Scrapy 入门笔记
scrapy框架
scrapy
scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构化数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。
安装scrapy
conda install scrapy
scrapy项目的创建和运行
创建scrapy项目
scrapy startproject 项目名称
注意:
- 项目名称不能以数字开头
- 项目名称不能含有中文
scrapy项目结构
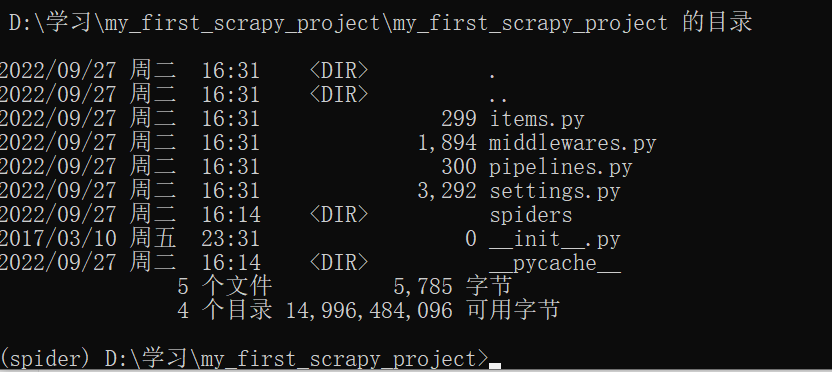
scrapy项目结构解析
spiders文件夹存储的是爬虫文件
items文件是定义数据结构的地方,爬取的数据都有哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
注意:我们所写的爬虫程序都存放在spiders文件夹中
scrapy创建爬虫文件
cd 项目名称\项目名称\spiders
scrapy genspider 爬虫名称 要爬取网页的url地址(不需要添加协议头)
注意:这里不需要添加协议头是因为在创建好的爬虫文件中的start_urls会自动添加协议头
scrapy爬虫文件代码结构
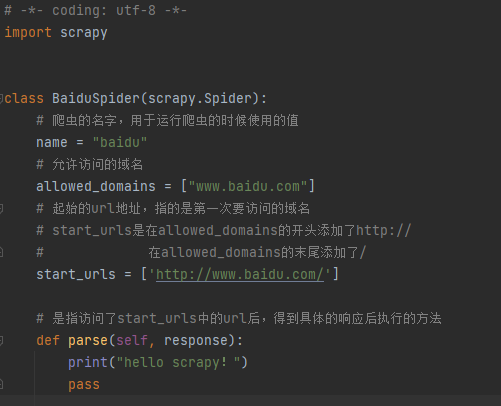
注意:
- allowed_domains限制了我们所能爬取的网站
- start_urls表示我们要开始访问的第一个url
scrapy运行爬虫
scrapy crawl 爬虫名称
scrapy-robots协议
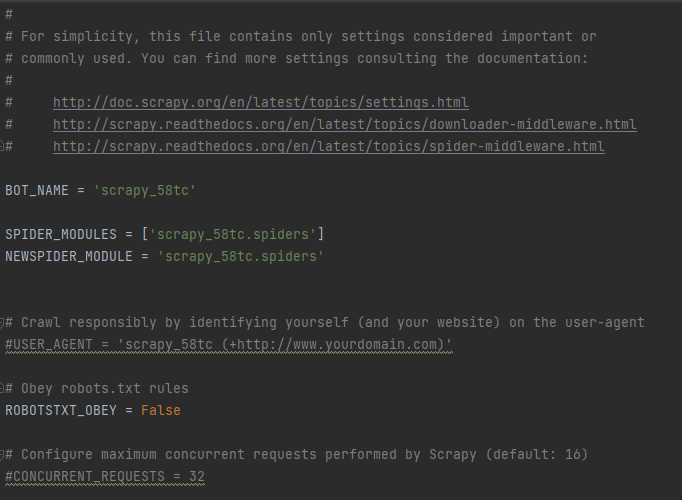
在scrapy创建的爬虫项目中,settings.py 存在如下设定:
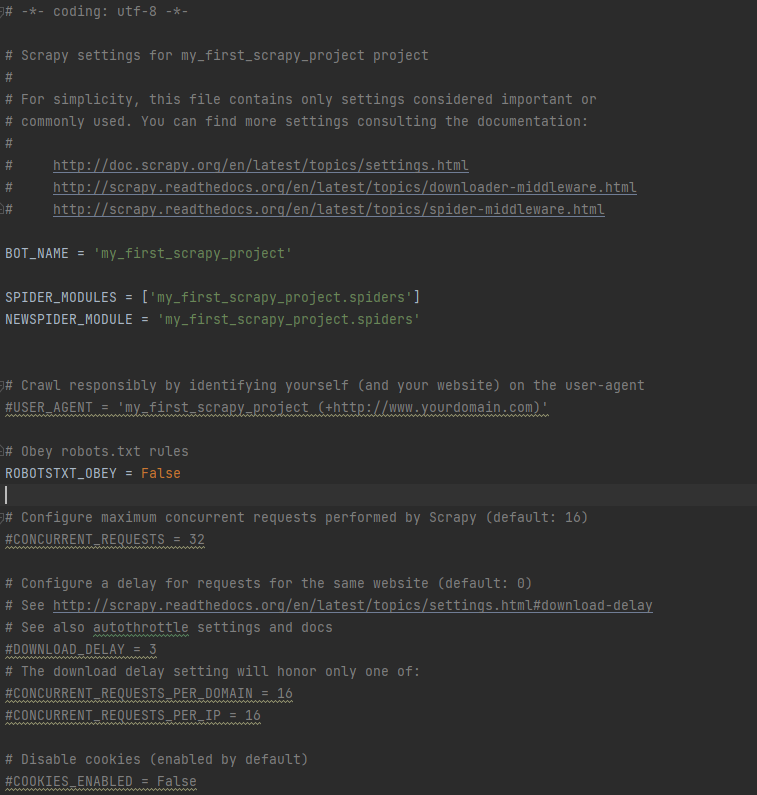
注意:
- 其中的ROBOTSTXT_OBEY = False 表示不遵守爬取网站所设置的robots协议,该配置项默认值为True
- robots.txt是一般网站针对爬虫所设置的“君子协议”,其中规定了不同类型的爬虫所能爬取的内容以及不能爬取的内容
scrapy58同城案例
创建项目

进入爬虫文件目录并创建爬虫
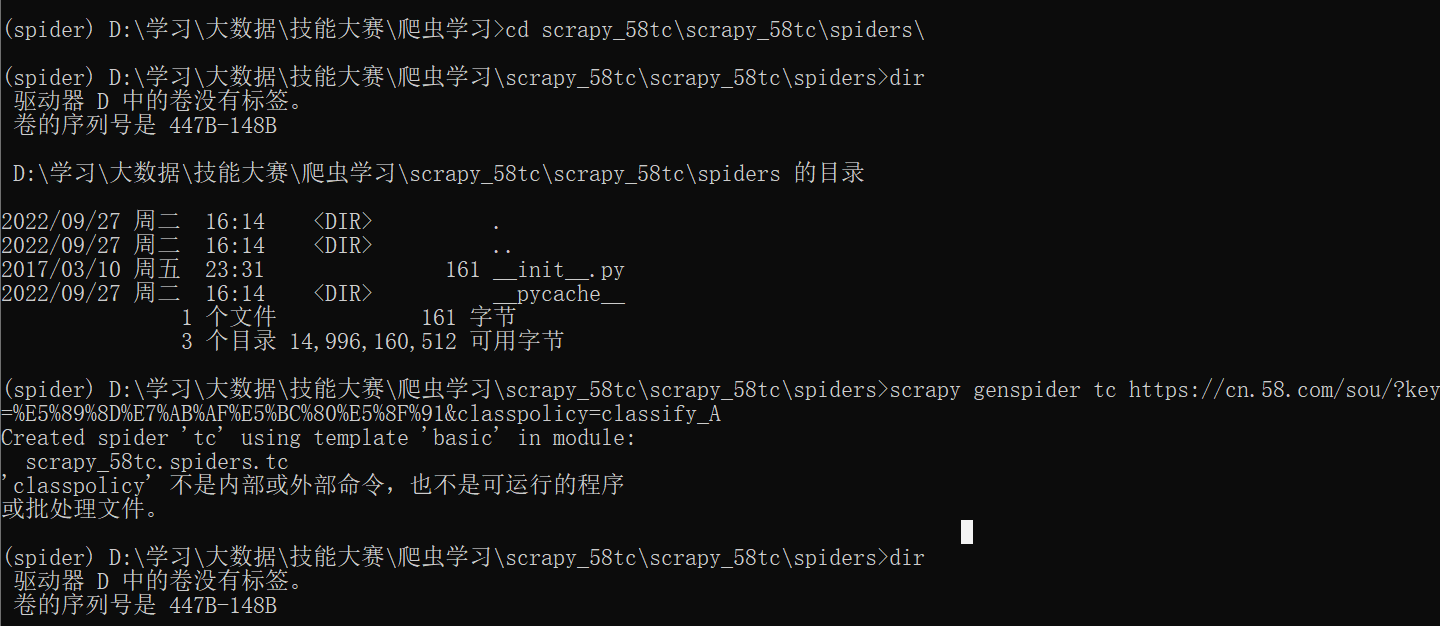
编辑创建的爬虫文件
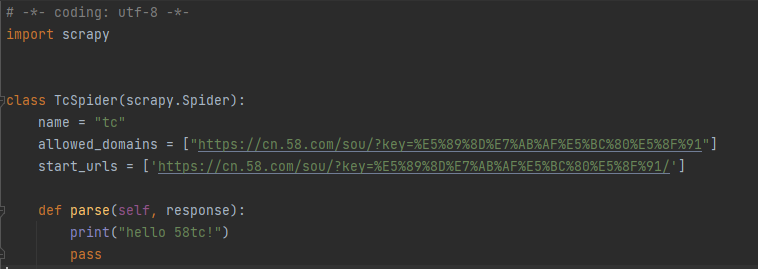
注意:
- 如果在创建爬虫时,指定爬取的url时,添加了协议头,这里的start_urls会产生多余的协议头,需要将其去除
- 如果请求的接口是以html结尾,最后的/可以去掉
运行tc爬虫
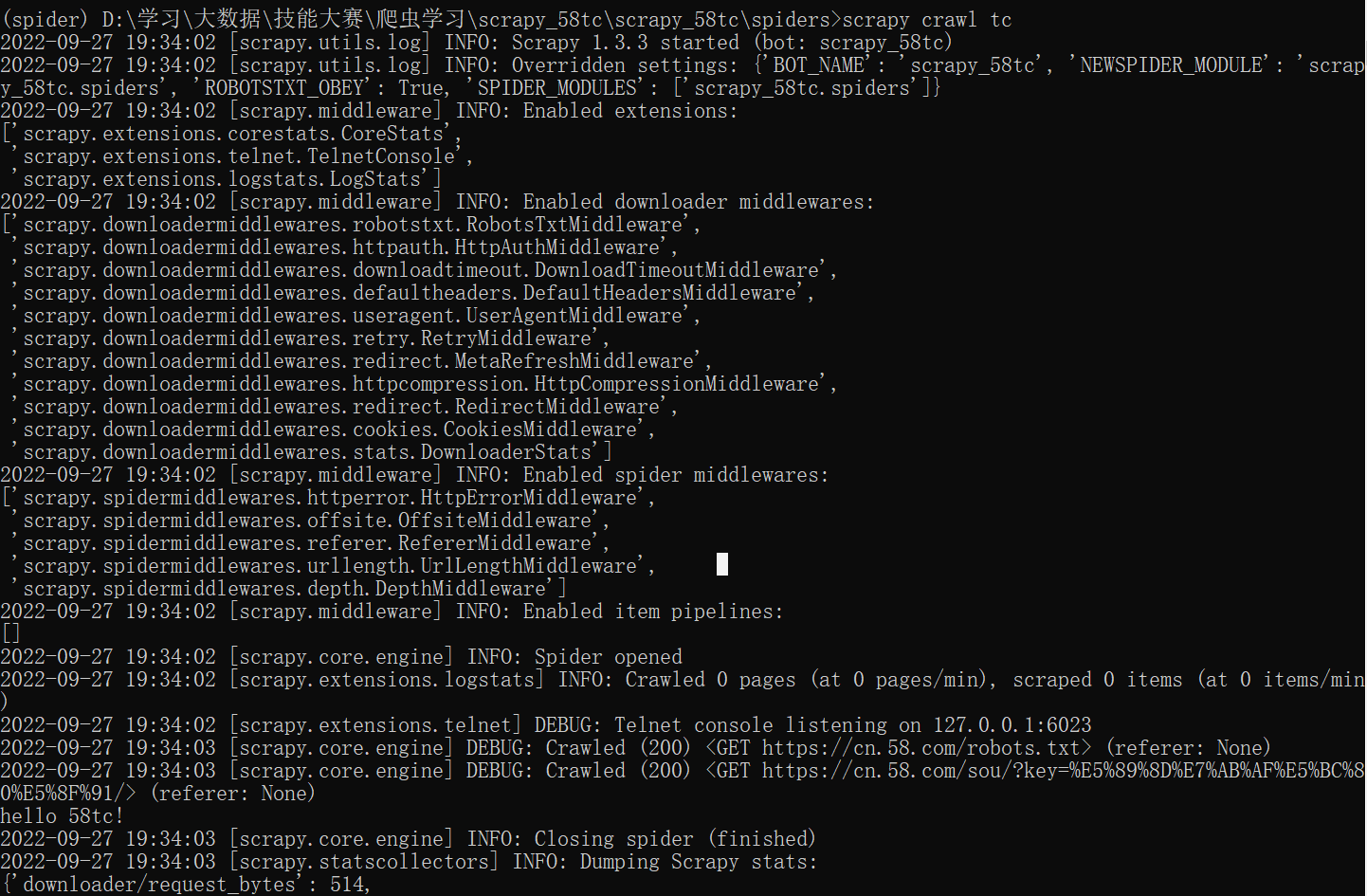
从上图中可以看出,我们的请求没有得到响应,被爬取网站可能设置了相关反爬措施,也有可能我们的爬虫遵守了robots.txt,先将我们编写的爬虫文件设置不遵守robots.txt协议
重新运行
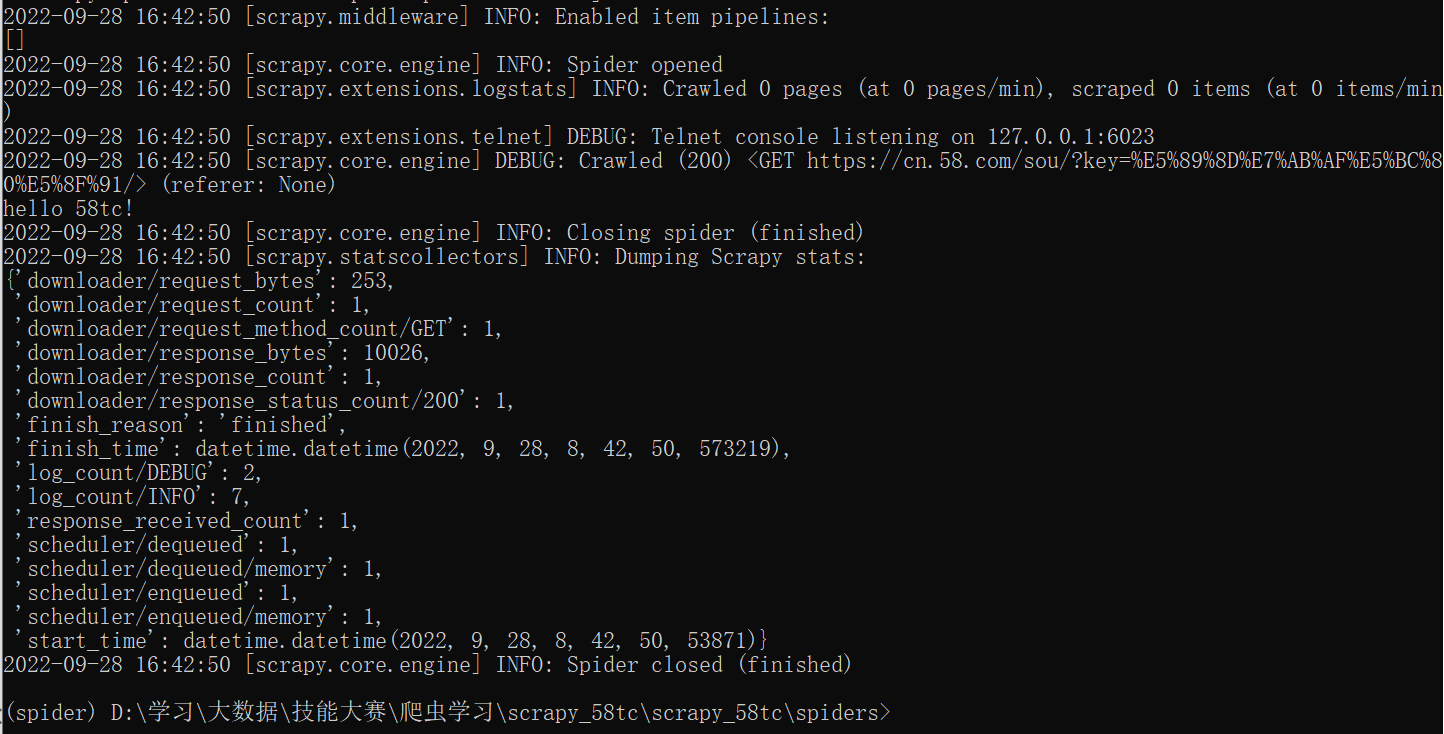
scrapy shell
scrapy shell简介
scrapy shell,是一个交互终端,供您在未启动spider的情况下尝试及调试您的代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的python终端,在上面测试任何的python代码。
该终端是用来测试xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
注意:scrapy shell是基于ipython实现的,所以需要安装ipython,具体安装命令如下:
pip install ipython
scrapy shell 基本使用
直接进入windows终端下,输入以下命令:
scrapy shell 域名
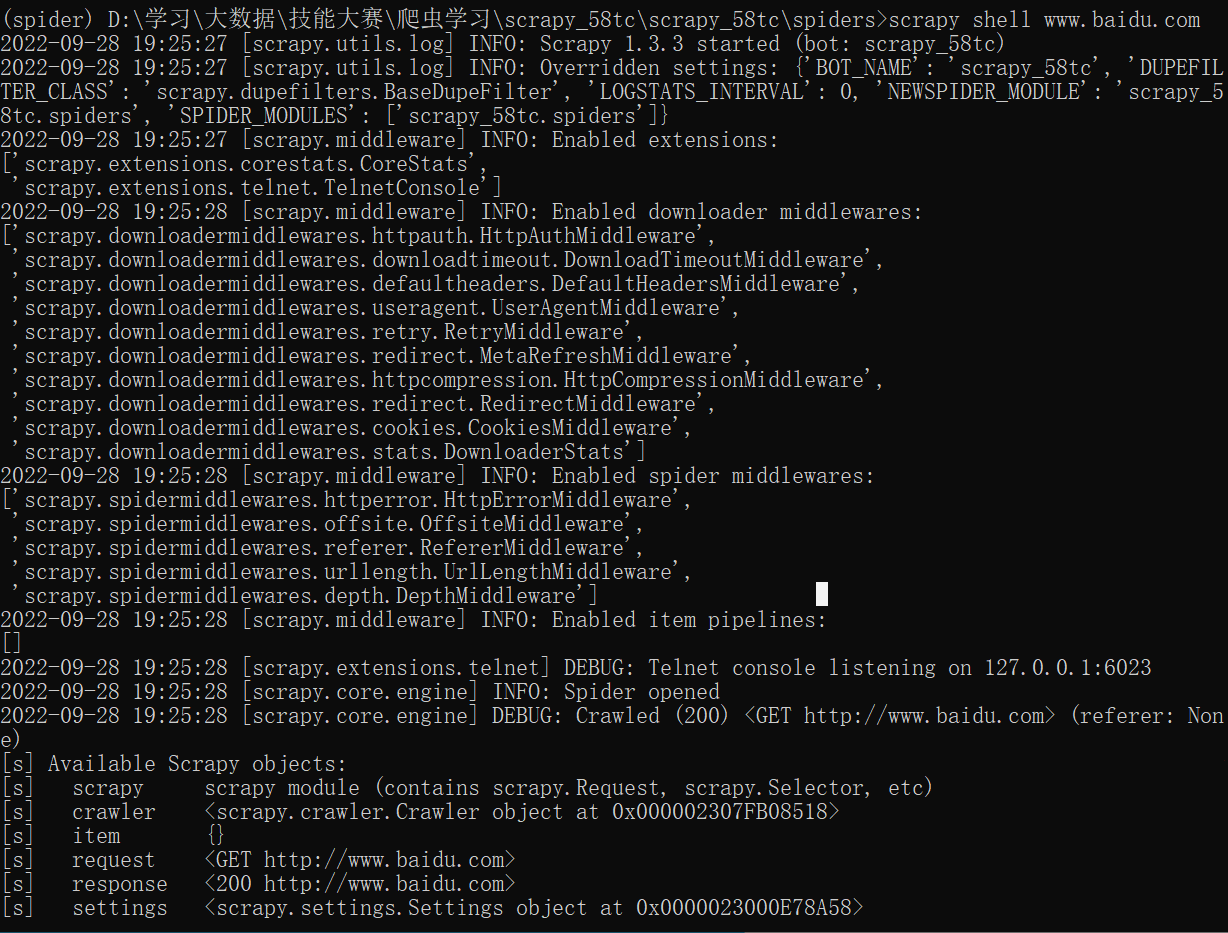
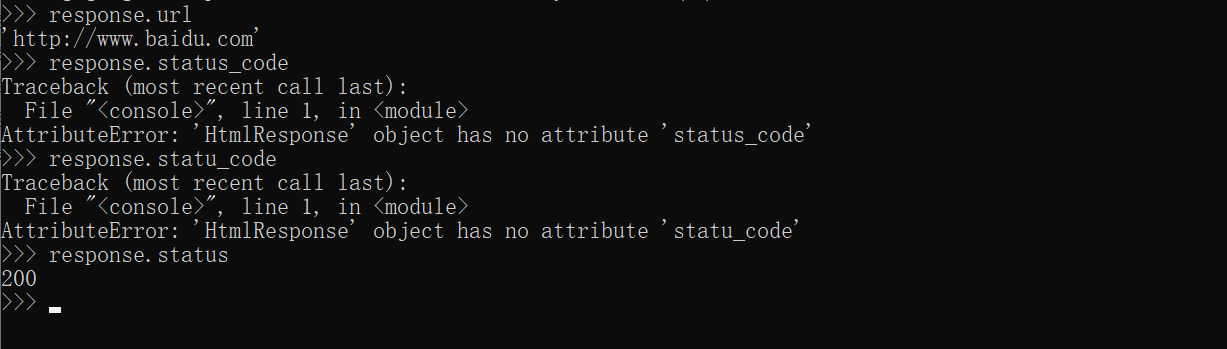
运行完上述命令后,我们会进入python终端,并且已经生成了 访问我们传入域名的response对象,可以直接对其进行一系列的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号