

阅读笔记-2022.11.23
论文:DEEP BATCH ACTIVE LEARNING BY DIVERSE, UNCERTAIN GRADIENT LOWER BOUNDS
一种基于深度神经网络模型的批量主动学习算法。
NOTATION AND SETTING
论文使用基于池的主动学习,学习器接收到一个根据
给定一个分类器
一个标记实例
分类器
基于池的主动学习的目标是使用尽可能少的标签查询找到预期
由结构固定的底层神经网络
ALGORITHM

首先从
The gradient embedding
由于深度神经网络是使用基于梯度的方法进行优化的,作者通过梯度的视角来捕捉关于一个实例的不确定性。特别是,如果知道标签会引起相对于模型参数的损失的大梯度,从而对模型进行大的更新,就可以认为模型对一个实例不确定。这种推理的一个难点是需要知道标签来计算梯度。作为一个agent,计算梯度时,就像模型对例子的当前预测是真实的标签一样。假设大多数自然神经网络满足一个共同的结构,相对于最后一层使用这个标签的梯度规范提供了一个由任何其他标签引起的梯度规范的下限。此外,在该假设下,这个假设的梯度向量的长度捕捉了模型对实例的不确定性:如果模型对实例的标签高度确定,那么实例的梯度嵌入将有一个小的规范,反之,对于模型不确定的样本将有一个较大的规范。因此,梯度嵌入既传达了关于模型的不确定性的信息,也传达了在收到一个例子的标签时的潜在更新方向。
The sampling step
文中希望新的标记样本能给模型带来巨大且多样的改变,而不是病态地选取某一类的样本。
在不引入额外超参数的情况下,进行这种选择的一个自然方法是从
不幸的是,从
Example: multiclass classification with softmax activations
一个神经网络
定义
根据这个表达式,我们可以做如下观察:
- 下面的Proposition 1 表明,
- 如果当前模型
Proposition 1:
因此有
根据公式 (1) 有:
第二项来自于
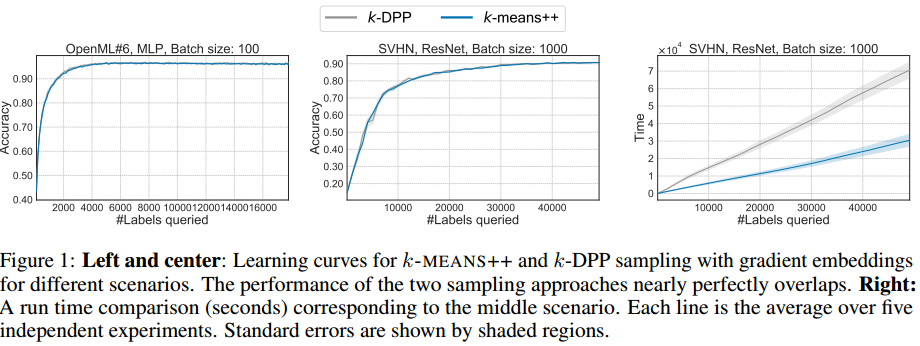
这种简单的取样器倾向于产生类似于
....


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述