

学习日志-2021.10.24
学习日志-2021.10.24
硕士论文第二部分复现
复杂网络上的合作行为演化研究 ——基于 Q-learning 算法
源码地址:RL_for_Gaming_to_choose_action(Q-Learning)
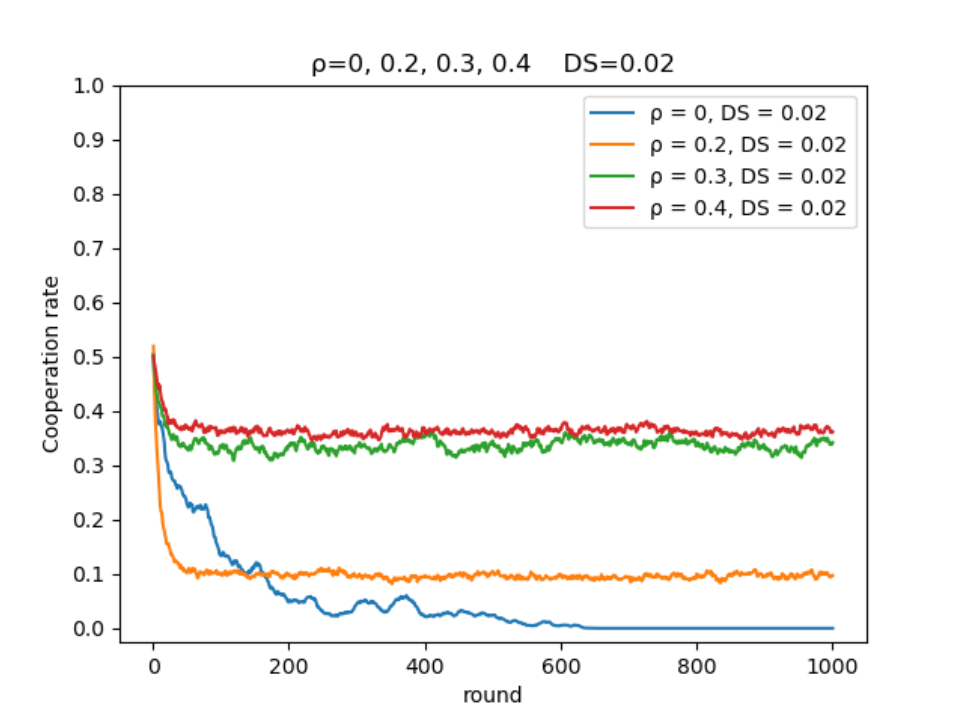
在相同智能体比例,不同困境强度下的演化:
- 合作率演化图:
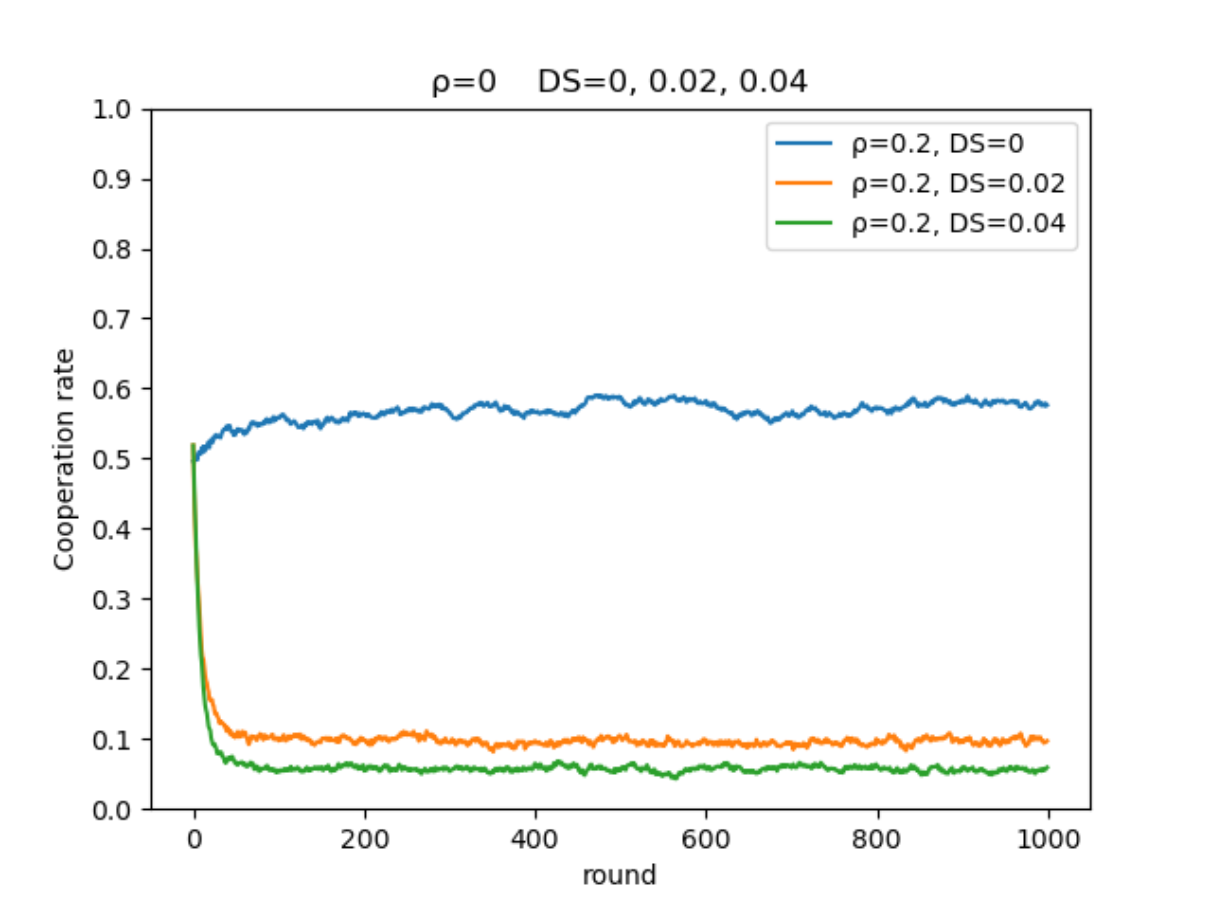
-
从左至右困境强度
图中方块边缘为红色代表为智能体(占比约为0.2)
智能体使用Q-Learning决定策略,非智能体使用费米更新规则决定策略(阈值为
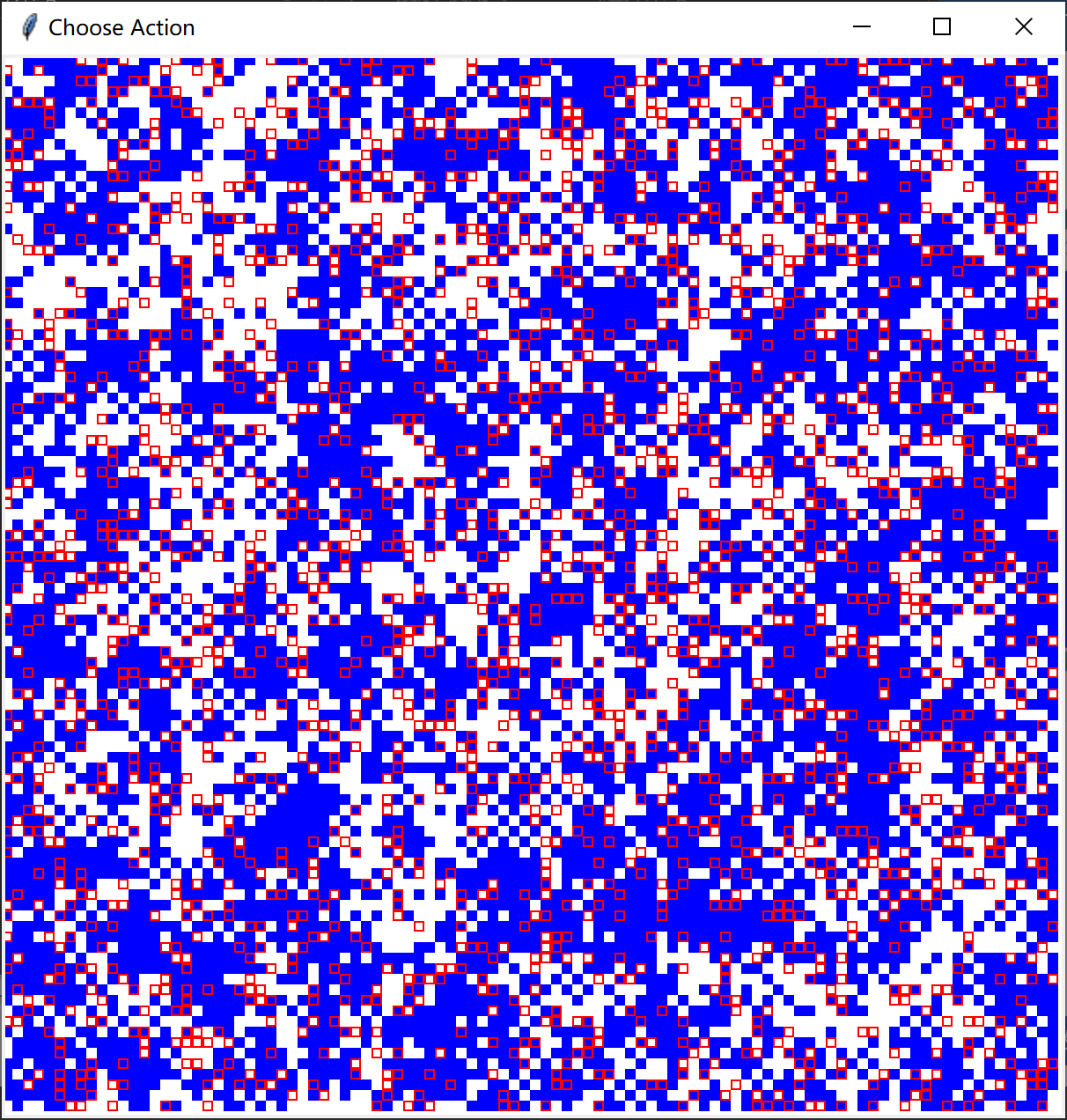
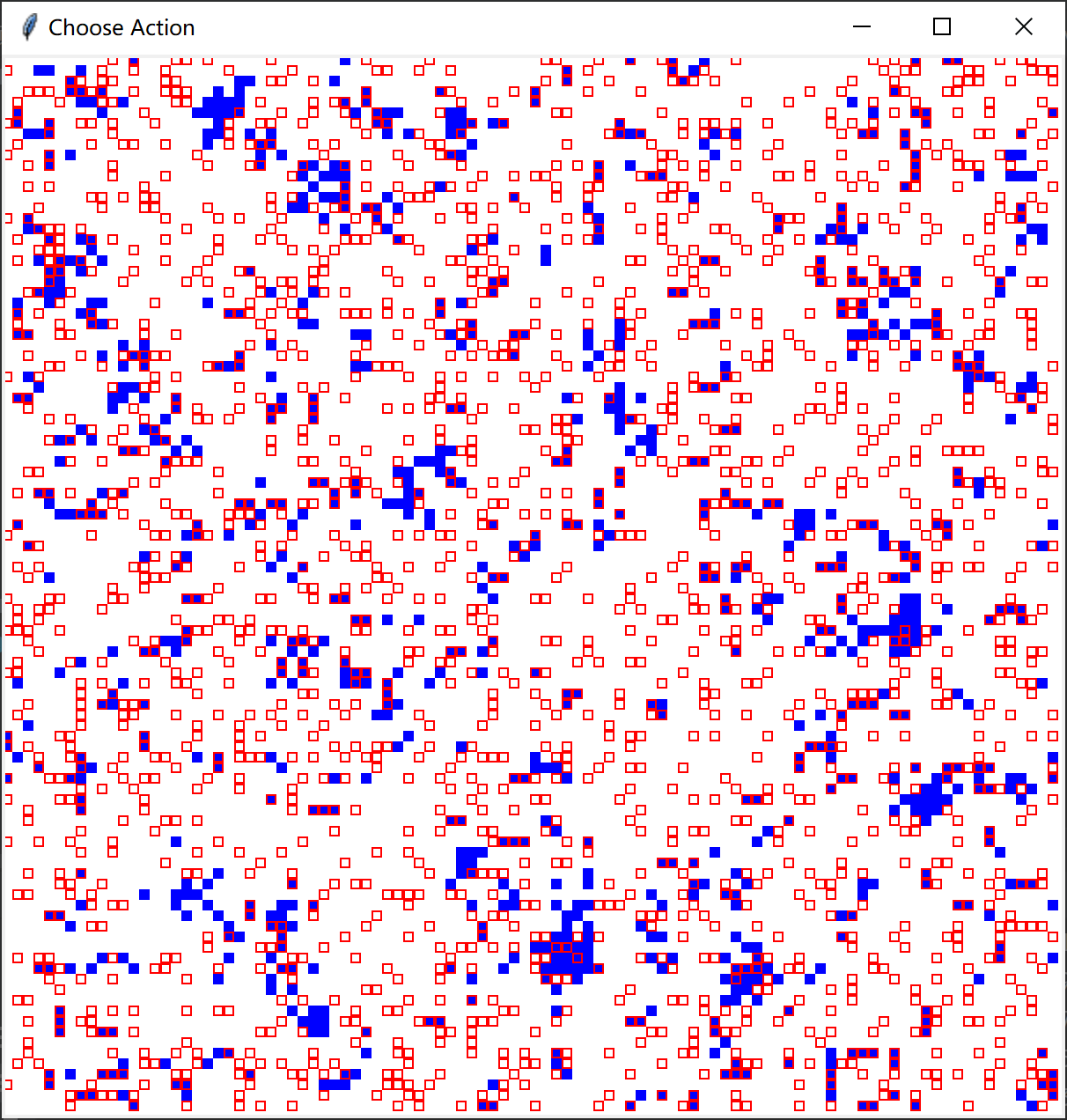
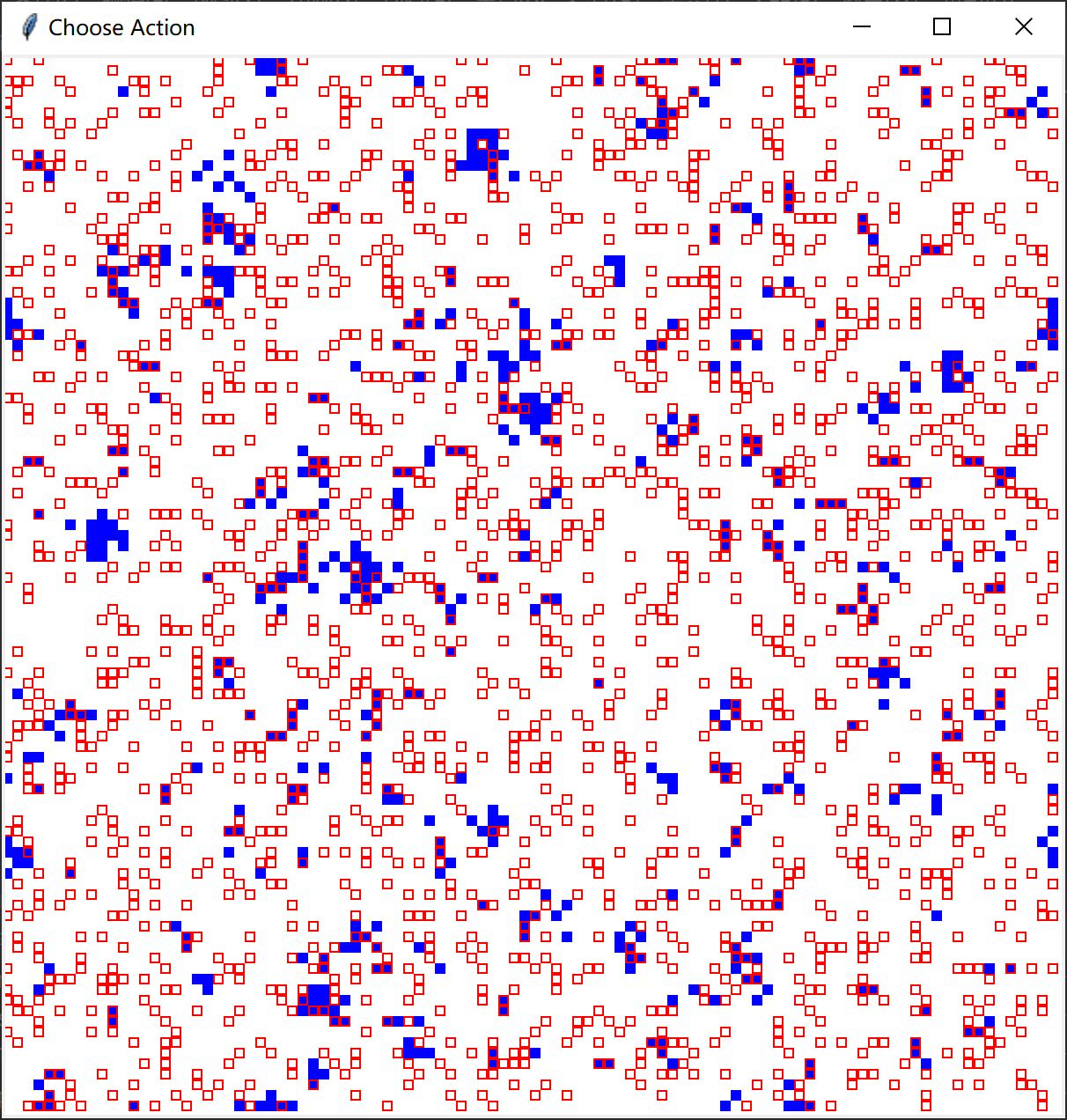
在不同智能体比例,相同困境强度下的演化:
- 根据仿真结果智能体占比的提高在一定范围内会使合作率提高,根据论文内容的描述在智能体比例达到0.7时,合作率会达到最高水平。
结果分析
- 本次仿真使用的网络规模为
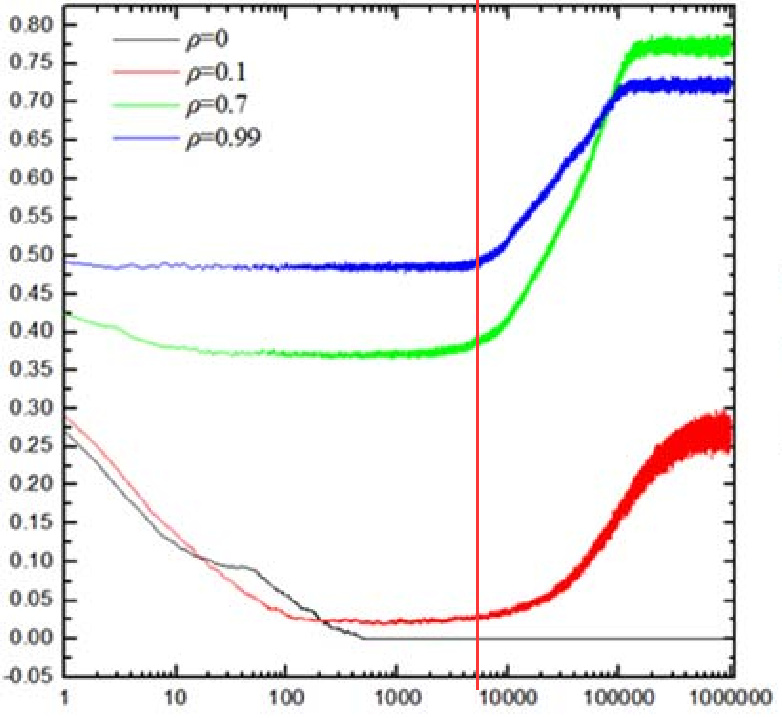
- 虽然并没有完美地复现出论文内容,但也可以得出:在一定范围内,随着使用Q-Learning算法智能体占比的提升,网络的合作率也会随之提升。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述