solr 基础介绍以及踩坑日记
众所周知,一般采用分布式设计的企业级应用,数据不可能单一的存储,往往会涉及到关系型数据库(mysql/sql等), redis ,以及mongo,solr 等非关系型, 尤其是涉及到APP应用时,快搜选用solr ,业务频繁访问的用mongo+redis, 后台管理可以用mysql ,分布式没错,但需要注意的是数据强一致性和业务高效快捷响应的取舍,要根据不同的需求场景来考虑不同的解决方案,此文不详谈,主要记录solr 的一些基础内容,使用方法,以及避免的坑. (网上关于这一块的内容相对也比较少)
solr 是有可视化界面的,可以直观的校验后台代码对接的数据是否正常,包括增删改查功能,可视化界面如下(常用的功能已标记)
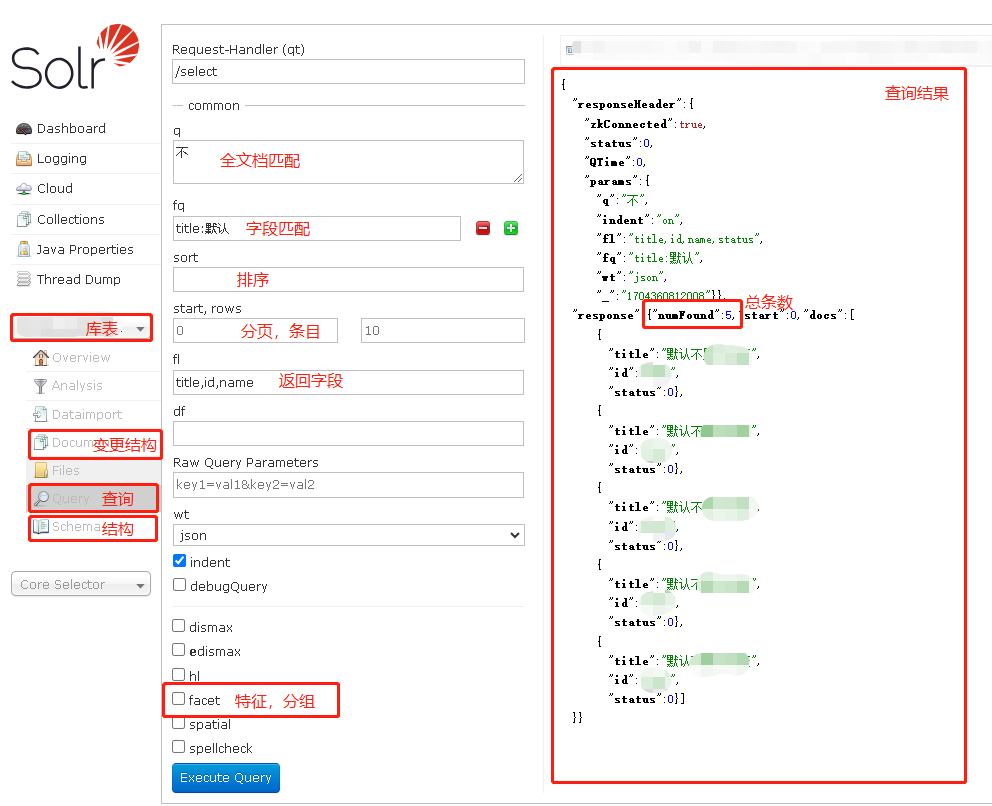
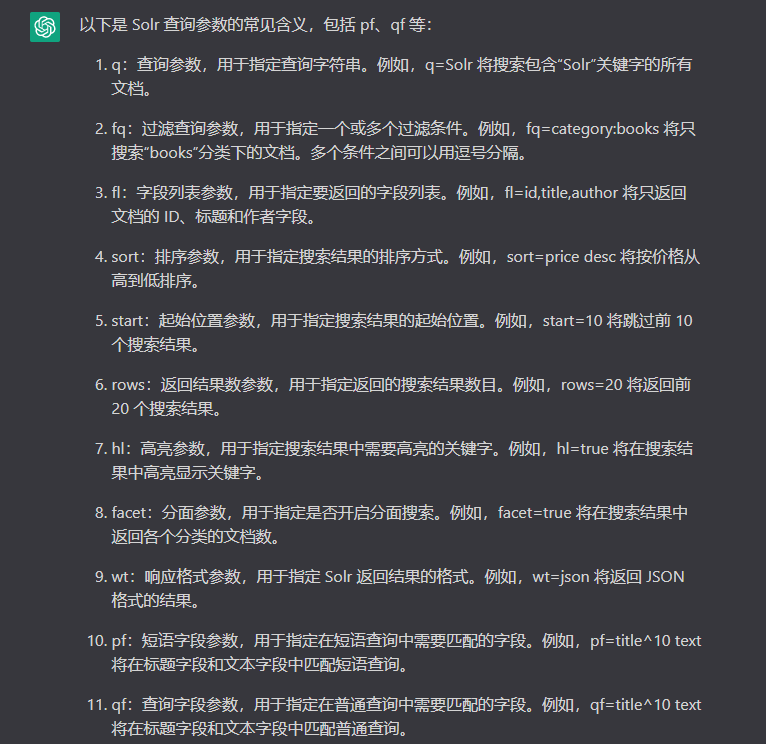
其次就是关于 solr 的一些数据结构,solr主要服务于文档类的业务,数据结构会稍有不同,可直接问话AI, 毕竟这年头AI 针对非数据收集类的回答,多少还是可信的, 对于代码层面的很多解决方案,还有待培训,一知半解或者基础不稳的同学很容易被忽悠住,尽信AI 不如没有AI,
对于其他的一些参数,可以参考 这篇Solr文章
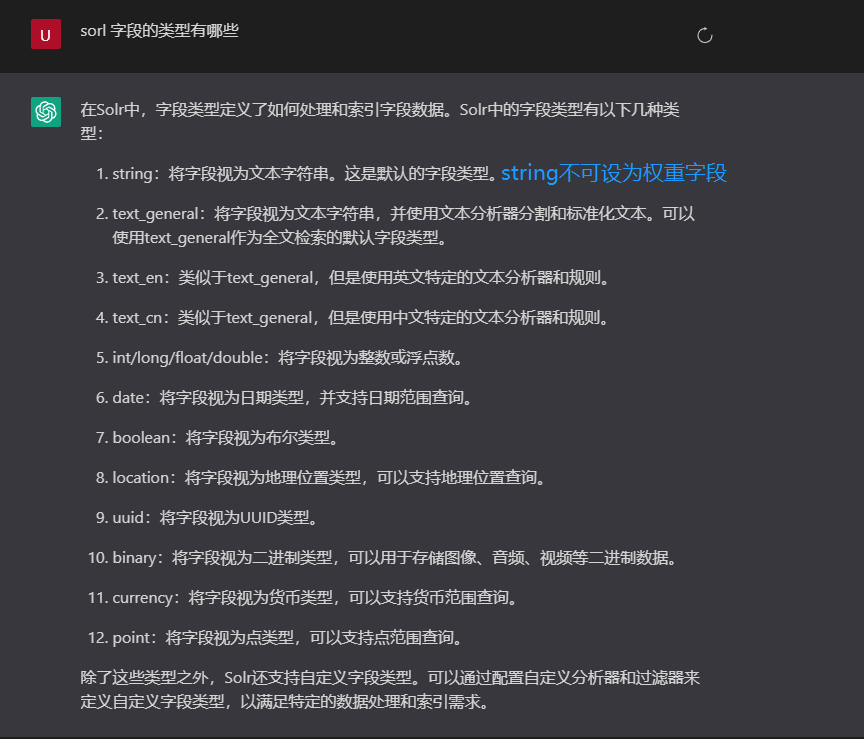
solr 的文档搜索,其实是有所谓的分词一说,针对这些分词(拆分文档内容为词条,然后去搜索匹配词条)会涉及到权重,啥又是权重呢?就是所谓的排名,占比,可以简单的解释为淘宝搜索X商品, 你的店铺是放在第一页被搜索出来还是在第100页才出现,就在这个权重上, 又比如比如我要搜索 姓名A, 标题B,内容C 三个字段中的某个关键词 K, 但是呢,对我来说标题更吸引我一些,内容第二,姓名其次, 那么搜索的结果就可以用到这个权重:
public string Qf { get { return "titlet^10 content^2 name^0.2"; } }
没有这种诉求的话,可以不设置Qf ,Pf 字段, 但是若设置,一定要确认清楚权重的字段类型,不能是string, 要调整为 text_general 才可以, 不然上线各种错误
除此之外,另外一个字段类型需要注意的是,涉及到排序sort 时 , 字段类型选择值类型,如int long 等
solr 基础应用都是以查询,写入为主, 查询即为关键词匹配,上手相对比较容易,需要注意的是英文和中文的过滤规则,一般而言英文,数字,下划线之类的,采用模糊匹配的规则,{字段}*{关键字}* 形式, 中文的话分词匹配 {字段}\"{关键字}\"
solr 稍微高级一点的查询是分组facet查询,类似于列表类的查询,如京东的这种条目展示, 采用solr 实现的话,需要在查询时进行分组 facet 查询, 先查询特征类别,如:床上用品,生活日用,家具饰品等等,拿到这份类别集合后,再进行一次solr 查询,捞取每个特征类别下的二级数据,如床上用品特征下,又分为:床品四件套,婚庆床品,被子,枕头等, 一次请求,内部两次调用solr 查询,返回集合对象的所有数组数据, 最后再由UI进行渲染.
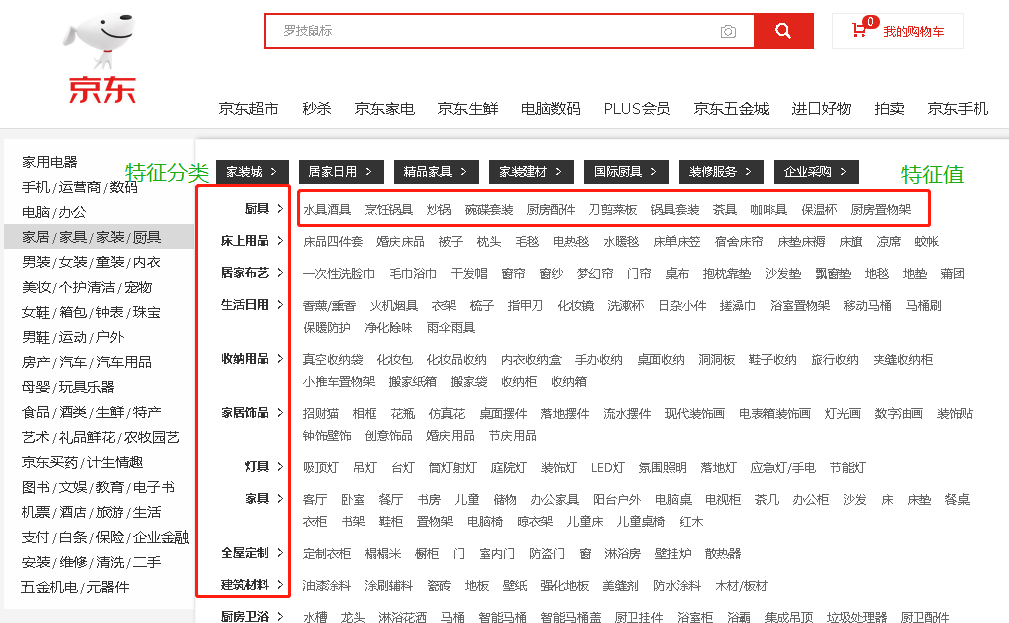
这里讲明一下查询交互,第一次查询通过 SolrFacetFieldQuery 类型的特征A (比如床上用品,生活日用,家具饰品这些大类都打上了A标签,表示家居日用),构建特征集合List (可以是1个,也可以多个),此时solr 返回的查询结果中 有一个叫 FacetFields 的属性,这个集合属性判断是否有值,然后根据特征A筛选 value 值大于0 即可得到一级特征集合(上用品,生活日用,家具饰品等),拿到这个集合之后,同样的去构造 SolrFacetFieldQuery 对象集合,收集完毕后,再进行一轮solr 查询,便能拿到列表列的全部分类数据
if (solrResult.FacetFields.Count > 0) { //读取查询特征结果 var facefilesSec = new List<ISolrFacetQuery>(); var dicKey = solrResult.FacetFields["特征A"].Where(x => x.Value > 0).Select(x => x.Key).ToList();foreach (var item in dicKey) { //设置特征查询分组字段 facefilesSec.Add(new SolrFacetFieldQuery(item)); } //第二次solr分组查询,获取查询结果 var dicFacet = new Dictionary<string, List<string>>(); solrResult = SolrClient.QueryFacet(tenantId, coreName, key, filterQuerys, sort, offset, pageSize, pf, qf, facefilesSec, keyType); }
本文来自博客园,作者:郎中令,世人皆大笑,举手揶揄之,文未佳,却己创,转载请注明原文链接:https://www.cnblogs.com/Sientuo/p/17945842

 浙公网安备 33010602011771号
浙公网安备 33010602011771号