关联规则(一)简介及Apriori算法基础
关联规则数据挖掘
一、简介
1.含义
关联规则用于表示OLTP数据库中诸多属性(项集)之间的关联程度。
关联规则挖掘( Association Rules Mining)则是利用数据库中的大量数据通过关联算法寻找属性间的相关性。
2. 度量
- 支持度
同时购买A和B的客户人数占总客户数的百分比称为规则的支持度。
- 置信度
同时购买A和B的客户人数占购买A的客户人数的百分比称为规则的置信度。
由于在实际应用中,概率P一般是无法事先给出的,所以常以频度代替
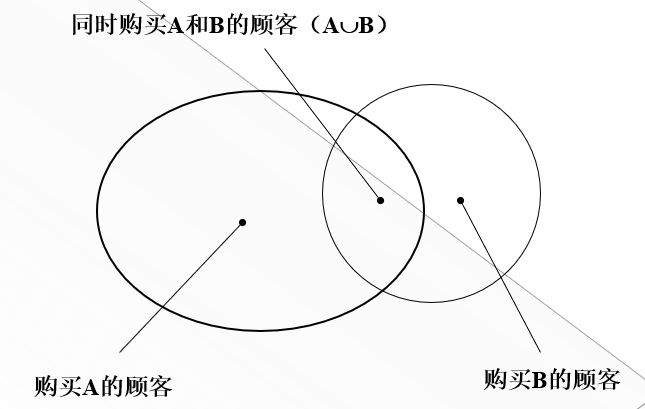
为了发现出有意义的关联规则,需要给定两个阈值:最小支持度和最小置信度。
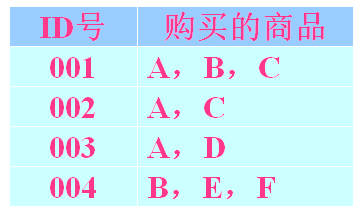
关联规则挖掘的实质是在数据集合中寻找满足用户给定的最小支持度和最小置信度的规则。例:交易情况如下表,要求最小支持度为50%, 最小可信度为 50%, 则可得到:
二、关联规则挖掘算法Apriori
1.术语
项集:在数据库中出现的属性值的集合
K项集:包含K个项的项集
频繁项集:满足最小支持度要求的项集
关联规则一定是在满足用户的最小支持度要求的频繁项集中产生的,因此,关联规则挖掘也就是在数据库中寻找频繁项集的过程。
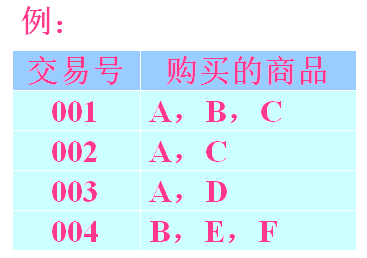
项集:\(\{A,B,C,D,E,F\}\)
1项集:\(\{A\},\{B\},\{C\},...,\{F\}\)
2项集:\(\{A,B\},\{A,C\}\)
频繁项集的任何子集也一定是频繁的
2.关联规则分类
- 根据规则中所处理的值类型
- 布尔关联规则:考虑关联项是否存在
- 量化关联规则:规则描述的是量化的项或属性间的规则
- 根据规则中所涉及的数据维
- 单维
- 多维
- 根据规则中所涉及的抽象层
3.Apriori算法
符号定义:
\(L_k\):k项频繁集的集合
\(C_k\):k项集的候补集合
步骤:
Apriori算法的流程:
Step1,K=1,计算K项集的支持度;
Step2,筛选掉小于最小支持度的项集;
Step3,如果项集为空,则对应K-1项集的结果为最终结果。
否则K=K+1,重复1-3步。
伪代码:

剪枝:
一个k-项集,如果它的一个k-1项子集不是频繁的,那它本身也不可能是频繁的。
4.关联规则挖掘的过程
关联规则挖掘过程主要包含两个阶段:
第一阶段必须先从资料集合中找出所有的频繁项集(Frequent Itemsets),
第二阶段再由这些高频项目组中产生关联规则(Association Rules)。
5.产生关联规则
同时满足最小支持度和最小置信度的才是强关联规则,从频繁项集产生的规则都满足支持度要求,而其置信度则可由以下公式计算:
关联规则的产生过程
- 对于每个频繁项集\(I\),产生\(I\)的所有非空子集;
- 对于每个非空子集\(s\),如果\(\frac{sup\_port\_count(l)}{sup\_port\_count(s)}\ge min\_conf\),则输出规则\(s\to(l-s)\)
6.Apriori的性能瓶颈
- Apriori算法的核心:
用频繁的(k-1)-项集生成候选的频繁 k-项集
用数据库扫描和模式匹配计算候选集的支持度 - Apriori的瓶颈:候选集生成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号