寻虫记:BOM头制造的冤案,无故多出空白行
最近在做的一个网站发生了一个很诡异的BUG:
- 使用IE浏览页面时,一切都挺正常;
- 而使用Firefox浏览时,发现某些页面元素之间的距离比预期的要宽很多,HTML元素本身的hight、padding和margin值都很正常,只是元素之间像是增加了一个空行或一个类似于DIV的块级元素;用F12调出开发者工具查看后却没有发现任何多出的HTML元素或多余的代码;
- 再用Chrome进行查看,页面的显示效果和firefox一样,但是用F12查看后,发现确实是增加了多余的一行,表现为增加了一个空白字符串,但是占有一个整行的宽度。如下图中header元素的上下所示:
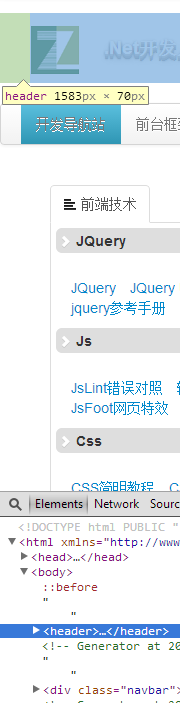
接下来排查错误:
一开始以为是CSS样式中的:before语句对页面元素有了影响,但是:before仅对body元素进行了设置,仅仅只是增加了一个元素,不会造成如此多的元素的间隔距离都拉开了的效果;且在删除:before语句后浏览,问题依然存在。因此排除了这个可能性。
然后开始仔细的检查(过程很痛苦),发现这些出问题的地方都有一个共同点:因为网站是采用静态化实现,使用了服务器端的静态包含,而每个多余的行都出现在每个包含文件(<!--#include virtual="**.inc" -->)的前面。于是去看包含文件的生成过程,去掉文件生成时头尾可能产生的换行符和空白串。但是更新程序后,重新生成静态文件,问题仍然存在。
后来实在找不到问题所在,只能先放一下去完成其他的功能。但是,这个没有解决的问题,一直萦绕在我的心头,时时都能想起它,时时都在想“为什么呢”?如鲠在喉,无法下咽。总觉得有什么事情没做完一样,做其他的事情时感觉也不踏实。
因为基本确认是包含文件出现了问题,于是集中在文件生成和包含这一块进行排除。在做其他事的时候无意中想到文件编码这一块的事情,于是就想会不会是这个因素的影响。于是上网搜索,发现了如下几篇文章:
1、什么是BOM头
3、XML的BOM
看完后,隐约觉得应该是找到问题所在了;于是看了看自己程序,发现在生成静态文件时,采用了UTF-8编码来设置字节流,同时在保存到文件时也采用了UTF-8编码,代码如下:
File.WriteAllText(Task.FullPath + filename + Task.Extension, content, Encoding.UTF8);
于是决定首先利用UE去除BOM头试试效果:打开某一个静态化后的inc文件,另存为时选择“UTF-8 无 BOM”,能BOM头。如下图:
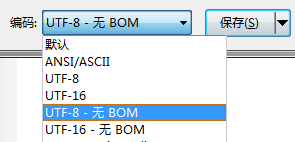
保存文件后再进行浏览,问题不再出现。从而确定了BOM头在一些浏览器内解析时,会被解析为一个空行或者一个块级元素。在用程序保存文件时,如果指定了文件的编码格式为UTF-8,也会为文件增加BOM头。
因此生成文件时,改为去掉文件保存时指定的UTF-8编码,但字节流仍采用UTF-8编码处理。
content = Encoding.UTF8.GetString(bytes);
File.WriteAllText(Task.FullPath + filename + Task.Extension, content);
同时因为字节流采用UTF-8编码,在html页面里需要指定页面的编码方式,不然会出现乱码:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
做完以上处理,再次重新生成所有inc文件后,在不同浏览器下刷新查看,发现问题均得到解决。
在确认了BUG的原因并最终解决了问题之后,居然找到了这样一篇文章:关于shtml页面include问题解决方案因为utf-8的BOM头引起的出现一个空行 !!为什么总是在费尽九牛二虎之力解决问题后,才发现这么一篇能精确指导解决问题的方案的文章呢?
另外,推荐一个关于编码方面的文章:由web程序出现乱码开始挖掘(Bom头、字符集与乱码)
做程序开发,确实是知道得越多,知道的就越少。坑太多啊。绝逼的学无止尽。
Difficulty of making decision depends on what to lose not gain

 浙公网安备 33010602011771号
浙公网安备 33010602011771号