页表基础
页表(含二级页表、倒排页表)
1. 分页机制的基本概念
-
分页的原因:固定分区会产生内部碎片,动态分区会产生外部碎片,这两种技术在内存上的使用都是低效的。
-
分页的基本思想:内存被划分成大小相等且固定的块,块相对较小,作为主存的基本单位。每个进程也以同样大小的块为单位进行划分。
这样,进程只有在为最后一个不完整的块申请一个主存块空间时,才产生主存碎片(内部碎片),这种碎片相对于进程来说很小。每个进程平均只产生半个块大小的内部碎片。
分页不会产生外部碎片。
-
分页的几个基本概念
-
页和页大小
-
页(page):进程中的块称为页。
-
页框(page frame,也称为页帧):内存中的块称为页框。
-
进程在执行时需要申请主存,即要为每个页分配主存中的可用页框,这就产生了页和页框的一一对应。

-
页大小应该适中。页太小会导致进程的页数过多,页表过长,占用大量内存。页太大会导致内部碎片增多,降低内存利用率。
规定页和页框大小必须是 2 的幂,方便划分页号和偏移量。
-
-
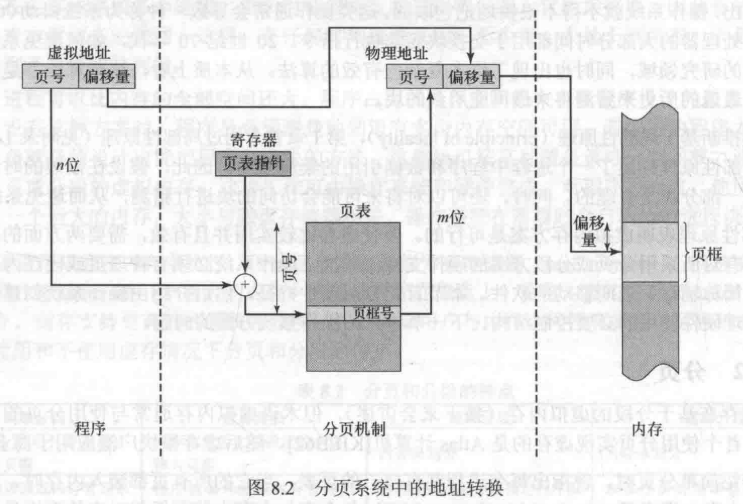
页表(page table)
- 操作系统为每个进程维护一个页表,页表给出了该进程每页所对应的页框位置。
- 给出逻辑地址 <页号,偏移量> 后,处理器使用页表得到物理地址 <页框号,偏移量> 。
2. 二级页表
-
目的:克服页表占用过大内存空间的问题,压缩页表。
例如,对于 64 位的 CPU,若页面大小为 4 KB,则页表有 2^52 个表项,如果每个页表项占 8 字节,则整个页表需要占用 8 * 2^52 Bytes = 32 PB 存储空间!实际中不可能把那么大的 页表放入连续的内存中。若不把这些页表放入连续的内存空间中,则需要一张索引表来告诉我们第几张页表该上哪里去找,这能解决页表的查询问题,且不用把所有的页表都调入内存,只在需要它时才调入。
建立多级页表的目的在于建立索引,以便不用浪费主存空间去存储无用的页表项,也不用盲目地顺序式查找页表项。
采用多级页表时,最高级页表不能超出一页大小。
若采用二级页表(如 32 位的 x86 CPU),则页号被划分成两个域:PT1 和 PT2
顶级页表(内存中)以 PT1 为索引,其表项指向二级页表,二级页表以 PT2 为索引
除顶级页表外的其他页表可以在内外存间交换
对 64 位处理器,一般采用三级页表
Linux 为了通用,采用的也是支持 64 位处理器的三级页表结构,对 32 位CPU,可以通过设中间页表的表项个数为 1 来解决。
-
具体实例
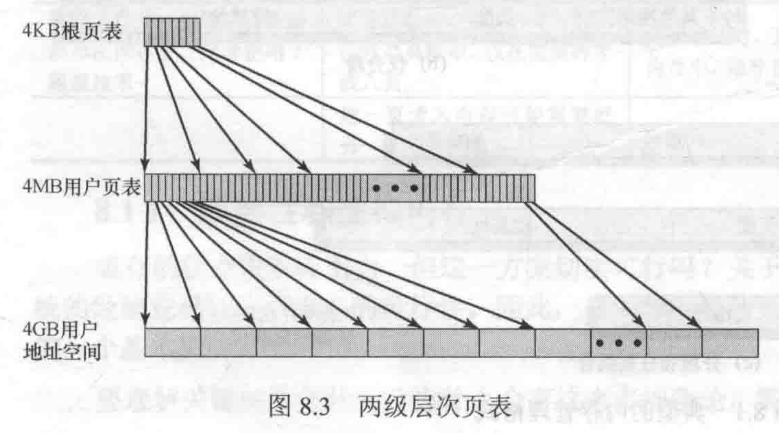
操作系统使用 32 位地址,虚拟地址空间大小为 4 GB (2^32),页大小为 4 KB (2^12),则虚拟地址空间由 2^20 页组成,每个页表项映射的大小为 4 B。
那么,一个用户页表有 2^20 页表项,大小为 2^20 * 4B(页表项大小) = 4 MB。由于在二级页表机制中,页表和其他页都服从分页管理,因此用户页表由 4 MB(用户页表内存大小) / 4 KB(页大小) = 2^10 页组成。
由于用户页表有 2^10 页,我们再用一个页表(根页表)来映射用户页表,就需要 2^10 个页表项映射。根页表大小为 2^10 * 4 B = 4 KB (2^12) 。
那么,一个 4B 的根页表项究竟能对应多大的用户内存呢?
- 1 个根页表项可以映射到 1 页的用户页表。
- 而 1 页的用户页表又包含了 4 KB(页大小) / 4 B(页表项大小)= 1k 项页表项映射。
- 每个页表项可以映射到 1 页的用户内存。
所以,1 个根页表项可以映射到 1k * 4 KB = 4 MB 用户内存。可以看到使用二级页表,每个页表项可以映射到更多的内存空间了(从 4 KB 扩大为到 4 MB)。

对于上述提到的方案,虚拟地址的前 10 位用于检索根页表,查找关于用户页表的页的页表项。
-
若该页不在内存中,则发生一次缺页中断。
-
若该页在内存中,则用虚拟地址中接下来的 10 位检索用户页表项页。
-
3. 倒排页表
前述页表设计的一个重要缺陷是,页表的大小与虚拟地址空间的大小成正比。
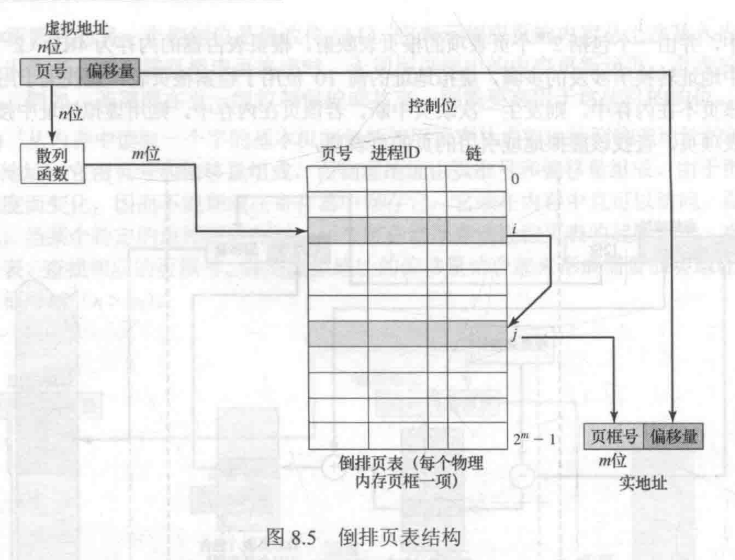
页表结构称为倒排的原因是,它使用页框号而非虚拟页号来索引页表项。
-
实际内存的每个页框对应一个页表项(而不是每个虚拟内存的页有一个页表项)
-
页表项的内容为(进程ID,页号)= (n, p),记录定位于该占用页框的进程号和页号
-
优点——当物理内存较小时,反向页表可大量节省空间
-
缺点——从虚拟地址转换到物理地址变得非常困难(不能使用CPU所提供的页框号映射机制,得自己搜索整个反向页表,查找对应于页表项 (n, p) 的页框号)
具体请看书 P218
4. 转换检测缓冲区(Translation Lookaside Buffer,TLB)
原则上,每次虚存访问都可能会引起两次物理访问:一次取相应的页表项,另一次取需要的数据。
为克服这个问题,使用一个高速缓存,通常称为转换检测缓冲区(Translation Lookaside Buffer,TLB)
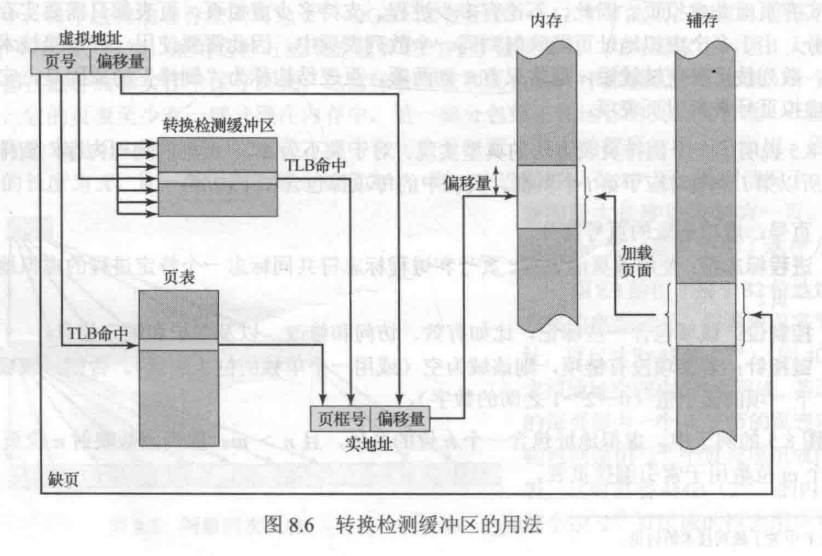
使用TLB的地址转换工作原理:
1. 给定一个逻辑地址,CPU首先到TLB去检查,判断页号在不在其中。
2. 若在(命中,hit),则直接从 TLB 中提取页框号并形成物理地址。
3. 若不在(不中/未命中,miss),则按普通访问页表方式工作,形成物理地址,并更新TLB(用新找到的页表表项替换一个TLB表项)。
不使用TLB地址转换工作原理:
1. 由页号去页表检查该页在不在内存(P位)。
2. 若在,则形成物理地址。
3. 若不在,则产生页错误(Page Fault)并发出缺页中断,由OS将页调入内存并更新页表,进而形成物理地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号