
Effective STL 笔记-第5章 算法
5 算法
第 30 条:确保目标区间足够大。(inserter)
transform 算法:使用 front_inserter 将导致算法将结果插入到容器的头部,使用 back_inserter 将导致算法将结果插入到容器的尾部。
-
向容器末尾添加新的对象(使用 back_inserter,适用于所有提供了 push_back 方法的容器(vector,string,deque,list)):
int transmogrify(int x) // 该函数根据x生成一个新的值 vector<int> results; transform(values.begin(), values.end(), // 将transmogrify作用在values的每个对象上 back_inserter(results), // 并将返回值插入到resultes的末尾。 transmogrify); -
向容器前面添加新的对象(使用 front_inserter,适用于所有提供了 push_front 方法的容器):
int transmogrify(int x) // 该函数根据x生成一个新的值 list<int> results; transform(values.begin(), values.end(), // 将transmogrify作用在values的每个对象上 front_inserter(results), // 并将返回值以逆向顺序 transmogrify); // 插入到resultes的头部, -
将 transform 的输出结果存放在 results 的前端,同时保留它们在 values 中原有的顺序,只需按照相反方向遍历 values 即可:
int transmogrify(int x) // 该函数根据x生成一个新的值 list<int> results; transform(values.rbegin(), values.rend(), // 将transform的结果插入到容器头部, front_inserter(results), // 并保持相对顺序。 transmogrify); -
将 transform 的结果插入到容器中特定位置上:
int transmogrify(int x) // 该函数根据x生成一个新的值 list<int> results; transform(values.rbegin(), values.rend(), inserter(results, results.begin()+results.size()/2), transmogrify); // 将transform的结果插入到容器中间的位置 -
如果使用 transform 要覆盖原来的元素,第三个参数可以使用迭代器。
要在算法执行过程中增大目标区间,请使用插入型迭代器,比如 ostream_interator、back_inserter、front_inserter。
第 31 条:与排序有关的的选择。(sort相关)
-
如果需要对 vector、string、deque 或者数组中的元素执行一次完全排序,可以使用 sort 或 stable_sort。
-
如果有一个 vector、string、deque 或者数组,并且只需要对等价性最前面的 n 个元素进行排序,那么可以使用 partial_sort。
-
如果有一个 vector、string、deque 或者数组,并且需要找到第 n 个位置上的元素,或者,需要找到等价性最前面的 n 个元素但又不必对这 n 个元素进行排序,可以使用 nth_element。
-
将一个标准序列容器中的元素按照是否满足某个条件区分开来,使用 partition 和 stable_partition。
-
sort、stable_sort、partial_sort、nth_element 算法都要求随机访问迭代器,所以这些算法只能用于 vector、string、deque 和数组。
-
对于 list,可以使用 partition 和 stable_partition,可以用 list::sort 来替代 sort 和 stable_sort 算法。
实现 partial_sort 和 nth_element,需要通过间接途径。
-
性能排序:partition > stable_partion > nth_element > partial_sort > sort > stable_sort
第 32 条:如果确实需要删除元素,则需要在 remove 这一类算法之后调用 erase。
remove 是泛型算法,不接受容器作为参数,它不知道元素被存放在哪个容器中,也不可能推断出是什么容器(因为无法从迭代器推知对应的容器类型)。只有容器的成员函数才可以删除容器中的元素。
remove 不是真正意义上的删除,因为它做不到!

erase-remove 删除方式:
vector<int> v;
...
v.erase(remove(v.begin(), v.end(), 99), v.end());
例外:list 中的 remove 也应该被称为 erase,它可以真正删除元素。
两个 remove 类算法:remove_if 和 unique。
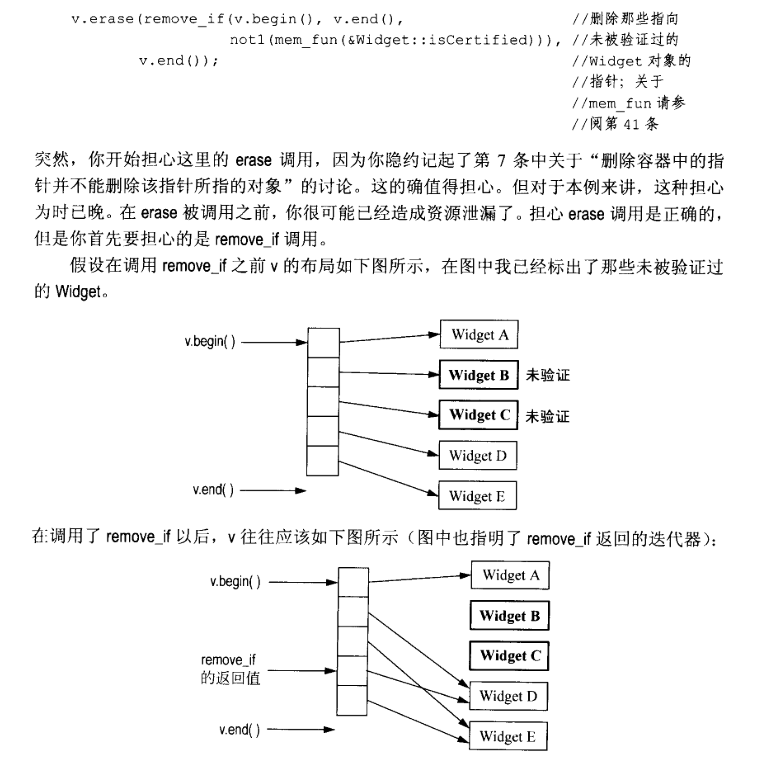
第 33 条:对包含指针的容器使用 remove 这一类算法时要特别小心。
对包含指针的容器使用 remove 这一类算法时要特别警惕,否则就是资源泄露。
使用智能指针(RSCP,Reference Counting Smart Pointer)就无需考虑这些问题。但智能指针类型(RCSP<Widget>)必须能够隐式地转换为内置指针类型(Widget*)。
第 34 条:了解哪些算法要求使用排序的区间作为参数。
要求排序区间的算法
- binary_search、lower_bound、upper_bound、equal_range:只有当这些算法接收随机访问迭代器时,才保证对数时间的查找效率。否则,尽管比较次数依然是区间元素个数的对数,执行过程需要线性时间。
- set_union、set_intersection、set_difference、set_symmetric_difference:需要排序的区间,这样能够保证线性时间内完成工作。
- merge 和 inplace_merge:实现了合并和排序的联合操作,源区间已经排过序则可以线性时间内完成。
- includes:判断一个区间中的所有对象是否都在另一个区间中,如果这两个区间排序则承诺线性时间的效率。
不一定要求排序区间,但通常情况下会与排序区间一起使用
unique 通常用于删除一个区间的所有重复值,但并非真正意义上的删除。
必须为 STL 提供一致的排序信息:如果你为一个算法提供了一个排序的区间,而这个算法也带一个比较函数作为参数,那么,你一定要保证你传递的比较函数与这个排序区间所用的比较函数有一致的行为。
所有要求排序区间的算法(除了 unique 和 unique_copy)均使用等价性来判断两个对象是否“相同”,这与标准的关联容器一致。与此相反的是,unique 和 unique_copy 在默认情况下使用“相等”来判断两个对象是否“相同”。
第 35 条:通过 mismatch 或 lexicographical_compare 实现简单的忽略大小写的字符串比较。
判断两个字符串是否相同,而不去管它们的大小写(ciCharCompare)
int ciCharCompare(char c1, char c2)
{
int lc1 = tolower(static_cast<unsigned char>(c1));
int lc2 = tolower(static_cast<unsigned char>(c2));
if (lc1 < lc2) return -1;
if (lc1 > lc2) return 1;
return 0;
}
在 C 和 C++ 中,char 可能是有符号的,可能是无符号的。tolower 的参数和返回值都是 int,但是,除非该 int 值是 EOF,否则它的值必须可以用 unsigned char 表示。
ciStringCompare
int ciStringCompareImpl(const string &s1, const string &s2);
int ciStringCompare(const string &s1, const string &s2)
{
if (s1.size() < s2.size()) return ciStringCompareImpl(s1, s2);
else return -ciStringCompare(s2, s1);
}
- 第一种实现:mismatch

//std::not2
template <class Predicate>
binary_negate<Predicate> not2 (const Predicate& pred);
//Return negation of binary function object
//Constructs a binary function object (of a binary_negate type) that returns the //opposite of pred (as returned by operator !).
// It is defined with the same behavior as:
template <class Predicate> binary_negate<Predicate> not2 (const Predicate& pred)
{
return binary_negate<Predicate>(pred);
// 二元比较后再取非。
-
第二种实现:lexicographical_compare
int ciCharCompare(char c1, char c2) { return tolower(static_cast<unsigned char>(c1)) < tolower(static_cast<unsigned char>(c2)); } bool ciStringCompare(const string &s1, const string &s2) { return lexicographical_compare(s1.begin(), s1.end(), s2.begin(), s2.end(), ciCharLess); }lexicographical_compare 是 strcmp 的一个泛化版本,可以允许用户自定义两个值的比较准则。
如果在找到不同的值之前,第一个区间已经结束了,返回 true:一个前缀比任何一个以他为前缀的区间更靠前。
第 36 条:理解 copy_if 算法的正确实现
copy_if 的正确实现:
template<typename InputIterator,
typename OutputIterator,
typename Predicate>
OutputIterator copy_if(InputIterator begin,
InputIterator end,
OutputIterator destBegin
Predicate p)
{
while (begin != end) {
if (p(*begin)) *destBegin++ = *begin;
++begin;
}
return destBegin;
}
第 37 条:使用 accumulate 或者 for_each 进行区间统计。
accumulate(计算出一个区间的统计信息)
-
std::accumulate
sum (1) template <class InputIterator, class T> T accumulate (InputIterator first, InputIterator last, T init);custom (2) template <class InputIterator, class T, class BinaryOperation> T accumulate (InputIterator first, InputIterator last, T init, BinaryOperation binary_op); -
sum:
第一种形式:有两个迭代器和一个初始值。计算 double 的总和时,初始值应该设为 0.0,否则 sum 的值不正确(每次加法的结果转换成整数后再运算)
第二种形式:使用 istream_iterator 和 istreambuf_interator(数值算法,numeric algorithm)
cout << accumulate(istream_iterator<int>(cin), istream_iterator<int>(), 0);accumulate 直接返回统计结果。
-
用法(custom)
-
计算一个容器中字符串的长度总和。
string::size_type stringLengthSum(string::size_type sumSofFar, //size_type:中的技术类型 const string &s) { return sumSoFar + s.size(); } set<string> ss; ... // 对ss中的每个元素调用stringLengthSum,然后把结果付给lengthSum,初始值为0 string::size_type lengthSum = accumulate(ss.begin(), ss.end(). static_cast<string::size_type>(0), stringLengthSum); -
计算一个区间中数值的乘积。
vector<float> vf; ... // 对vf中的每个元素调用multipies<float>,并把结果赋给product float product = accumulate(vf.begin(), vf.end(), 1.0f, multiplies<float>());初始值必须为1.0f,保证是浮点数的1。
-
for_each(对一个区间的每个元素做一个操作)
for_each 接受两个参数:一个是区间,另一个是函数(通常是函数对象),对区间中的每个元素都要调用这个函数。但这个函数只接受一个实参(即当前区间的元素)。
for_each 的函数参数允许有副作用。
for_each 返回的是一个函数对象。
举例:P134,计算一个区间中所有点的平均值。

