

阅读笔记-2022.11.15
论文:Active Learning by Feature Mixing
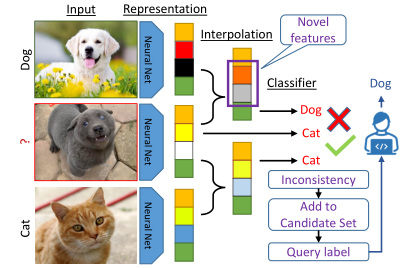
问题定义(Problem Definition)
在不丧失一般性的前提下,学习目标是训练一个具有 K 类的有监督的多分类问题。模型在于Oracle的交互中被积极地训练。在每次迭代中,这个主动学习者都可以访问一小组标记数据
深度神经网络
对于不可见实例的标签(即伪标签)的预测为
特征混合 (Feature Mixing)
潜在空间的特征在确定最有价值的样本进行标记方面起着至关重要的作用。作者认为模型的错误预测主要是由于输入中无法识别的新“特征”。因此,通过首先探测模型学习到的特征来解决人工智能问题。为此,论文使用特征的凸组合(即插值)来探索每个为标记点附近的新特征。形式上,作者考虑在未标记和标记实例的表示之间的差值,
作者用所有代表不同类别的anchor来插插值一个无标签的实例,通过考虑模型的预测如何变化来发现足够明显的特征。为此,作者研究了无标记实例的伪标签(即
使用一阶泰勒关于
对于一个足够小的
直观地说,再进行插值时,损失的变化与两个条件成正比:
- 损失的梯度与未标记的实例的关系。
前者决定了哪些特征是新的,以及它们的价值如何在有标签和无标签的实例之间有所不同。后者决定了模型对这些特征的敏感性。也就是说,如果有标签的实例和无标签的实例的特征完全不同,但模型时合理一致的,那么损失最重没有变化,因此这些特征不被认为是模型的新特征。
优化插值参数
由于手动选择
其中,
其中,

候选选择(Candidate Selection)
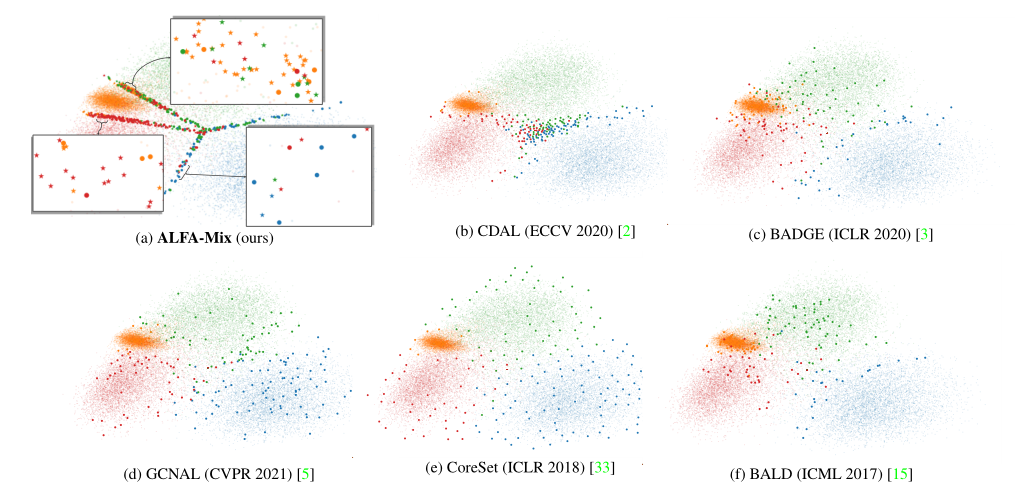
对于AL来说,根据公式(3),选择那些损失随着插值而大幅改变的实例进行查询是合理的。这对应于那些模型的预测发生变化并具有新特征的实例。直观地说,如图2(a)所示,这些样本被放置在潜在空间的决策边界附近。另外,当模型对输入特征的识别有合理的信心时,小的插值不应该影响模型的损失。候选集为:
所选集合


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述