SQL 聚合,开窗函数使用以及行转列操作
关于SQL操作聚合函数,常用的如 Max、Sum、Avg、Count 等等,搭配着Group by 在不考虑性能的情况下,加上一些 inner, where 之类的基本可满足大部分查询要求。从最开始实习到工作一年的时候,查询很少用过其他的函数,但随着接手的业务需求逐渐变多变杂。在考虑到性能的情况下,仅仅掌握这些是不够的,尤其面对某类业务的时,会充斥的大量的子查询,连接查询,不好维护,写的也费劲。
--班级最高分 select MAX(TempScore) MaxScore,ClassName from TestASD group by ClassName --班级平均分 select AVG(CONVERT(float,tempScore)) AvgScore,className from TestASD group by ClassName --班级总分 select SUM(CONVERT(float,TempScore)) SumScore,ClassName from TestASD group by ClassName --班级人数 select COUNT(1) ClassCount,className from TestASD group by ClassName
1. 聚合函数的死结在于查询结果往往会随着 Group by 后面列的增加而发生变化。当需要列出多个列的时候,除聚合函数包含的列以外,均要写在Group by 身后。如下SQL语句
--人数 班级 select COUNT(1) Num,ClassName from TestASD group by ClassName --人数 最高分 班级 select COUNT(1) Num,ClassName,MAX(TempScore) Score from TestASD group by ClassName --人数 最高分 学生 班级 --错误,数据错乱 select COUNT(1) Num,ClassName,MAX(TempScore) Score,UserCode from TestASD group by ClassName,UserCode
针对以上sql语句,对应的查询结果, 可以发现,当第三条sql 语句多增加了一个UserCode的字段时,查询的结果就开始错乱,并不是我们想要的结果,若要得到正确的结果,必然少不了 Inner 查询,我首先想到的是 查询班级,和最高分作为一个表,然后将这个表和第二条查询语句通过班级和分数进行关联,进而查询出需要的结果。一边查询一边进行调整。
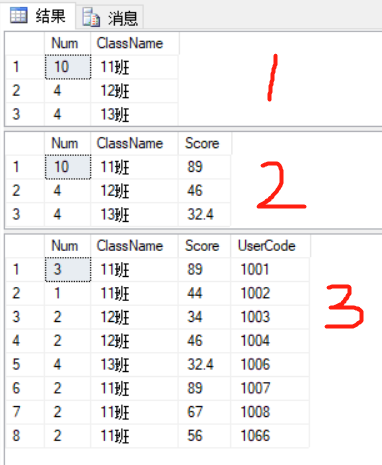
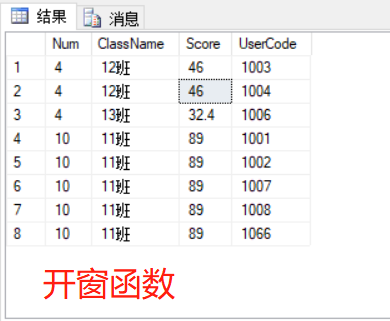
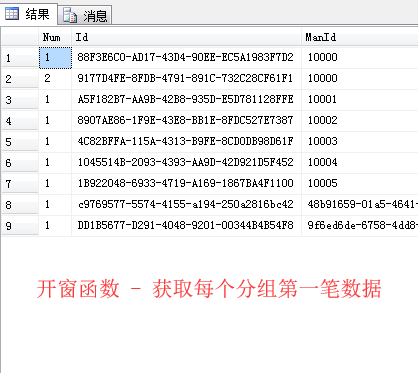
2 .开窗函数则不受Group by 的束缚,可以针对当前行返回多笔数据。语句如下,结果如上。一个是分组获取每个班级的班级人数,另外一个则很适合取每个分组的第一笔数据
--开窗函数 函数(列) over(列) --统计每组的数量和 Select COUNT(1) over(partition by ClassName) Num, ClassName, MAX(TempScore) over(partition by ClassName) Score,UserCode from dbo.TestASD --开窗函数 统计每组的数量(排序) Select ROW_NUMBER() over(partition by ManId ORDER BY ManId) Num,* from ManDetatil
PARTITION BY 函数是独立于结果集创建自己的分区,以上sql语句使用了两个开窗函数,分别是 count() over() 、max() over() ,其各自创建的分区互不影响,一般而言,聚合函数可用于开窗函数,其格式为: 聚合函数(列) + over(列),看到这里,突然有一股似曾相识的感觉,没错,其实经常使用的分页函数,便是开窗函数
Select * from ( Select ROW_NUMBER() over(order by usercode desc) RowNum, * from TestASD )TT Where TT.RowNum between 11 and 20
说到分页,这里顺带记录相关的两个点,
①. 当需要记录总条数时,使用开窗函数 over() 后面不加列,则针对结果集所有行进行计算
②. 除了Row_Number() 可以排序以外,还有Rank(),Dense_Rank() 函数进行排序,当需要计算学生所在的班级排名,年级排名的时候用起来贼方便
Select COUNT(1) over() TolCount, ROW_NUMBER() over(order by Convert(float,TempScore) desc) RowNum, --按顺序,1,2,3,4,5.... RANK() over(order by Convert(float,TempScore) desc) RanNum, --并列排名,之后排名自动延后 1,2,3,3,3,6,6,8 Dense_rank() over(order by Convert(float,TempScore) desc) DRanNum, --并列排名,之后排名继续,不延后 1,2,3,3,3,4,4,5
* from TestASD
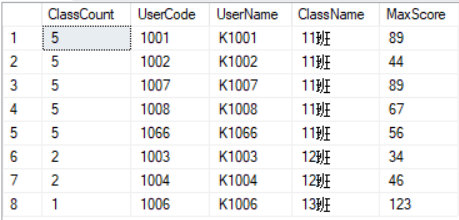
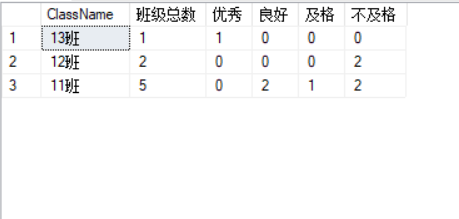
3. 行转列,这样的需求也挺多的,最常见的,如某表记录了学生姓名,成绩,班级,此时需要查询每个班级 优秀(90+),良好(80+),及格(60+),不及格(60-) 的人数
With XX as( Select COUNT(1) over(PARTITION by ClassName) ClassCount,* from( Select distinct UserCode,UserName,ClassName, MAX(CONVERT(float,TempScore)) over(partition by Usercode) MaxScore from TestASD)T ) --SUM+Case 进行行转列 Select ClassName, ClassCount 班级总数, SUM(case when MaxScore >=90 then 1 else 0 end) 优秀, SUM(case when MaxScore>=80 and MaxScore<90 then 1 else 0 end) 良好, SUM(case when MaxScore>=60 and MaxScore<80 then 1 else 0 end) 及格, SUM(case when MaxScore<60 then 1 else 0 end) 不及格 From XX group by ClassName,ClassCount
切记,使用Group by 时,后面带的列,一定要考虑清楚,多想想,这里坑比较多,下面时查询结果,对比行专列前后
以上这些,会用之后,查询基本上不会像以前那么头疼....
本文来自博客园,作者:郎中令,世人皆大笑,举手揶揄之,文未佳,却己创,转载请注明原文链接:https://www.cnblogs.com/Sientuo/p/12888163.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号