入大小是64 * 3 * 3(64个通道,每个通道的大小为3x3),输出大小为128,使用ReLU激活函数。第二个全连接层的输入大小是128,输出大小是10,用于最终的分类任务(10个类别)。
(4)前向传播方法 forward:在这个方法中,输入x通过conv1、conv2 和 conv3 这三个卷积层,然后通过view操作展平,最后通过全连接层 dense 完成整个模型的前向传播过程。
2.构建train代码
(1)导入PyTorch及相关库,包括处理数据集的torchvision库、torch.utils.data中的DataLoader用于加载数据、SummaryWriter用于TensorBoard可视化、以及自定义的神经网络模型类Net。
(2)检查GPU是否可用(本机可用),并加载预训练模型或创建一个神经网络模型,将模型移动到GPU或CPU(本机使用的是GPU),并设置学习率。将模型状态设置为eval,表示推理阶段。
(3)定义优化器和损失函数,此处使用Adam优化器和交叉熵损失函数,同时将损失函数移动到相应的设备。
(4)定义训练和测试的函数train_epoch和test_epoch,分别训练一个epoch和在测试集上评估模型,循环遍历数据加载器,进行前向传播、计算损失、反向传播和参数更新。
(5)主要的循环训练在main()函数中定义,每次训练100个epoch。在每个epoch中,调用train_epoch进行训练,然后调用test_epoch在测试集上评估模型。通过SummaryWriter将训练损失和测试准确度写入TensorBoard日志。如果在测试集上获得了高于之前的准确度,就保存当前模型。
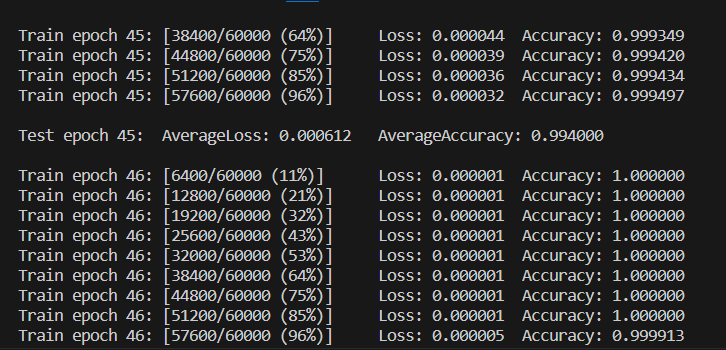
训练过程的后台信息显示如下:
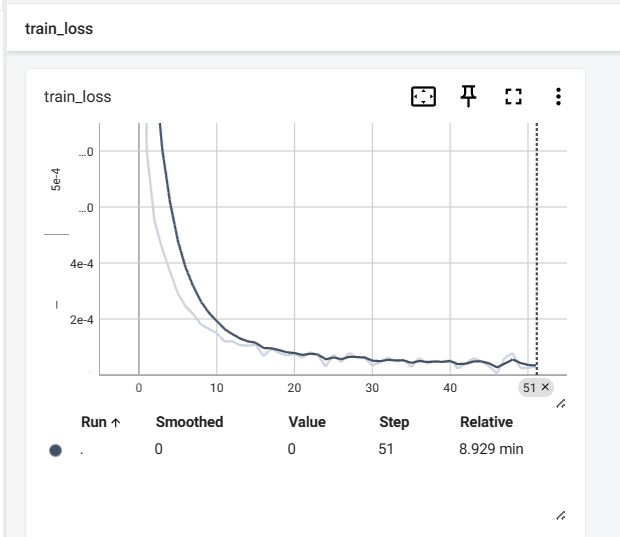
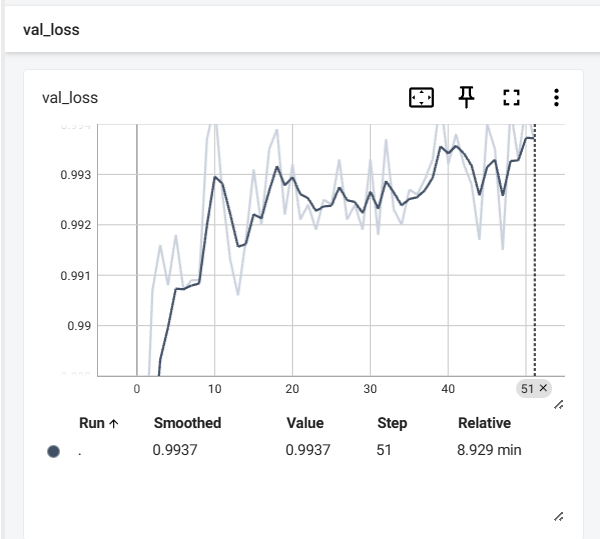
训练完51个epoch后的train_loss和val_loss的变化曲线图分别如下所示:
3.构建test代码
(1)导入所需的PyTorch库,包括加载数据集的torchvision、torch.utils.data.dataloader用于加载数据、以及之前定义的神经网络模型类Net。
(2)设置设备为GPU,加载MNIST测试数据集,并创建一个数据加载器,每次加载一个样本。
(3)初始化一个记录变量Record,用于记录每个样本的预测是否正确。eval_acc用于计算准确率。
(4)加载之前训练好的模型,并将其移动到GPU或CPU上(本机为GPU)。将模型的状态设置为eval,表示在推断阶段。
(5)进行模型评估。对测试集的每个样本进行前向传播,并比较模型的预测结果和真实标签。如果预测正确,将对应位置的Record设置为0,并增加准确计数。
(6)记录错误样本,并将测试结果转换为PIL图像,保存结果图像,图像显示测试集中每个样本的模型预测结果的正确与否。最后打印出不匹配的样本数量以及评估准确率。
测试过程后台的输出结果如下所示:
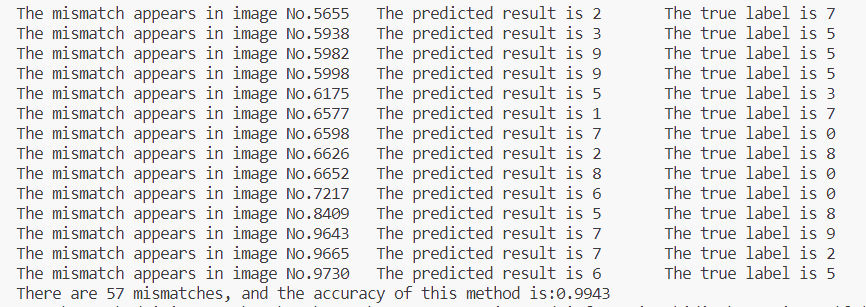
可以看到,测试的准确率已经到达了99.43%。
输出的结果图像如下所示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号