【c#基础】集合--栈Stack 链表 LinkList 有序列表SortedList 字典Dictionary
栈:是一个后进先出(LIFO)的容器
栈 push()方法在栈中添加元素,用Pop()方法获取最近添加的元素。
于Queue<T>类相似,Stack<T>类实现IEnumerable<T>和ICollection接口
Count 返回栈中的元素个数
Push 在栈顶添加一个元素
Pop 从站定删除一个元素,并返回该元素,如果栈是空的,就抛出InvalidOperationException异常
Peek 返回栈顶的元素,但不删除它
Contains 确定某个元素是否在栈中,如果是,就返回true.
链表
LinkedList<T>是一个双向链表,其元素指向它前面和后面的元素。
这样通过移动到下一个元素可以正向遍历整个链表。通过移动到前一个元素可以反向遍历整个链表。
链表的优点:将元素插入列表的中间位置,使用链表会非常快。
在插入一个元素时,自需要修改上一个元素的Next引用和下一个元素的Previous引用,使他们引用所插入的元素。
在List<T>类中,插入一个元素时,需要移动该元素后面的所有元素。
链表缺点:链表元素只能一个接一个地访问,这需要较长的时间来查找位于链表中间或尾部的元素
链表不能在列表中仅存储元素。存储元素时,链表还必须存储每个元素的下一个元素和上一个元素的信息。这就是LinkedList<T>包含LinkedListNode<T>类型的元素的原因。
使用LinkedListNode<T>类,可以获得列表中的下一个元素和上一个元素。LinkedListNode<T>定义了属性List、Next、Previous、和Value。
List属性返回与节点相关的LinkedList<T>对象,Next和Previous属性用于遍历链表,访问当前节点之后和之前的节点。Value返回与节点相关的元素,其类型是T.
LinkedList<T>类定义的成员可以访问链表中的第一个和最后一个元素(First和Last).
在指定位置插入元素(AddAfter()、AddBefore()、AddFirst()、AddLast()方法)
删除指定位置的元素(Remove()、RemoveFirst()、RemoveLast()方法)
从链表的开头(Find()方法)或结尾(FindLast())开始搜索元素。
有序列表
如果需要基于键对所需集合排序,就可以使用SortedList<TKey,TValue>类。
这个类按照键给元素排序。 这个集合中的值和键都可以使用任何类型。
IComparer<Tkey>接口对象,该接口用于给列表中的元素排序
这个可以用Add()方法和索引器将元素添加到列表中。索引器需要把键作为索引参数。
如果键已存在,Add()方法就抛出一个ArgumentException类型异常。
如果索引器使用相同的键,就用新值替代旧值。
如果尝试使用索引器访问一个元素,但所传递的键不存在,就会抛出一个
KeyNotFoundException 类型的异常。 为了避免这个异常,可以使用ContainsKey()方法,
如果所床底的键存在于集合中,这个方法就返回true.也可以调用TryGetValue()方法,该方法尝试获得指定键的值。如果指定键对应的值不存在,该方法就不会抛出异常,该方法返回类型是bool值 有序列表中存在key 所对应的值就返回true 反之就是false.,该方法第一个参数是key 第二个参数是value(如果有对应的值就带出该值。) out T value
字典
字典表示一种非常复制的数据结构,这种数据结构允许按照某个键来访问元素。
字段称为映射或散列表。字典的主要特性是能根据键快速查找值。也可以自由的添加和删除元素。
这有点像List<T>类,但没有在内存中移动后续元素的开销。
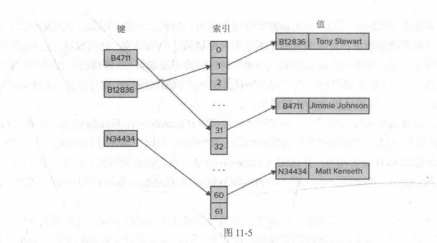
简要说明: 添加到字典中的键。键会转换为一个散列。利用散列创建一个数字。它将索引和值关联起来。然后索引包含一个到值的链接。一个索引像可以关联多个值,索引可以存储为一个树型结构。
//字典初始化器
var dict=new Dictionary<int,string>()
{
[3] ="three",
[7] ="seven"
}
键的类型
用作字典中的键的类型必须重写Object类的GetHashCode()方法。只要字典类需要确定元素的位置,它就要调用GetHashCode()方法。 GetHashCode()方法返回的int由字典用于计算在对应位置放置元素的索引。是又一个算法决定的,这个算法涉及素数,所以字典的容量是一个素数。
GetHashCode()方法的实现代码必须满足如下要求:
相同的对象应总是返回相同的值。
不同的对象可以返回相同的值
他不能抛出异常
它应至少使用一个实例字段
散列代码最好在对象的生存期中不发生变化。
最好还满足以下要求
它应执行得比较快,计算的开销不大。
散列代码值应平均分布在int可以存储的整个数字范围上。散列代码值平均分布在int.MinValue和int.MaxValue之间时,散列得到相同索引的风险会降低到最小。
字典的性能取决于GetHashCode()方法的实现代码。
除了实现GetHashCode()方法之外。键类型还必须实现IEquatable<T>.Equals()方法,或重写Object类的Equals()方法。因为不同的键对象可能返回相同的散列代码,所以字典使用Equals()方法来比较键。字典检查两个键A和B是否相等。并调用A.Equals(B)方法,这表示确保下属条件总是成立。
如果A.Equasl(B)方法返回true。则A.GetHashCode()和B.GetHashCode()方法必须总是返回相同的散列代码。
如果为Equals()方法提供了重写版本 。但没有提供GetHashCode()方法的重写版本,编译器会显示编译警告。
System.Object 这个条件为true,因为Equals()方法知识比较引用。GetHashCode()方法实际上返回一个仅基于对象地址的散列代码。
System.String实现了IEquatable接口,并重载了GetHashCode()方法。Equals()方法提供了值的比较,GetHashCode()方法根据字符串的值返回一个散列代码,因此字典中把字符串用作键非常方便
数字类型(如Int32)也实现IEquatable接口,并重载GetHashCode()方法。但是这些类型返回的散列代码只映射到值上,如果需用用作键的数字本身没有分布在可能的整数值范围内,把整数用作键就不能满足键值的平均分布规则,于是不能获得最佳性能。Int32并不适合在字典中使用。
如果需要使用的键类型没有实现IEquatable接口,并根据存储在字典中的键值重载GetHashCode()方法,就可以创建一个实现IEqualityComparer<T>接口的比较器。IEqualityComparer<T>接口定义了GetHashCode()和Equals()方法,并将传递的对象作为参数。
Dictionary<TKey,TValue>构造函数的一个重载版本允许传递一个实现了IEqualityComparer<T>接口的对象。如果把这个对象赋予字典,该类就用于生成散列代码并比较键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号