

kafka详解
一.kafka概念
-
kafka是 分布式,支持分区的,多副本的基于zookeeper协调的分布式消息系统
-
DMQ(Distributed Message Queue)
DMQ是一个消息中间件,传递消息
-
发布-订阅模式(生产者-消费者)
二.常见术语
-
Broker:
Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群无状态的,不管offset
-
Topic:
一类消息,消息存放的目录即主题 -
Partition:
topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列partition中每个message能被多个组消费,但在一个组中只能被一个consumer消费(所以不需要锁机制)
-
Segment:
partition物理上由多个segment组成,每个Segment存着message信息 -
Producer :
生产message发送到topic;producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘;
-
Consumer :
订阅topic消费message, consumer作为一个线程来消费顺序读取,记录消费的物理偏移量(offset)的位置
-
Consumer Group:
一个Consumer Group包含多个consumer -
replica:
partition的副本,保障partition高可用
-
leader:
replica中的一个角色,producer和consumer只跟leader交互
-
follower:
replica中的一个角色,从leader中复制数据
-
controller:
kafka集群中其中一个服务器,用来进行leader election
三.设计思想
Kakfa Broker集群受Zookeeper管理;
一个consumer group消费一个topic时一定会消费完全部的partition,;
一个组中consumer thread数量和partition数量相同时效率最高;数量不相同时则会出现一消费多或者空闲的情况;
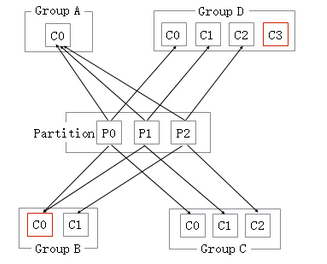
线上的分布式多个service服务,每个service里面的kafka consumer数量都小于对应的topic的partition数量,但是所有服务的consumer数量只和等于partition的数量;
一般这种情况都是两个不同的业务逻辑,才会启动两个consumer group来处理一个topic
四.面试题
1.为什么要使用 kafka,为什么要使用消息队列
缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
2.kafka中的 zookeeper 的作用
kafka依赖zk,kafka的集群管理,负载均衡由zk实现
3.kafka follower如何与leader同步数据
kafka使用ISR(In-Sync Replicas 副本同步队列)的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
4.kafka中consumer group 是什么
同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据;
5.Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
五.其他链接
Kafka常见面试题
六.其他临时
######################################
java.lang.IllegalArgumentException: System memory 468189184 must be at least 4.718592E8
https://blog.csdn.net/liuxiangke0210/article/details/53909739
IDEA运行异常java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function
https://www.cnblogs.com/parent-absent-son/p/10064856.html
######################################
ERROR org.apache.spark.SparkContext - Error initializing SparkContext.
java.lang.IllegalArgumentException: System memory 129761280 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
Spark程序运行报错:JVM申请的memory不足解决办法
https://blog.csdn.net/wypersist/article/details/80140334
#######################################
######################
[INFO] java.lang.reflect.InvocationTargetException
[INFO] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
[INFO] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
[INFO] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke(Method.java:497)
[INFO] at org_scala_tools_maven_executions.MainHelper.runMain(MainHelper.java:161)
[INFO] at org_scala_tools_maven_executions.MainWithArgsInFile.main(MainWithArgsInFile.java:26)
[ERROR] Caused by: java.lang.OutOfMemoryError: Java heap space
[INFO] at java.util.jar.Manifest$FastInputStream.
[INFO] at java.util.jar.Manifest$FastInputStream.
[INFO] at java.util.jar.Manifest.read(Manifest.java:195)
[INFO] at java.util.jar.Manifest.
[INFO] at java.util.jar.JarFile.getManifestFromReference(JarFile.java:199)
[INFO] at java.util.jar.JarFile.getManifest(JarFile.java:180)
[INFO] at sun.misc.URLClassPath$JarLoader$2.getManifest(URLClassPath.java:944)
[INFO] at java.net.URLClassLoader.defineClass(URLClassLoader.java:450)
[INFO] at java.net.URLClassLoader.access$100(URLClassLoader.java:73)
[INFO] at java.net.URLClassLoader$1.run(URLClassLoader.java:368)
[INFO] at java.net.URLClassLoader$1.run(URLClassLoader.java:362)
[INFO] at java.security.AccessController.doPrivileged(Native Method)
[INFO] at java.net.URLClassLoader.findClass(URLClassLoader.java:361)
[INFO] at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
[INFO] at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
[INFO] at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
[INFO] at scala.tools.nsc.util.package$.stackTraceString(package.scala:75)
[INFO] at scala.tools.nsc.Global.throwableAsString(Global.scala:316)
[INFO] at scala.tools.nsc.Global.reportThrowable(Global.scala:315)
[INFO] at scala.tools.nsc.Driver.process(Driver.scala:54)
[INFO] at scala.tools.nsc.Driver.main(Driver.scala:64)
[INFO] at scala.tools.nsc.Main.main(Main.scala)
[INFO] ... 6 more
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:51 min
[INFO] Finished at: 2020-11-05T09:44:19+08:00
[INFO] Final Memory: 62M/149M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.scala-tools:maven-scala-plugin:2.15.2:compile (default) on project NewsFeed: wrap: org.apache.commons.exec.Execute
Exception: Process exited with an error: -10000(Exit value: -10000) -> [Help 1][ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR][ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR][Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR][ERROR] After correcting the problems, you can resume the build with the command
####################
流任务性能提升
数据倾斜,怎么处理
