
网络编程笔记(一)-基本TCP套接字编程
网络编程笔记(一)-基本TCP套接字编程
参考《UNIX网络编程》1 - 4 章,《TCP/IP网络编程》1 - 5 章。
基础知识
基本概念
-
守护进程(daemon):一般认为 Web 服务器程序是一个长时间运行的程序,它只在响应来自网络的请求时才发送网络消息。守护进程能在后台运行且不跟任何终端关联。
-
TCP 套接字的花哨名字:网际(AF_INET)字节流(SOCK_STREAM)套接字
-
时间获取服务器的众所周知端口:13
-
协议无关性:
将 IPv4 修改为 IPv6 协议
- sockaddr_in ——> sockaddr_in6
- AF_INET ——> AF_INET6
- sin_port ——> sin6_port
更好的做法是编写协议无关程序。
-
包裹函数
weapper function。在本书中,约定包裹函数名是实际函数名的首字母大写形式。每个包裹函数完成实际的函数调用,检查返回值,并在错误时终止进程。
int Socket(int family, int type, int protocol){ int n; if( (n = socket(family, type, protocol)) < 0) err_sys("socket error"); return(n); } -
Unix errno 值:只要有一个 UNIX 函数中有错误发生,全局变量 errno 就被置为一个指明该错误类型的正值,函数本身则通常返回 -1。err_sys(作者定义的)查看 errno 变量的值并输出相应的出错信息。
-
服务器种类:
-
迭代服务器:对于每个客户都迭代执行一次
-
并发服务器:同时处理多个客户(Unix 的 fork 函数,用线程替代 fork 等)
-
-
国际标准化组织(International Organization for Standardization,ISO)的计算机通信开放系统互连模型(open systems interconnection,OSI),是一个七层模型。
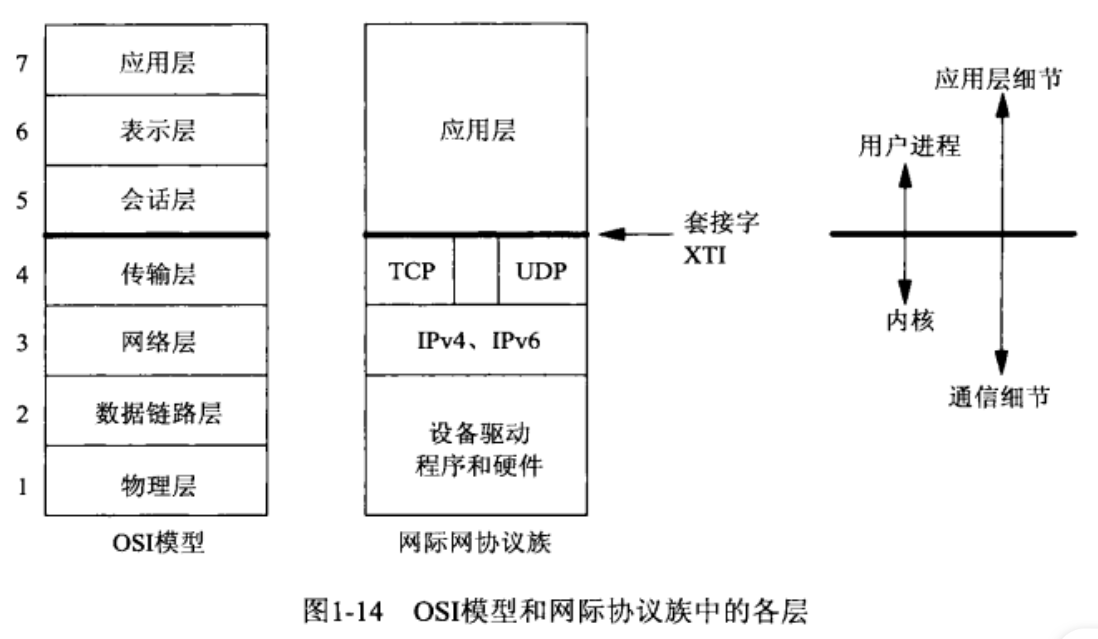
物理层/数据链路层:随系统提供的设备驱动程序和网络硬件。
网络层:由 IPv4 和 IPv6 这两个协议处理。在附录 A 中讲述。
传输层:即本书所讲的套接字编程接口,从应用层(上3层)进入传输层的接口。
会话层/表示层/应用层:OSI 的顶上三层被合并为一层,称为应用层。Web 客户端(浏览器)、Telnet 客户、web 服务器、FTP 服务器等在这层。
《Unix 网络编程》讲述的套接字编程接口是从顶上三层(网际协议的应用层)进入传输层的接口,重点关注如何使用套接字编写使用 TCP 或 UDP 的网络应用程序。
套接字提供的是从OSI模型的顶上三层进入传输层的接口,这里设计有两个原因:
-
理由一:顶上三层处理具体网络应用(如 FTP、Telnet 或 HTTP)的所有细节,却对通信细节了解很少;底下四层对具体网络应用了解不多,却处理所有的通信细节:发送数据,等待确认,给无序到达的数据排序,计算并验证校验和等等。
-
理由二:顶上三层通常构成所谓的用户进程(user process),底下四层却通常作为操作系统内核的一部分提供。Unix 与其他现代操作系统都提供分隔用户进程与内核进程的机制。由此可见,第 4 层和第 5 层之间的接口是构建 API 的自然位置。
-
POSIX(Portable Operating System Interface,可移植操作系统接口)
- 64 位体系结构:LP64 模型中,长整数(L)和指针(P)都占用 64 位。
相关 linux 指令
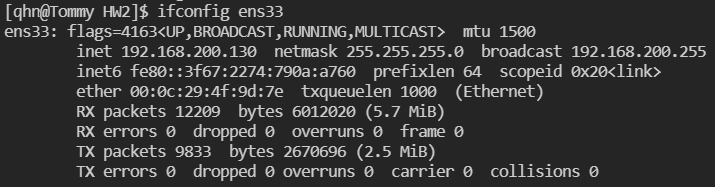
netstat -ni:提供网络接口信息,-n 输出数值地址而不是反向解析为名字。其中 loopback 接口称为 lo,以太网接口称为 eth0(这里是 ens33)。

netstat -nr:查看路由表

ifconfig ens33:获得 ens33 以太网接口的详细信息
-
ping -b 192.168.200.255:对本地接口的广播地址执行 ping ,可以找到本地网络中其他主机的 IP 地址。 -
Linux ps(英文全拼:process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器
-
grep:Global regular expression print
计算机网络基础
-
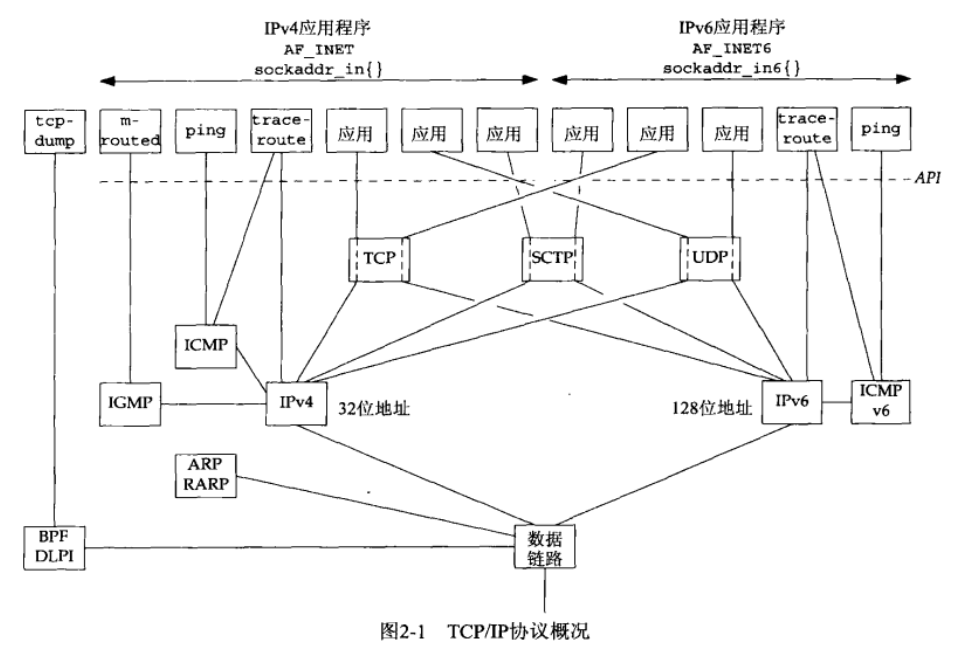
TCP 提供面向连接的、可靠的、排序、流量控制、全双工的数据传送服务。
-
UDP 提供无连接的、不可靠的、尽力服务。发送给接收进程的数据有可能丢失,也有可能错序。
-
SCTP:流控制传输协议。提供可靠全双工关联的面向连接的协议。
使用关联来指代 SCTP 的连接:一个连接只涉及两个 IP 地址之间的通信,一个关联指代两个系统之间的一次通信。
- SCTP 是多宿的,单个 SCTP 端点能够支持多个 IP 地址。
- SCTP 面向消息,它提供各个记录的按序递送服务。
TCP 的建立和终止
TCP 三路握手建立连接:
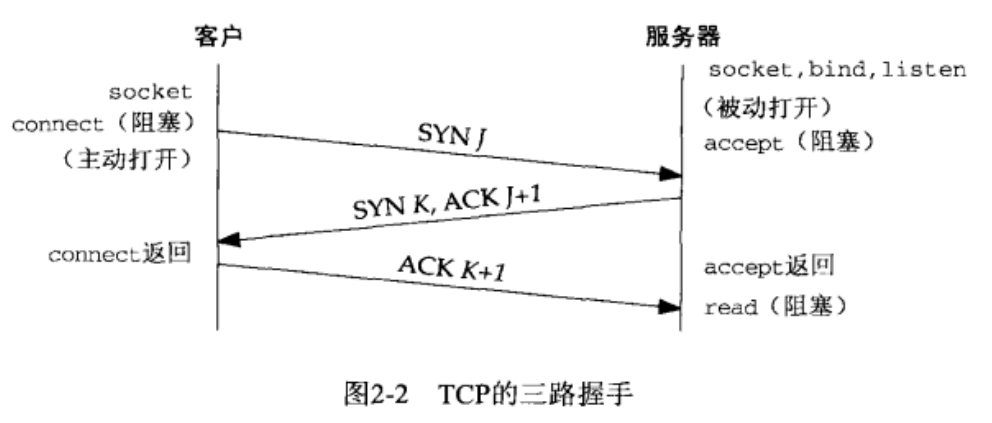
- 服务器被动打开 (passive open):服务器调用 socket、bind、litsen 函数,准备好接受外来连接。
- 客户主动打开 (active open):客户调用 connext,发送 SYN 报文,告诉对方初始序号。通常 SYN 报文不携带数据,其所在的 IP 数据报只包含一个 IP 首部、一个 TCP 首部和可能有的TCP选项。
- 服务器必须确认(ACK)客户的 SYN:服务器在单个分节中,发送自己要发送数据的初始序列号 SYN 和对客户 SYN 的确认(ACK)。
- 客户必须确认服务器的 SYN,发送 ACK。
TCP选项:
- MSS 选项:通告对端自己的最大报文段长度(maximum segment size)
- 窗口规模选项:通告对端的最大窗口大小(advertised window size)为 65535(16 bits),但现在要求更大的窗口,必须左移 0~14 位。
- 时间戳选项:防止失而复现的分组可能造成的数据损坏。窗口规模选项和时间戳选项也称长肥管道选项。
TCP 四路握手释放连接:
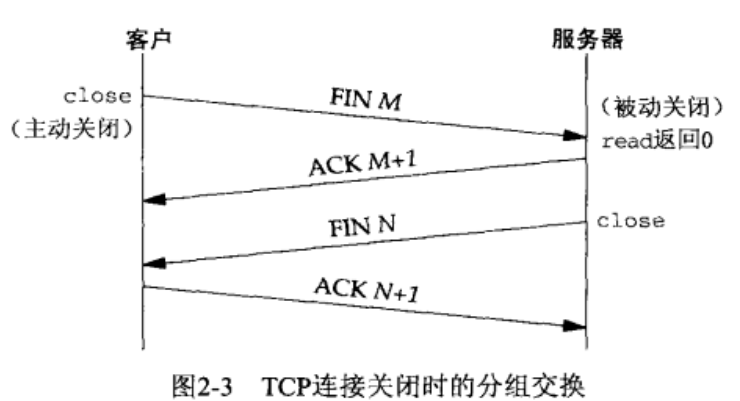
- 主动关闭 (active close):某个应用进程首先调用 close,发送一个 FIN 分节表示自己的数据发送完毕。
- 被动关闭 (passive close):TCP 确认这个 FIN,它的接收也作为一个文件结束符(EOF)传递给接收端应用进程(FIN 意味着无额外数据可接收)。
- 一段时间后,接收 FIN 的进程将会调用 close 关闭自己的套接字,它的 TCP 也发送一个FIN。
- 接收到最终 FIN 的原发送端 TCP 确认这个 FIN。
半关闭 (half-close):被动关闭一端向主动关闭一端流动数据。
当一个 Unix 进程不论自愿地(调用 exit 或从 main 函数返回)还是非自愿地(收到一个终止本进程的信号)终止时,所有打开的描述符都被关闭,这也导致仍然打开的任何 TCP 连接上也发出一个 FIN。
TCP 状态转移图
理解状态转换图是使用 netstat 命令诊断网络问题的基础。
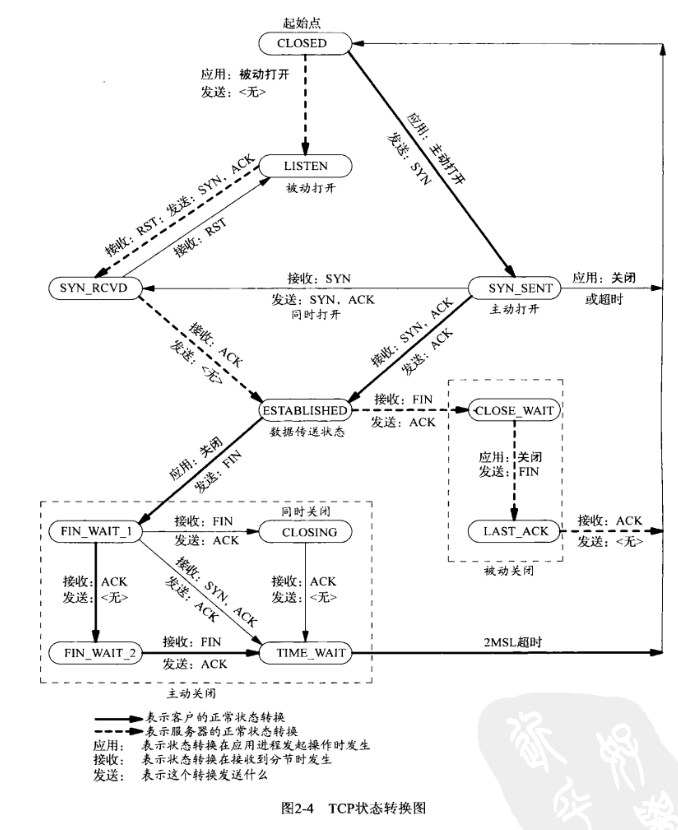
TIME_WAIT状态
TIME_WAIT:停留在这个状态的持续时间是最长报文段生命期(maximum segment lifetime,MSL)的两倍,也称 2MSL。
TIME_WAIT 状态存在的两个理由:
- 可靠地实现 TCP 全双工连接的终止:最终的 ACK 需要维护状态,比如 ACK 丢失需要重传,否则会响应 RST
- 允许老的重复报文段在网络中消逝:正确处理重复的分组——迷途的重复分组/漫游的重复分组。
端口号
端口的作用:
-
让应用层的各种应用进程将其数据通过端口 向下 交付给传输层
-
让传输层知道应当将其报文段中的数据 向上 通过端口交付给应用层相应的进程
端口是传输层的服务访问点 (SAP):数据链路层的 SAP 是 MAC 地址,网络层的 SAP 是 IP 地址,传输层的 SAP 是端口
端口号:标识计算机应用层中的各进程
UDP 协议和 TCP 协议如何知道把收到的数据段交给哪个上层进程呢?利用数据段 (segment) 中的目的端口号 (2个字节)
端口号分类:
-
IANA 的知名端口(Well-known ports,也称众所周知端口)0~1023
为提供知名网络服务的系统进程所用。 例如: 20-ftp Data,21-ftp Control,23-telnet,
25-SMTP,53-DNS,69-TFTP,80-HTTP,110-POP3,161-SNMP。Unix 系统的保留端口(reserved port)指的是小于 1024 的任何端口,所有知名端口都是保留端口。
-
注册端口(Registered ports)1024~49151。在 IANA 注册的专用端口号,为企业软件所用。
-
动态端口(Private ports)49152~65535。没有规定用途的端口号,一般用户可以随意使用。也称为私用或暂用端口号。
套接字 (Socket)
(1) 通过IP地址或域名找到主机: www.baidu.com->36.152.44.96
(2) 通过端口号找到主机上的进程
套接字是网络数据传输用的软件设备,网络编程又称套接字编程。
套接字函数是 TCP 协议的编程接口,每个 TCP 套接字都有自己的接收缓冲区和发送缓冲区。
一个 TCP 的套接字对是一个定义该连接的两个端点的四元组:本地 IP 地址、本地 TCP 端口号、外地 IP 地址、外地 TCP 端口号。标识每个端点的两个值(IP 地址和端口号)通常称为一个套接字。
TCP 端口号与并发服务器
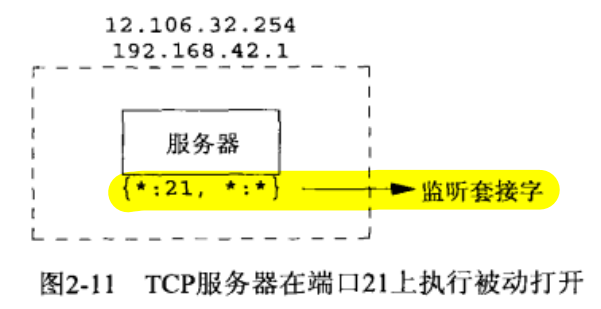
STEP1:该服务器主机是多宿的。*:* 表示监听套接字。
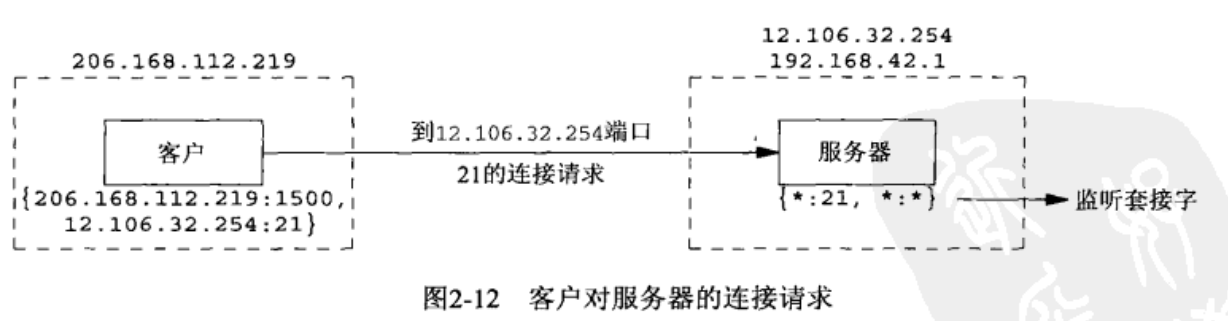
STEP2:客户主机选择临时端口 1500 连接服务器。
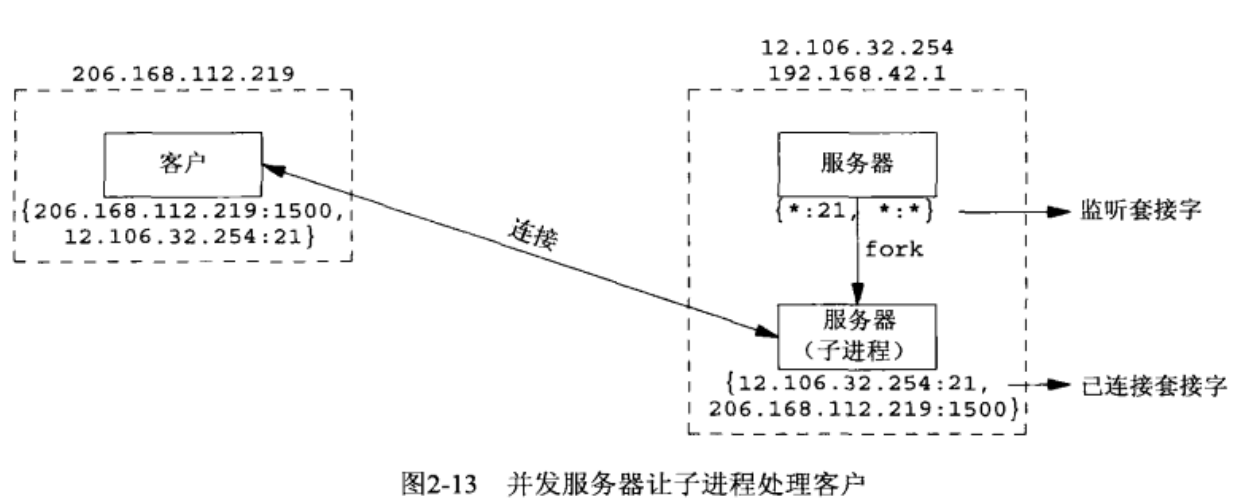
STEP3:我们必须区分已连接套接字和监听套接字。注意已连接套接字使用与监听套接字相同的本地端口(21)
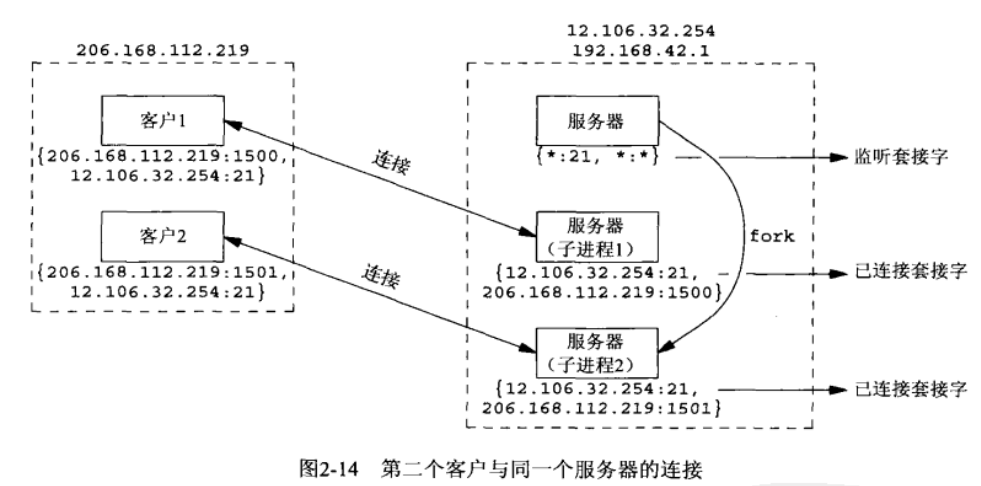
STEP4:客户主机另一个客户使用临时端口 1501 连接同一个服务器。注意第一个连接的套接字对与第二个连接的套接字对不同,因为客户选择的临时端口号不同。
必须查看套接字对的所有 4 个元素才能确定由哪个端点接收某个到达的分节,图 2-14 对于同一个本地端口(21)存在 3 个套接字。
网络地址结构
IPv4 套接字地址结构
// 用来存放因特网的 IP 地址和端口号
struct sockaddr_in
{
sa_family_t sin_family; // 地址族(Address Family)
uint16_t sin_port; // 16位TCP/UDP端口号
struct in_addr sin_addr; // 32位IP地址
char sin_zero[8]; // 不使用
}
struct in_addr
{
in_addr_t s_addr // 32位IPv4地址,整数
}
// 通用的套接字地址结构,经常将sockaddr_in强制转换为sockaddr,它是bind函数的指针参数之一
struct sockaddr
{
sa_family_t sin_family; // 地址族(Address Family)
char sa_data[14]; // 地址信息
}
// Example:
struct sockaddr_in serv_addr; // 直接向 sockaddr 填充地址信息很麻烦(要填充0)
...
// 类型强制转换
if (bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1)
error_handling("bind() error");
...
sockaddr_in 参数分析:
- sin_family:地址族,AF_INET(IPV4网络协议中使用的地址族),AF_INET6(IPV6网络协议中使用的地址族),AF_LOCAL(本地通信中采用的UNIX协议的地址族)。
- sin_port:以网络字节序保存 16 位端口号。
- sin_addr:以网络字节序保存 32 位地址信息。
- sin_zero:使结构体 sockaddr_in 的大小与结构体 sockaddr 保持一致而插入的成员,必须填充 0.

注意点:
-
32 位 IPv4 地址存在两种不同访问方法:
serv.sin_addr按照in_addr结构来引用地址。serv.sin_addr.s_addr按照in_addr_t(通常是一个无符号位的 32 位整数)来引用地址。
必须正确使用 IPv4 地址,尤其是它作为函数参数时,因为编译器对传递结构和传递整数的处理是完全不同的。
-
sin_zero 字段未曾使用,总是把它置为 0。按照惯例,我们总是在填写结构体之前,把整个结构体都置为 0。使用
bzero()函数 -
socket 地址结构仅在给定主机上使用:虽然某些字段(例如IP地址和端口号)用在不同主机之间的通信中,但是结构本身是不会在主机上传递的。
IPv6 套接字地址结构
#include <netinet/in.h>
struct in6_addr{
unit8_t s6_addr[16]; /* 128位IPv6地址 */
};
#define SIN6_LEN
struct sockaddr_in6{
uint8_t sin6_len; // 结构体长度(28)
sa_family_t sin6_family; // AF_INET6
in_port_t sin6_port;
uint32_t sin6_flowinfo; // 流信息,它的使用依然是一个课题
struct in6_addr sin6_addr; // IPv6地址
uint32_t sin6_scope_id;
};
// 新的通用的套接字地址结构
struct sockaddr_storage{
uint8_t ss_len;
sa_family_t ss_family;
...
};
新的 struct sockaddr_storage 足以容纳系统所支持的任意套接字地址结构。
-
如果系统支持的任何套接字地址结构有对齐需要,那么 sockaddr_storage 能够满足最苛刻的对齐要求。
-
sockaddr_storage 足够大,能够容纳系统支持的任何套接字地址结构。
注:除了上面呈现的两个字段外,其他字段对于用户是透明的,需要对 sockaddr_storage 进行类型强制转换后才能够访问其他字段。
网络字节序和主机字节序
字节排序函数
主机字节序(Host Byte Order)——CPU 在内存中存储数据的方式:
- 大端序(Big Endian):高位字节存放到低位地址。

- 小端序(Little Endian):高位字节存放到高位地址。

因特网的网络字节序 (Network Byte Order) 采用大端序,即先发送高位字节。例如,发送 0x66020304 的网络序为 04 03 02 66(最右边的最先发送)
字节序转换(Endian Conversations):在填充 sockaddr_in 结构体前,先要将数据转换为网络字节序。
// h:主机字节序,n:网络字节序
// s代表short,16位,用于端口号转换。
unsigned short htons(unsigned short host)
unsigned short ntohs(unsigned short net)
// l代表long,32位,用于IP地址转换。
unsigned long htonl(unsigned long host)
unsigned long ntohl(unsigned long net)
字节操纵函数
名字以 b 开头的第一组函数起源于 4.2BSD:
#include <strings.h>
// 功能:把目标字符串中指定数目的字节置为0,经常使用该函数把一个套接字地址结构初始化为0.
void bzero (void *dest, size_t nbytes);
void bcopy (const void *src, void *dest, size_t nbytes);
int bcmp (const void *ptr1, const void *ptr2, size_t nbytes);
名字以 mem 开头的第二组函数起源于 ANSI C 标准:
#include <string.h>
// 记忆方法:dest = src; 长度参数总是最后一个参数。
void *memset (void *dest, int c, size_t len);
void *memcpy (void *dest, const void *src, size_t nbytes);
int memcmp (const void *ptr1, const void *ptr2, size_t nbytes);
地址转换函数
点分十进制的字符串 --》32位网络字节序的二进制整数值:n 代表数值(numeric),a 代表地址(address)。
#include <arpa/inet.h>
// 功能:将转换结果(32位IP地址)直接保存在 in_addr 结构体中
// 返回值:成功时(字符串有效)返回1,失败时返回0
int inet_aton(const char * string, struct in_addr * addr);
// 功能:把 点分十进制的IP地址 转化为 32位IP地址。
// 返回值:成功时返回32位大端型整数值,失败时返回-1,可以检测无效的IP地址
in_addr_t inet_addr(const char * string);
注意:inet_addr 已被废弃:该函数出错时返回 INADDR_NONE常值(通常是一个32位均为1的值),有线广播地址 255.255.255.255 不能被该函数处理!
32位网络字节序的二进制整数值 --》点分十进制的字符串:
#include <arpa/inet.h>
// 功能:把 32位IP地址 转化为 点分十进制的IP地址
// 返回值:成功时返回转换后的 点分十进制数串的指针,失败时返回-1
char * inet_ntoa(struct in_addt adr);
可用于 IPv4 和 IPv6 的地址转换函数:p 代表表达(presentation),n 代表数值(numeric)。
#include <arpa/inet.h>
// 功能:将strptr所指的字符串转换为数值,并通过addrptr指针存放二进制结果。
// 返回值:若成功则为1,若输入不是有效的表达格式则为0,若出错则为-1
int inet_pton(int family, const char *strptr, void *addrptr);
// 功能:从数值格式(addrptr)转换到表达格式(strptr)
// 参数:len-目标存储单元的大小。
// 返回值:若成功则为指向结果的指针,若出错则为NULL
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len);
注:两个函数的 family 参数既可以是 AF_INET,也可以是 AF_INET6;如果以不被支持的地址族作为 family 参数,这两个函数就都返回一个错误,并将 errno 置为 EAFNOSUPPORT;
inet_ntop 函数的 strptr 参数不可以是一个空指针,调用者必须为目标存储单元分配内存并指定其大小,调用成功时,这个指针就是该函数的返回值。
网络地址初始化
客户端:声明 sockaddr_in 结构体,并初始化要连接的服务器端套接字的 IP 地址和端口号,然后调用 connect 函数。
struct sockaddr_in addr;
char *serv_ip = "211.217.168.13"
char *serv_port = "9190"
memset(&serv_addr, 0, sizeof(addr)); // 结构体变量的所有成员初始化为0
serv_addr.sin_family = AF_INET; // 指定地址族
serv_addr.sin_addr.s_addr = inet_addr(serv_ip);
serv_addr.sin_port = htons(atoi(serv_port)); // atoi--把ascii转化为int,htons—主机序到网络序
服务器:声明 sockaddr_in 结构体,初始化服务器端 IP 和端口号,可以使用 INADDR_ANY 自动获取服务器端的 IP 地址。
struct sockaddr_in addr;
char *serv_port = "9190"
memset(&serv_addr, 0, sizeof(addr)); // 结构体变量的所有成员初始化为0
serv_addr.sin_family = AF_INET; // 指定地址族
serv_addr.sin_addr.s_addr = inet_addr(INADDR_ANY); // INADDR_ANY: 监听所有(接口的)IP地址
serv_addr.sin_port = htons(atoi(serv_port)); // atoi--把ascii转化为int,htons—主机序到网络序
值-结果参数
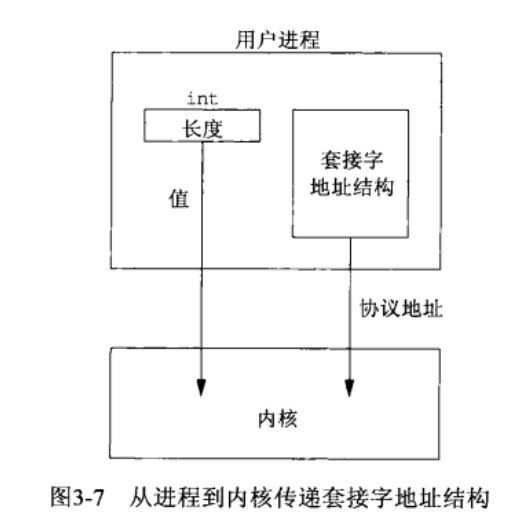
当向一个套接字函数传递一个套接字地址结构时,总是以引用传递,即传递的是一个指向结构的指针。该结构的长度也作为参数来传递,其传递的方式取决于该结构的传递的方向:从进程到内核,还是从内核到进程。
-
从进程到内核传递的套接字结构有 3 个函数:bind、connect、sendto,这三个函数的一个参数是指向套接字结构的指针,另一个是结构的大小,如:
struct sockaddr_in serv; connect(sockfd, (SA *)&serv, sizeof(serv));指针和指针所指内容的大小都传递给了内核,于是内核知道需要从进程复制多少数据进来。
-
从内核到进程传递的套接字地址结构有四个函数:accept、recvfrom、getsockname、getpeername,这些函数其中两个参数是:指向套接字结构的指针和指向表示结构大小的指针,如:
struct sockaddr_in cli; socklen_t len; len = sizeof(cli); getpeername(unixfd, (SA *)&cli, &len);
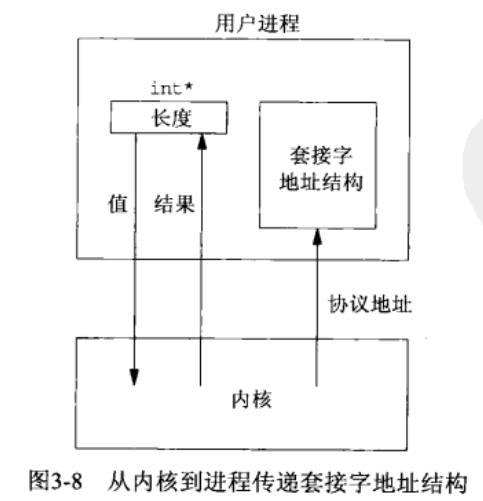
这种参数类型叫做值-结果参数:
- 当函数被调用时,结构大小是一个值(value),它告诉内核该结构大小,这样内核在写该结构时不至于越界)。
- 当函数返回时,结构大小又是一个结果(result),它告诉进程内核在该结构中存储了多少信息。
总结:当一个套接字函数需要填写一个结构时,该结构的长度也以引用形式传递,这样它的值也可以被函数更改。我们把这样的参数叫做值-结果参数。
书中自定义的读写函数
#include "unp.h"
ssize_t readn (int fildes, void *buff, size_t nbytes);
ssize_t written (int filedes, const void *buff, size_t nbytes);
ssize_t readline (int fileds, void *buff, size_t maxlen);
readn 函数:
#include <errno.h>
#include <unistd.h>
// 功能:从一个描述符读n字节
// 参数:fd-文件描述符
ssize_t readn(int fd, void *buf, size_t n) {
size_t nleft; // 剩余字节数
ssize_t nread; // 一次read读取的字节数
char *ptr;
ptr = buf;
nleft = n;
while (nleft > 0) {
if ( (nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR) {
nread = 0; /* call read() again */
} else {
return (-1);
}
} else if (nread == 0) {
break; /* EOF */
}
nleft -= nread;
ptr += nread;
}
return (n - nleft); /*return >= 0*/
}
writen 函数:
#include <unistd.h>
#include <errno.h>
// 功能:往一个描述符写n字节
// 参数:fd-文件描述符
ssize_t writen(int fd, const void *vptr, size_t n) {
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nwritten = write(fd, ptr, nleft)) <= 0) {
if (nwritten < 0 && errno == EINTR) {
nwritten = 0; /* call write() again */
} else {
return (-1); /* error */
}
}
nleft -= nwritten;
ptr += nwritten;
}
return (n - nwritten);
}
readline 函数:
#include <unistd.h>
#include <errno.h>
// 功能:从一个描述符读文本行,一次一个字节,极端地慢
ssize_t readline(int fd, void *vptr, size_t maxlen) {
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n <= maxlen; n++) {
again:
if ( (rc = read(fd, &c, 1)) == 1) {
*ptr++ = c;
if (c == '\n') {
break;
}
} else if (rc == 0) {
*ptr = 0;
return (n - 1);
} else {
if (errno == EINTR) {
goto again;
}
return (-1);
}
}
*ptr = 0;
return ((maxlen == (n-1))?(n-1):n);
}
EINTR 错误:表示系统调用被一个捕获的信号中断,如果发生该错误则继续进行读/写操作。
注意,这个 readline 函数每读一个字节的数据就调用一次系统的 read 函数。这是非常低效的。改用标准I/O函数库可以解决性能问题,但是会引发许多后勤问题,因为 stdio 缓冲区的状态是不可见的。
下面是一个 readline 函数较快速的版本。但这会导致新的问题:使用静态变量实现跨域相继函数调用的状态信息维护,使函数变得不可重入或者说非线程安全了。
#include <errno.h>
#include <unistd.h>
#define MAXLINE 4096
static int read_cnt = 0;
static char *read_ptr;
static char read_buf[MAXLINE];
static ssize_t my_read(int fd, char *ptr) {
if (read_cnt <= 0) {
again:
if ( (read_cnt = read(fd, read_buf, sizeof(read_buf))) < 0) {
if (errno == EINTR) {
goto again;
}
return (-1);
} else if (read_cnt == 0) {
return (0);
}
read_ptr = read_buf;
}
read_cnt--;
*ptr = *read_ptr++;
return (1);
}
ssize_t readline(int fd, void *vptr, size_t maxlen) {
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; n++) {
if ( (rc = my_read(fd, &c)) == 1) {
*ptr++ = c;
if (c == '\n') {
break;
}
} else if (c == 0) {
*ptr = 0;
return (n - 1);
} else {
return (-1);
}
}
*ptr = 0;
return (n);
}
ssize_t readlinebuf(void **vptrptr) {
if (read_cnt) {
*vptrptr = read_ptr;
}
return (read_cnt);
}
基本 TCP 套接字编程
socket 函数
#include <sys/socket.h>
// 功能:创建套接字(安装电话机)
// 返回值:成功时返回文件描述符,失败是返回-1。
int socket(int family, int type, int protocol);
// Example:
int tcp_socket = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
int udp_socket = socket(PF_INET, SOCK_DGRAM, IPPROTO_UDP);
固定电话和套接字其实并无太大区别,下面会利用电话机讲解套接字的创建和使用方法。
输入参数:
-
family:套接字中使用的地址簇 (Address Family) 或协议簇 (Protocol Family) 信息。
- PF_UNSPEC (未定义)
- PF_INET:IPv4
- PF_INET6:IPv6
- PF_LOCAL:本地通信的 UNIX 协议簇
- PF_PACKET:底层套接字的协议簇
注:PF 或 AF 开头的是相同的
-
type:套接字数据传输类型。
- SOCK_STREAM:流式(stream),面向连接的套接字,收发数据的套接字内部有缓冲(buffer,就是字节数组),用于 TCP 套接字。
- 可靠的:传输过程中数据不会消失。
- 按序传递的:按序传输数据。
- 基于字节的:传输的数据不存在数据边界。
- SOCK_DGRAM:数据报(datagram),面向消息的套接字,不存在连接的概念,用于 UDP 套接字。
- 不按序传递的,以数据的高速传输为目的:强调快速传输而非传输顺序。
- 不可靠的:传输的数据可能丢失也可能损毁。
- 传输的数据有数据边界。
- 限制每次传输的数据大小。
- SOCK_RAW (原始)
- SOCK_STREAM:流式(stream),面向连接的套接字,收发数据的套接字内部有缓冲(buffer,就是字节数组),用于 TCP 套接字。
-
protocol:计算机间通信使用的协议信息地址簇中的协议号。
- IPPROTO_TCP (TCP的协议号6)
- IPPROTO_UDP (UDP的协议号17)
- IPPROTO_ICMP (ICMP的协议号1)
connect 函数
#include <sys/socket.h>
// 功能:(客户端)建立与TCP服务器的连接
// 返回值:成功时返回0,失败时返回-1
int connect(int sockfd, const struct sockaddr * servaddr, socklen_t addrlen);
connect 函数导致当前套接字从 CLOSED 状态转移到 SYN_SENT 状态,若成功则再转移到 ESTABLISHED 状态。
bind 函数
#include <sys/socket.h>
// 功能:将初始化后的地址信息绑定到套接字
// 参数:sockfd—套接字文件描述符,myaddr-存有地址信息的结构体变量地址,addrlen-结构体变量的长度
// 返回值:成功时返回0,失败时返回-1
int bind(int sockfd, struct sockaddr * myaddr, socklen_t addrlen);
bind 把一个本地协议地址赋予一个套接字。调用 bind 函数可以指定一个端口号,可以指定一个 IP 地址,也可以两者都指定,还可以都不指定。
-
如果指定端口号为 0,则内核在 bind 被调用时选择一个临时端口;
-
如果 IP 地址为通配地址,那么内核将等到套接字已连接(TCP)或已在套接字上发出数据报(UDP)时才选择一个本地 IP 地址。
通配地址由常值 INADDR_ANY 来指定,其值一般为 0,它告知内核去选择 IP 地址。
// IPv4 struct sockaddr_in servaddr; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // IPv6 struct sockaddr_in6 serv; serv.sin6_addr = in6addr_any;
listen 函数(由 TCP 服务器调用)
#include <sys/socket.h>
// 功能:服务器进入等待连接请求的状态
// 参数:sock-一个未连接的套接字,将被转换为被动套接字,指示内核应接受指向该套接字的连接请求
// backlog-连接请求队列的长度
// 返回值:成功时返回0,失败时返回-1
int listen(int sock, int backlog);
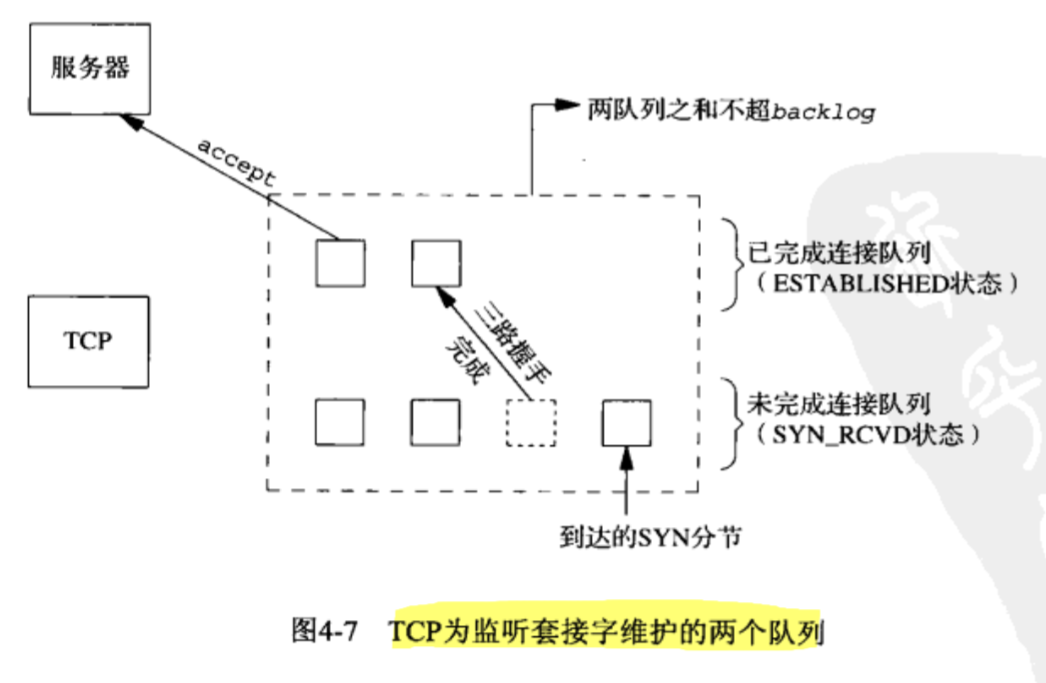
listen 把一个未连接的套接字转换成被动套接字,指示内核应接受指向该套接字的连接请求。调用 listen 导致套接字从 CLOSED 状态转移到 LISTEN。
对于参数 backlog:
- backlog 被定义为两队列总和的最大值。
- 不想接受连接时,关闭套接字,不要把 backlog 定义为 0.
accept 函数(由 TCP 服务器调用)
#include <sys/socket.h>
// 功能:从已完成连接队列队头返回下一个已完成连接。如果已完成连接队列为空,那么进程进入睡眠状态(套接字阻塞方式)
// 参数:sockfd-监听套接字,cliaddr-客户进程的地址,addrlen-该地址的大小
// 返回值:成功时返回已连接套接字,失败时返回-1
int accept(int sockfd, struct sockaddr *cliaddr, socklen_t *addrlen);
该函数最多返回三个值:
- 一个既可能是新套接字描述符也可能是出错指示的整数
- 客户进程的协议地址(由 cliaddr 所指)
- 该地址的大小(由 addrlen 所指的)
如果我们对返回客户协议地址不感兴趣,可以把后两个参数都设为空指针。
fork 和 exec 函数(并发编程基础)
fork 是 Unix 中派生新进程的唯一方法。
#include <unistd.h>
pid_t fork(void);
fork 的特点是调用它一次,它却返回两次:
- 它在调用进程(父进程)中返回新派生进程(子进程)的 ID。
- 它在子进程中返回 0。
任何子进程只有一个父进程,子进程总是可以通过调用 getppid 取得父进程的进程 ID。
fork 的 2 种典型用法:
- 一个进程创建一个自身的副本:这样每个副本都可以在另一个副本执行其他任务的同时处理各自的操作(网络服务器的典型用法)。
- 一个进程想要执行另一个程序:先调用 fork 创建出一个自身的副本,然后其中一个副本(通常为子进程)调用 exec 把自身替换成新的程序(shell 之类程序的典型用法)。
exec:将当前进程映像替换成新的程序文件,而且该新程序通常从 main 函数开始执行。进程 ID 并不改变。我们称调用 exec 的进程为调用进程(calling process),称新执行的程序为新程序(new program)。下面是 6 个 exec 函数:
#include <unistd.h>
int execl (const char *pathname, const char *arg0, ... /* (char *)0 */);
int execv (const char *pathname, char *argv[] );
int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */);
int execve (const char *pathname, char *const argv[], char *const envp[] );
int execlp (const char *pathname, const char *arg0, ... /* (char *)0 */);
int execvp (const char *pathname, char *const argv[]);
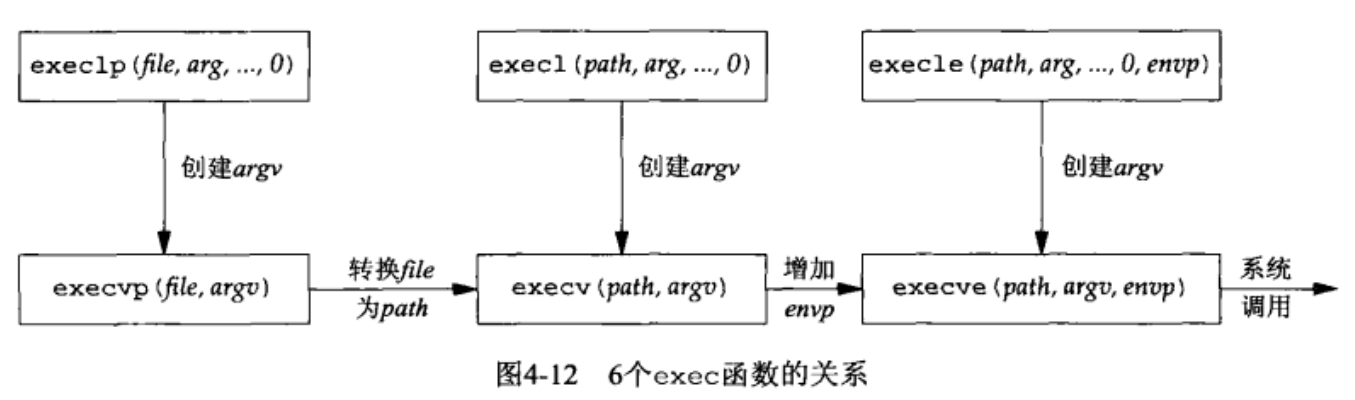
这 6 个 exec 函数的区别在于:
- 待执行的程序文件是由文件名(filename)还是由路径名(pathname)指定;
- 新程序的参数是一一列出还是由一个指针数组来引用;
- 把调用进程的环境传递给新程序还是给新程序指定新的环境。
并发服务器原理(重点)
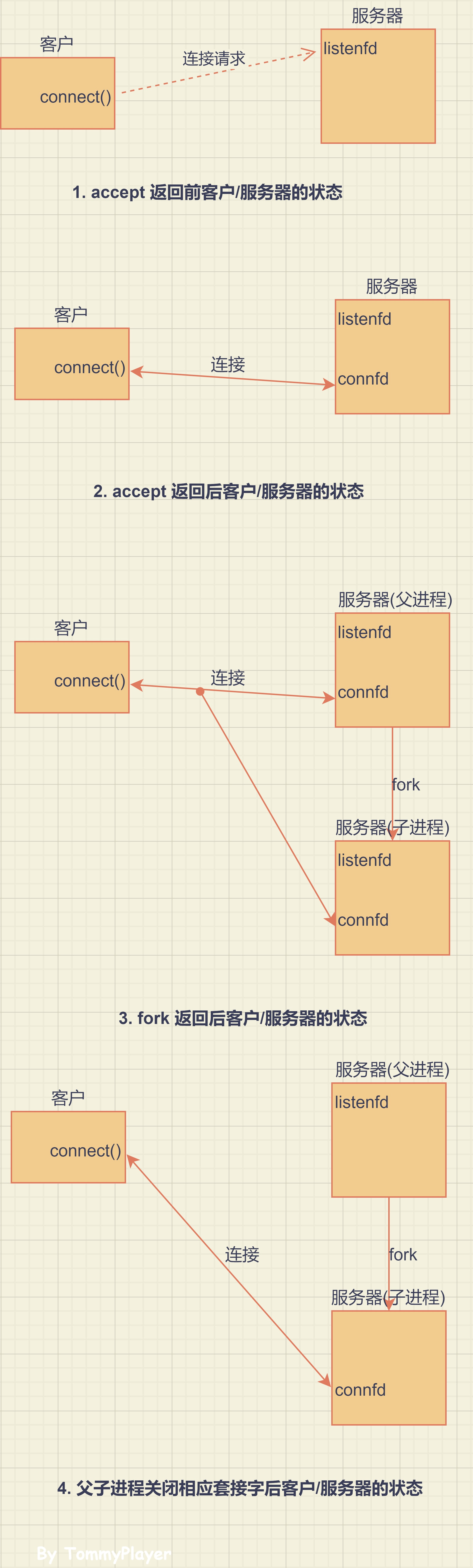
Unix 编写并发服务器最简单的方法就是 fork 一个子进程来服务每个客户。下面是一个典型的并发服务器的轮廓。
pid_t pid;
int listenfd, connfd;
listenfd = Socket( ... );
/* fill in sockaddr_in{} with server's well known port */
Bind(listenfd, ... );
Listen(listenfd, LISTENQ);
for( ; ; ){
connfd = Accept(listen, ... ); /* probably blocks*/
if( (pid = Fork()) == 0){
Close(listenfd); // 子进程关闭监听套接字
doit(connfd); // 处理请求
Close(connfd); // 完成客户端的请求后,子进程显式地关闭连接套接字
exit(0); // 上一个Close其实不是必须的,因为exit(进程终止)会关闭所有由内核打开的描述符。
}
Close(connfd); // 父进程关闭监听套接字
}
当一个连接建立时,accept 返回,服务器接着调用 fork,然后由子进程通过已连接套接字 connfd 服务客户,父进程则通过监听套接字 listenfd 等待另一个连接。既然新的客户由子进程提供服务,父进程就关闭已连接套接字。
为什么父进程对 connfd 调用 close 没有终止它与客户的连接呢?
原因:每个文件或套接字都有一个在文件表项中维护的引用计数,它是当前打开着的引用该文件或套接字的描述符的个数。fork 返回后,listenfd 和 connfd 这两个描述符在父进程和子进程间共享,它们各自的访问计数值都为 2。因此,当父进程关闭 connfd 时,只是将引用计数值从 2 减为 1,不会清理和释放该套接字的资源。
close 函数
#include <unistd.h>
// 功能:关闭套接字,终止TCP连接,导致相应的文件描述符引用值减1.
int close(int sockfd);
如果确实想要在某个TCP连接上发送一个FIN,那么可以使用shtdown函数替换close函数。
getsockname 和 getpeername 函数
#include<sys/socket.h>
// 功能:返回与某个套接字关联的本地协议地址
// 返回值:成功返回0,出错返回-1.
int getsockname (int sockfd, struct sockaddr *localaddr, socklen_t *addrlen);
// 功能:返回与某个套接字关联的外地协议地址(peer)
// 返回值:成功返回0,出错返回-1.
int getpeername (int sockfd, struct sockaddr *peeraddr, socklen_t *addrlen);
这两个函数的最后一个参数都是值-结果参数。
需要这两个函数的理由:
-
TCP 客户没有调用 bind 函数,connect 成功返回后,getsockname 用于返回由内核赋予该连接的本地 IP 地址和本地端口号。
-
在以端口号 0 调用 bind (告知内核去选择本地端口号)后,getsockname 用于返回由内核赋予的本地端口号。
-
getsockname 可用于获取某个套接字的地址族。
#include "unp.h" int sockfd_to_family(int sockfd){ struct sockaddr_storage ss; // 新的通用套接字地址结构 socklen_t len; len = sizeof(ss); if (getsockname(sockfd, (SA*)&ss, &len) < 0) return (-1); return (ss.ss_family); } -
在一个以通配 IP 地址调用 bind 的 TCP 服务器上,与某个客户的连接一旦连接,getsockname 就可以用于返回由内核赋予的本地 IP 地址。
-
当一个服务器是由调用过 accept 的某个进程通过调用 exec 执行程序时,它能够获取客户身份的唯一途径时调用 getpeername.(P95)
Linux 文件函数
Linux 系统不区分文件和套接字。
文件描述符 fd:系统分配给文件或套接字的整数。从 3 开始以由小到大的顺序编号(numbering),这是因为0、1、2 分别分配给标准输入、标准输出、标准错误。
open 函数
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 功能:打开文件
// 输入:path——文件名的字符串信息,flag——文件打开模式信息
// 返回值:成功时返回为文件描述符,失败时返回-1
int open(const char *path, int flag);
| 打开模式 | 含义 |
|---|---|
| O_CREAT | 必要时创建文件 |
| O_TRUNC | 删除全部现有数据 |
| O_APPEND | 维持现有数据,保存到其后面 |
| O_RDONLY | 只读打开 |
| O_WRONLY | 只写打开 |
| O_RDWR | 读写打开 |
close 函数
#include <unistd.h>
// 功能:关闭文件
// 输入:fd-需要关闭的文件或套接字的文件描述符
// 返回值:成功时返回0,失败时返回-1
int close(int fd)
write 函数
#include <unistd.h>
// 功能:将数据写入文件
// 输入:fd-显示数据传输对象的文件描述符,buf-保存要传输数据的缓冲地址值,nbytes-要传输的数据字节数。ssizet是通过typdef声明的signed int类型。
// 返回值:成功时返回写入的字节数,失败时返回-1
ssizet write(int fd, const void * buf, size_t nbytes)
read 函数
#include <unistd.h>
// 功能:读取文件中的数据
// 输入:fd-显示数据接收对象的文件描述符,buf-保存要接收数据的缓冲地址值,nbytes-要接收数据的最大字节数。ssizet是通过typdef声明的signed int类型。
// 返回值:成功时返回写入的字节数,失败时返回-1
ssizet read(int fd, const void * buf, size_t nbytes)

