移动游戏的性能优化 | 材质优化篇
2024-06-07 18:14 kk20161206 阅读(381) 评论(0) 收藏 举报材质是什么
虚幻引擎是以hlsl着色语言为基础,来实现vs、ps、cs等,引擎底层提供了一套翻译系统,将hlsl翻译成gpu可执行的代码。

本篇文章限制下两个名词的定义:
● 材质:特指在虚幻引擎材质编辑界面通过连线等方式,生成的材质资源,它是蓝图系统的产物。材质资源会被转成hlsl代码,镶嵌进引擎侧的hlsl代码中,才能形成完整的着色器代码;
● Shader:特指以着色语言为基础实现的着色器代码,包括vs、ps、cs。
我们要怎么看待材质?
● 美学的具象:往往美术对美的表述是简单而抽象的,例如空气感、太单薄等等,能从自己的经验池中剥离出符合的画面并表达出来的难度是很大的。所以,我们经常也会走另外一条路径,找美术要参考画面,或者有材质基础的美术先将画面表达出来后,技术参与后续的性能优化;
● 技术的集大成:即使相同的效果,不同专业职能的同学,做出来的效率差异会非常显著。每一个独特的材质效果,都是一个独立的技术方案,不一定逊色于米尔散射、球谐光照等等专业术语的。既然是一个技术方案,就涉及很多小的技术策略的选择,有哪些算法,为什么我选择它,它有什么优点,就是我们常规的技术范式了。就以噪点函数为例,有perlin噪声、低差异序列等等,哪个算法更适合......。技术背后隐藏的决策是需要长期经验的积累,可能会涉及GPU原理、编程思维、性能优化等等。
材质是在性能达标基础上,满足指定功能性的技术方案。我觉得它最重要的两个特性是:
● 功能性
● 性能
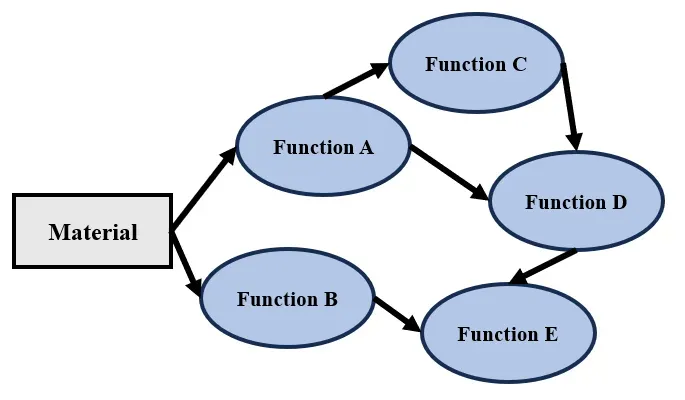
有时候,我们为了提高材质的可读性,通过函数封装的形式将材质模块化。但是,要控制好模块化的粒度,过度模块化会带来负作用的,反而降低可读性和可维护性。如下图所示,有一次去尝试迭代优化一个过度模块化的材质,需要额外打开七八个界面,脑海中还要串联它们之间的关系时,就感觉脑子晕晕的,模块化也不是那么的美好。
材质的性能包括3个方面,后面会从这三个方面进行详细分析:
● 存储开销
● 内存占用
● 运行开销
材质人力不足是常态,为了满足不断增涨的表现诉求,美术、特效、程序都成为了材质的主力,限制他们的提交是不现实的,我们只做了一点:
● 材质目录管控:标准材质库由专人提交维护,限制临时材质可提交目录,避免材质的无序堆放;希望随着后续人力资源到位,逐步梳理临时材质,迁入正式的标准材质库;
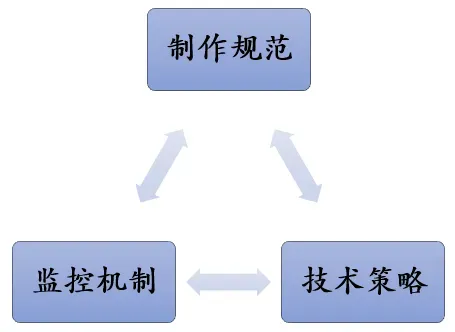
当材质人力严重不足时,问题处理起来也挺简单的,我们装死就好了,只要材质不是太过分,就假装什么都不知道。但是,随着我们产品拿到版本,逐步补充人才进组后,我就在思考这批材质要怎么优化、规范是什么、如何监控,像之前那种靠人眼逐个排查材质的思路,是行不通。于是,我开始了总结复盘,我们做了哪些,还缺少哪些,我们要达到什么样的目标。也许,我们需的是一套自动化的材质检测流程。
● 材质规范,持续完善;
● 监控机制,及时发现性能瓶颈;
● 技术策略,提供性能分析数据,优化材质系统,减少材质制作使用的性能浪费。
存储开销
1
基础变体
怎么理解材质与shader的关系呢?如下图所示,每一条路径,都能生成一个独立的shader,因此,每个材质,就能离线生成多个shader。
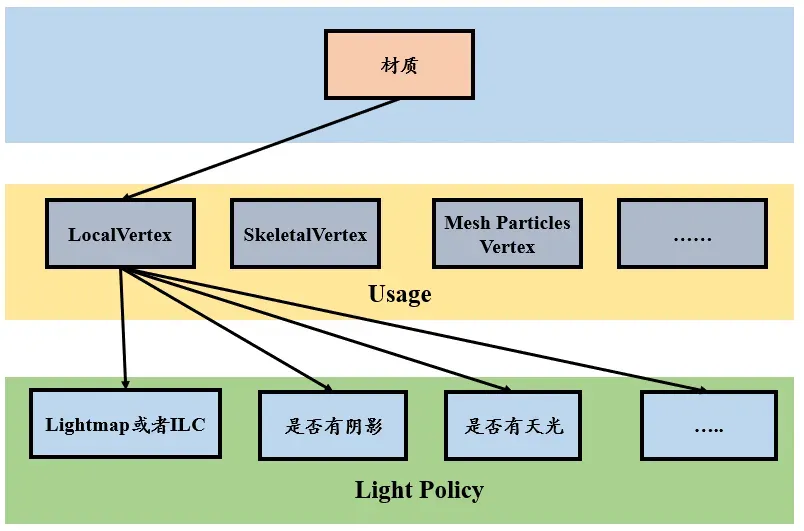
有两个维度:
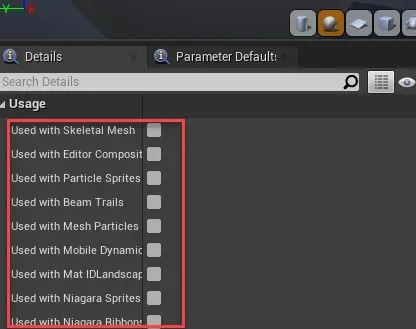
1)Usage:定义了基础了顶点格式,表示这个材质会用在哪里,例如粒子系统,或者骨骼模型等等,材质上可以通过开关来控制;
2)Lighting Policy:引擎层根据场景的表现需求,选择合理的光照方案,例如有的模型选择Lightmap,有的模型选择ILC,有的模型受到阴影投影等等。原生引擎的光照策略存在冗余,所以可以根据自身产品的光照方案,做极致的变体优化,可以显著降低shader存储,这是引擎优化内容。通常,有光材质的变体量比无光模式会多出几倍。
两个维度相乘,表示这个材质能输出的shader总数,我们称之为基础变体数。例如一个材质勾选了“Used with Skeletal Mesh”,“Used with Particle Sprites”,“Used with Beam Trails”,引擎层的光照模式是8,那么这个材质的基础变体数是3 * 8。
影响材质基础变体数的因素有4个:
● Usage
● 引擎层的光照模式数
● Blend Mode
● Shading Model,Default Lit/Unlit
2
实例变体
一个材质,可以生成多个材质实例(Material Instance),通常场景中实际用的是材质实例。
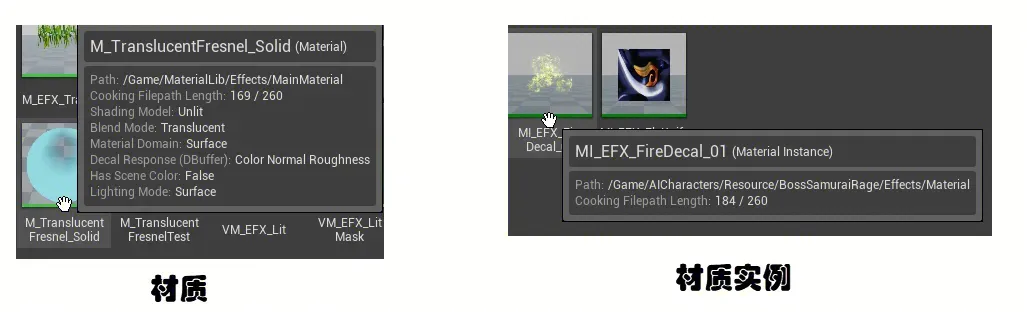
一个材质包括多个功能,这些功能通过静态开关的区分开来。如果材质中定义了4个静态开关,最终就按照2 ^ 4 = 16个实例变体来存储,就显得非常的愚蠢。因此,引擎会根据材质实例的实际使用情况,来输出最终的shader。我们称由静态开关产生的shader为实例变体。

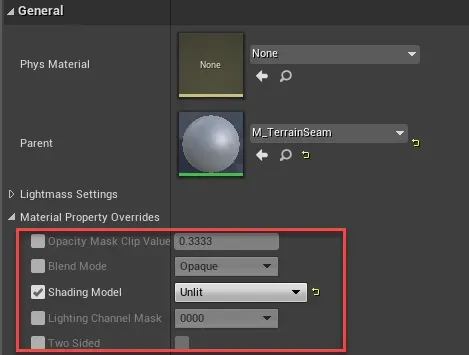
虚幻引擎支持材质实例的属性覆盖功能,如下图所示。它会导致材质生成的shader发生变化,产生新的材质变体。特别注意,如果材质的ShadingModel是Unlit,材质实例覆盖属性变成Default后,会导致基础变体数增涨严重,所以尽量要将有光和无光材质拆分开来。
3
应用策略
分析材质的存储时,需要把一个材质与它引用的所有材质实例作为一个单元来分析,变体存储的计算公式就是:基础变体数 * 实例变体数。
至此,从材质层面分析了shader存储的来源,接着通过一个案例来聊聊一些策略。
不同的特效同学实现相关性的功能,往往会重复拷贝相似的功能模块,就会产生材质的冗余,材质冗余存在两个方面的问题:变体存储和维护成本。那么,就需要一套通用的基础材质库,增强复用性。
为了降低材质的冗余性,我们期望设计一个通用母材质,开始,一切是非常美好的。随着研发持续,特效、TA持续为这个母材质添砖加瓦,导致它成为了一个庞然大物,它派生的材质实例规模庞大。特效不经意多勾选几个开关,修改几个覆盖属性,就会导致变体存在大量冗余,最终,一个材质能产生的变体量超过其它特效变体的总和。维护成本极高,不敢轻易的改动。
分析下这个材质在存储性能:
● 材质的基础变体数大,Usage勾选很多;
● 材质实例的属性覆盖功能无限制;
● 材质实例的静态开关无规则限制。
我们的初衷是:设计一套复用性强的基础材质库,它不一定是一个单一的材质,可以是一组粒度合理的材质库。
技术层面,扩展材质的功能性:
● 可以控制由它派生出的材质实例去覆盖哪些属性,例如禁用掉ShadingModel的属性覆盖;
● 可以通过规则控制静态开关的排列组合,降低材质使用者误操作导致的存储增涨;
● 有材质变体的监控机制,例如单一母材质以及相关材质实例的变体监控。
材质实现层面,也有了更高的要求,有一些准则需要去遵循:
● 材质分类,控制材质功能的粒度,减少勾选Usage开关,限制静态开关数量;
● 拆分有光和无光材质;
● 通过材质开关,限制材质实例的属性覆盖功能;
● 编写静态开关的排列规则,控制材质实例变体的无序增涨。
内存开销
UE4.24加载shader时,存在一个缺陷,是加载高中低档的材质,再根据需要,将没用到档位的材质卸载。这是一种很浪费的做法,因此需要补齐的功能是,仅加载需要用到档位的材质。将UE4引擎中的STORE_ONLY_ACTIVE_SHADERMAPS宏代码打开,再修复下遇到的BUG即可。
当材质引用一张贴图A,即使材质实例用贴图B覆盖贴图A,虚幻引擎加载材质实例时会同时缓存贴图A和贴图B,这是一种内存的浪费,从技术手段规避难度风险都比较高。我们把压力给到了制作,材质制作层面的规范:
● 材质引用的贴图必需要小贴图,保证128以内;
● 材质实例的父类必需是材质,禁止材质实例的循环嵌套。
技术层面,我们补齐自动修复工具和监控机制:
● 自动化筛查材质引用大贴图报警机制;
● 一键打破循环嵌套的修复工具
● 禁用材质实例作为父类的实例创建方式。
运行开销
1
SIMD VS SIMT
早期的移动GPU采用的是纯SIMD架构(single instruction, multiple data),每条指令运算单位是vec4。在SIMD架构下执行一个vec3的计算,它无法充分利用GPU的算力,存在一个32bit的算力浪费。

接着,移动GPU采用了SIMT(single instruction, multiple thread),改成标量架构,每个线程执行的数据单位是32bit,这样子,执行一个vec3的计算,就调度3个线程执行,不存在浪费。在这种标量架构下,一个运算单位是32bit,一个半精度是16bit,GPU会利用SIMD命令,将两个半精度填充进一个运算单元内,提高执行效率。
以arm的[valhall架构](https://developer.arm.com/documentation/102203/0100/Valhall-shader-core%20)为例,GPU不是每个时钟跑一个32bit的线程,它会把多个线程分成一组(warp)来执行,valhall采用的是16bit宽的warp,Arm称之为warp-based vectorization scheme。例如,我们执行vec3的指令运算,那么3个线程会被分到同一组内,获得一定的性能收益。
For of a single thread, this architecture looks like a stream of scalar 32-bit operations. This means that achieving high utilization of the hardware is a relative straight forward task for the shader compiler. However, the underlying hardware keeps the efficiency benefit of being a vector unit with a single set of control logic. This unit can be amortized over all of the threads in the warp.
Valhall maintains native support for int8, int16, and fp16 data types. These data types can be packed using SIMD instructions to fill each 32-bit data processing lane. This arrangement maintains the power efficiency and performance that is provided by the types that are narrower than 32-bits.
由此,得出shader优化建议:
● 尽可能使用半精度类型
● 尽可能标量跟标量运算
/* * Definition: * vec3 A, B; * float a0, b0, a1, b1, a2, b2; */ // 不推荐写法 vec3 c0 = A * a0 * a1 * a2; vec3 c1 = B * b1 * b1 * b2; vec3 c2 = c0 * c1; OutColor = vec4(c2, 1.0); // 推荐写法,尽可能标量跟标量运算 float a = a0 * a1 * a2; float b = b1 * b1 * b2; vec3 c0 = A * a; vec3 c1 = B * b; vec3 c2 = c0 * c1; OutColor = vec4(c2, 1.0); ● 尽可能将多个标量pack成向量进行运算 /* * Definition: * float a0, b0, a1, b1, a2, b2; */ // 不推荐写法 float c0 = a0 * b0; float c1 = a1 * b1; float c2 = a2 * b2; OutColor = vec4(c0, c1, c2, 1.0); // 推荐写法,尽可能将多个标量pack成向量进行运算 vec3 a = vec3(a0, a1, a2); vec3 b = vec3(b0, b1, b2); vec3 c = a * b; OutColor = vec4(c, 1.0);
● 尽可能将多个标量pack成向量进行运算
/* * Definition: * float a0, b0, a1, b1, a2, b2; */ // 不推荐写法 float c0 = a0 * b0; float c1 = a1 * b1; float c2 = a2 * b2; OutColor = vec4(c0, c1, c2, 1.0); // 推荐写法,尽可能将多个标量pack成向量进行运算 vec3 a = vec3(a0, a1, a2); vec3 b = vec3(b0, b1, b2); vec3 c = a * b; OutColor = vec4(c, 1.0);
此外,GPU load/store数据时,也是以向量数据为主。在标量架构下,标量pack为向量,依然是一种有效的优化手段。
2
分支指令
GPU执行运算的基础单元是warp,同一个warp内必需执行相同的代码。当处理器发现线程路径不一致时,它会禁用一些线程并在一条路径上执行指令,然后禁用其他线程并执行其他路径中的指令,条件判断会降低GPU的性能。

性能由好到差的三类条件判断语句,如下所示:
● 常数,编译开销
● uniform变量
● shader内的动态变量
如果uniform变量是一个数组元素,它作为条件判定的条件,开销也不低。对于一些简单的语句,我们推荐把语句展开:
● a > b ? 1.0 : -1.0,可读性高,推荐使用
● min
● max
● clamp
● step
3
Varying单元
GPU中有一个独立的硬件模块称为varying unit,用于一些由vs传出至ps的数据的插值。
例如,我们会在vs中计算好UV坐标,传到ps中进行纹理采样,ps中的UV坐标是不同顶点计算出的结果插值出来,插值计算就需要一个独立的运算单元来处理。
插值单元是一个32bit的数据运算,16bit的运算会比32bit快
两倍。推荐尽可能使用medium(16bit)类型的数据,将多个float数据封装成vec2或vec4,也会有更高的效率,例如vec4就比vec3 + float的组织形式高效。
4
贴图采样
arm的gpu上明确,贴图格式会影响采样的效率,adreno和apple不定:
● FP32,2x cost
● 3D format, 2x cost
● Depth formats, 2x cost for Utgard or Midgard, 1x on Bifrost or Valhall. But, if there is a reference or comparison depth, then it is a 2x cost, for example Shadow Maps.
● Cubemap, 1x cost per cube face.
● YUV formats, Nx cost for older than Utgard, 1x cost for Bifrost or Valhall.
案例1,在mali gpu上,基于此来分析下阴影PCF的性能。硬件PCF 2x2,需要4次采样,它的开销是8x;软件PCF 2x2,9次采样,它的开销是9x,似乎差异就没那么显著了。
案例2,在实现GTAO算法时,需要存储两个float数据到R16G16F贴图中,FP32格式的采样开销是2x,就可以将这两个float按照编码算法压缩至RGBA8中,unorm格式的采样开销是1x,从而达到降低贴图采样开销的目的。
现在的手游产品基本都会采用astc压缩,减少带宽和包体存储;利用硬件sRGB,避免软解开销。
影响贴图采样的另外一个维度是滤波方式,trilinear和anisotropic对带宽也能产生一定影响:
● point/bilinear,1x
● trilinear,2x
● anisotropic,Nx,N依赖于最大支持的层数以及实际的视角等
推荐尽量:
● 合理的贴图滤波方式
● 合理的贴图格式
● 限制采样的贴图数和单个贴图采样个数
● 避免跨度太大的随机采样,邻近采样可以提高缓存命中率
特别解释下“跨度太大的随机采样”这个点,它比较容易被忽视。GPU中存在一个称为L1/L2 Cahce的硬件单元,它们的存在,会降低多次邻近采样的性能开销。跨度太大的随机采样,降低的就是缓存的命中率,它会严重降低GPU性能,特别是带宽开销。举个例子,写一个简单的全屏后处理算法,全屏幕随机采样,可以发现后处理算法的带宽能上涨n G/sec,这在移动平台是不可能接受的。
此外,为了方便分析算法的性能,adreno官方提供了一个简化的采样开销与指令数的比率为:
● A5X GPU,16 :1
gpu性能越高,采样的开销会越低,因此在中高档设备用LUT缓存复杂的计算的思路也成为了可能性,例如,选择tonemap算法时,我们可以生成lut后缓存起来,后续只需要采样这张贴图即可,从而避免复杂的filmic tonemap、color grading、white balance的计算开销。但是,除非必要情况,并不推荐用贴图缓存计算的思路。
5
指令计算
指令计算有一些基础的特性:
● 加减法、乘法、除法,性能开销逐步增加;
● MAD形式表示为a * x + b,会被解析为一条指令运算。通常,在spirv底层解析不会显示替换FMA,它有比较严重的兼容性问题,全靠驱动的自觉性;
● 反三角函数的计算开销比较高。
我们推荐尽量:
● 尽量减少指令数
● 尽量使用MAD形式
● 尽量避免使用反三角函数等,可以用简单的算法进行拟合,例如
float atan2Fast( float y, float x ) { float t0 = max( abs(x), abs(y) ); float t1 = min( abs(x), abs(y) ); float t3 = t1 / t0; float t4 = t3 * t3; // Same polynomial as atanFastPos t0 = + 0.0872929; t0 = t0 * t4 - 0.301895; t0 = t0 * t4 + 1.0; t3 = t0 * t3; t3 = abs(y) > abs(x) ? (0.5 * PI) - t3 : t3; t3 = x < 0 ? PI - t3 : t3; t3 = y < 0 ? -t3 : t3; return t3; }
利用CPU离线计算,通过uniform变量传给shader使用。例如,指令x/a,可以提前在CPU中计算1/a,shader中只需要一个乘法就可以。举两个案例说明下核心思路。
案例1,white balance的指令优化,我们发现,绿框内的计算只需在cpu计算一次即可,通过uniform变量传给GPU,指令数能从原来的110条降低至3条。

案例2,color correction的指令优化,可以对公式进行变形,绿框内的计算可以放到cpu计算,整个算法的指令数能由57条降低至27条。

类似的,可以将一些运算放在VS中,通过varying,传给PS,因为VS的运算量是远低于PS。比如说,很多后处理的UV坐标,甚至于一些GPU设备会对这类UV采样进行优化。还比如说,在UE4引擎的移动管线中,指数雾就放在VS中计算。
在shader中,由于乘法的开销会低于除法,所以对于x / a这类运算,可以先将1/a计算后缓存起来,后续重复使用。
对于循环语句,当循环次数确定且运算不复杂,我们推荐将循环展开,可以减少寄存器占用,提高性能。
// 简单的循环函数,就推荐展开形式
for (i = 0; i < 4; ++i) { diffuse += ComputeDiffuseContribution(normal, light[i]); } // 推荐写法 diffuse += ComputeDiffuseContribution(normal, light[0]); diffuse += ComputeDiffuseContribution(normal, light[1]); diffuse += ComputeDiffuseContribution(normal, light[2]); diffuse += ComputeDiffuseContribution(normal, light[3]);
尽量避免一些特殊的语义对性能产生副作用,包括:
● alpha to coverage
● discard
● 片断着色器中写gl_FragDepth
这些语义会导致Early-ZS和HSR失效,对性能产生较大的负作用。
尽量避免隐式的类型转换。
// 贴图采样的数据是vec4,就存在隐式的类型转换,需要额外的指令槽位(Instruction Slot)。 uniform sampler2D ColorTexture; in vec2 TexC; vec3light(in vec3 amb, in vec3 diff) { vec3 Color = texture(ColorTexture, TexC); Color *= diff + amb; return Color; } // 推荐写法 uniform sampler2D ColorTexture; in vec2 TexC; vec4 light(in vec4 amb, in vec4 diff) { vec4 Color = texture(Color, TexC); Color *= diff + amb; return Color; } 要注意变量的数据类型,避免隐式转换。 // 反面例子,1.0是单精度,会导致编译器需要转成int类型 int4 ResultOfA(int4 a) { return a + 1.0; }
要注意变量的数据类型,避免隐式转换。
在一些ARM的GPU上,还有一些特殊的要求,要避免不完整的初始化,compiler不能支持未完整初始化的vec向量,会造成load/store bound,影响性能。如下所示,这个shader中z、w分量未初始化,gpu compiler不能确定这两个分量的值,因此在渲染每个像素时,都要拷贝这个变量到对应的thread中,造成读写带宽异常变大帧率下降比较明显。
vec4 TmpArray0; TmpArray0.xy = vec2(0, 1)
尽量避免在VS中采样贴图纹理,虽然现在的移动硬件都是用统一shader架构,但是一些硬件厂商会对VS做一些优化,不会引入贴图单元的数据处理流。若在VS中采样贴图,就会导致GPU对VS的优化失效。
ubo变量有很高的访问效率,优于tbo和ssbo,但是需要控制它的尺寸,尽量控制在8k以内。
UE输出的shader是基于hlsl,需要经过shader conductor解析模块,才能生成最终GPU可识别的着色代码。shader conductor的技术特点,会影响上层hlsl代码的书写规范。
避免"+="的写法。
// 反面教材 half4 Color = 0; Color += BloomDownSourceTexture.Sample(BloomDownSourceSampler, InUVs[0].xy) * 4.0; Color += BloomDownSourceTexture.Sample(BloomDownSourceSampler, InUVs[1].xy); OutColor = half4(Color.xyz, 0.0); // 解析后的语句 highp vec4 _39 = vec4(vec4(0.0)); vec4 _41 = vec4(_39 + (texture(BloomDownSource, in_var_TEXCOORD0[0].xy) * 4.0)); highp vec4 _45 = vec4(_41); vec4 _47 = vec4(_45 + texture(BloomDownSource, in_var_TEXCOORD0[1].xy)); out_var_SV_Target0 = vec4(_47.xyz, 0.0); // 推荐写法 half3 N0 = BloomDownSourceTexture.Sample(BloomDownSourceSampler, InUVs[0].xy).xyz; half3 N1 = BloomDownSourceTexture.Sample(BloomDownSourceSampler, InUVs[1].xy).xyz; OutColor = half4(N0 + N1, 0.0); // 解析后的语句 vec3 _40 = vec3(texture(BloomDownSource, in_var_TEXCOORD0[0].xy).xyz); vec3 _45 = vec3(texture(BloomDownSource, in_var_TEXCOORD0[1].xy).xyz); out_var_SV_Target0 = vec4(_40 + _45, 0.0);
定义常量时,避免带“.f”后缀,shader conductor会把带有.f后缀的常数解析为全精度,例如1.0f。
避免定义一个向量类型的变量,再对向量中的分量独立赋值的写法。
// 反面教材 half2 dir; dir.x = dirSwMinusNe + dirSeMinusNw; dir.y = dirSwMinusNe - dirSeMinusNw; // 解析后的语句 vec2 _125 = _52; _125.x = _117 + _119; vec2 _127 = _125; _127.y = _117 - _119; // 推荐写法 half2 dir = half2(dirSwMinusNe + dirSeMinusNw, dirSwMinusNe - dirSeMinusNw); // 解析后的语句 vec2 _126 = vec2(_116 + _118, _116 - _118);
语句x / a,a是一个常量时,推荐改成x * (1 / a),shader conductor解析后,会将1/a解析成一个常数,这条指令就由除法优化为乘法。
复杂的常数运算,需要自己计算好结果,shader conductor没有理想中的那么智能。
// Constants for DOF blend in. half CocMaxRadiusInPixelsRcp() { half2 MaxOffset = half2(-2.125,-0.50)*2.0; returnrcp(sqrt(dot(MaxOffset, MaxOffset))); } half2 CocBlendScaleBiasFine() { half Start = 0.0 * CocMaxRadiusInPixelsRcp(); half End = 0.5 * CocMaxRadiusInPixelsRcp(); half2 ScaleBias; ScaleBias.x = 1.0/(End-Start); ScaleBias.y = (-Start)*ScaleBias.x; return ScaleBias; } // half2 ScaleBias2 = CocBlendScaleBiasFine(); // Constant. static consthalf2 ScaleBias2 = half2(8.73212433, 0);
6
半精度
尽量提高半精度的占比是shader优化的重要目标,怎么用好半精度是一个很大的话题。
引擎的指令解析层面,需要对支持好半精度相关的解析,例如:
● 支持解析半精度指令;
● 支持解析半精度ubo,metal是半精度,vulkan/glsl是伪半精度;
● 精度类型对齐,不会出现半精度 * 全精度的情况,spirv除外。
下面我来聊一聊应用层面能怎么做。
半精度格式
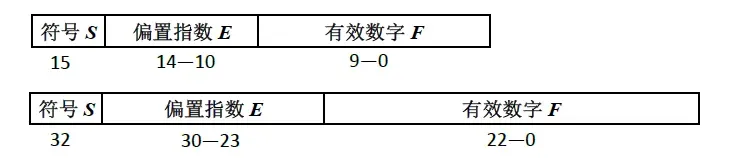
符点数格式遵循IEEE 754标准,单精度32bit,23bit有效位,8bit偏置指数位,1bit符号位;半精度16bit,10bit有效位,5bit偏置指数位,1 bit符号位。用十进制为例来简单说明精度格式的原理,例如想表示数值1532.2,有效位的作用是存储15322,偏置指数位的作用是这个小数点要放在哪个位置,符号位表示这个数值是正数还是负数。
对于绝大部分同学而言,我们不需要去深究其背后的原理,但是必需牢记半精度格式的两个特性:
● 表示的数值有限,最大只能表示65504,记住这个数字;
● 有效位只有10bit,数值越大,误差越大。例如,1~10,可能误差是0.001左右;但是5000~10000,误差可能就在1左右。
我们通常可以看到如下所示的类似采样UV的计算,由于数值越大,小数部分的误差会越来越大,最终导致渲染出现马赛克。
half2 TexCoord = frac(Time * Tiling);
由于半精度表示的数值有限,通常坐标运算不能用半精度运算。采样贴图用的坐标用半精度计算的话,有一定风险,不一定有问题。
半精度问题产生的渲染异常,通常是马赛克、噪点等等。由于驱动的兼容性异常,甚至会导致某些设备闪退。
怎么用
虚幻引擎中,半精度类型用half表示,全精度类型用float表示,挺容易理解的。
注意避免全精度污染问题,非常重要!通过添加类型强转,可以保证解析后的指令是半精度。
// 反面教材 // 只要运算指令中存在全精度,整个语句都会按照全精度解析; /* * float A; * half B, C, D; */ half F = A * C * D * B; // 推荐写法 half F = half(A) * C * D * B; 当存在uniform变量时,往往会遗忘全精度污染问题。 // 反面教材 float4 GammaAndAlphaValues; half4 main(VertexToPixelInterpolants VIn) : SV_Target0 { half4 OutColor = SceneColorTexture.Sample(SceneColorTextureSampler, VIn.TexCoords.xy); OutColor = pow(OutColor, GammaAndAlphaValues.x); return OutColor; } // 推荐写法 float4 GammaAndAlphaValues; half4 main(VertexToPixelInterpolants VIn) : SV_Target0 { half4 OutColor = SceneColorTexture.Sample(SceneColorTextureSampler, VIn.TexCoords.xy); OutColor = pow(OutColor, half(GammaAndAlphaValues.x)); return OutColor; }
对于半精度ubo变量,认为有半精度修饰,就可以不用转型强转,其实这是错误的思路。因为spirv和msl支持半精度ubo,但是glsl不支持半精度ubo的解析,因此不管uniform是否有半精度修饰,必需把它们作为全精度看待。shader conductor指令解析,会将冗余的类型强转优化掉。
再聊聊材质层面的使用建议。材质上有两个功能单元:
● 可变参数,引擎会将它翻译成uniform变量;
● 运算符,引擎会根据它的连线情况,翻译成半精度指令。
如下图所示的例子,像这样的蓝图连线,引擎生成的HLSL的代码如下所示,这存在全精度污染问题。
// Material_VectorExpressions是uinform half4 Local0 = ProcessMaterialColorTextureLookup(Texture2DSample(Material_Texture2D_0, Material_Texture2D_0Sampler, Parameters.TexCoords[0].xy)); half Local1 = Material_VectorExpressions[1].rgb * Local0.r;
材质层面普遍存在全精度污染问题。技术优化手段是,在材质蓝图生成HLSL代码时,针对材质的uniform变量,显式增加一个半精度类型转换。
half4 Local0 = ProcessMaterialColorTextureLookup(Texture2DSample(Material_Texture2D_0, Material_Texture2D_0Sampler, Parameters.TexCoords[0].xy)); half Local1 = half3(Material_VectorExpressions[1].rgb) * Local0.r;
怎么调试
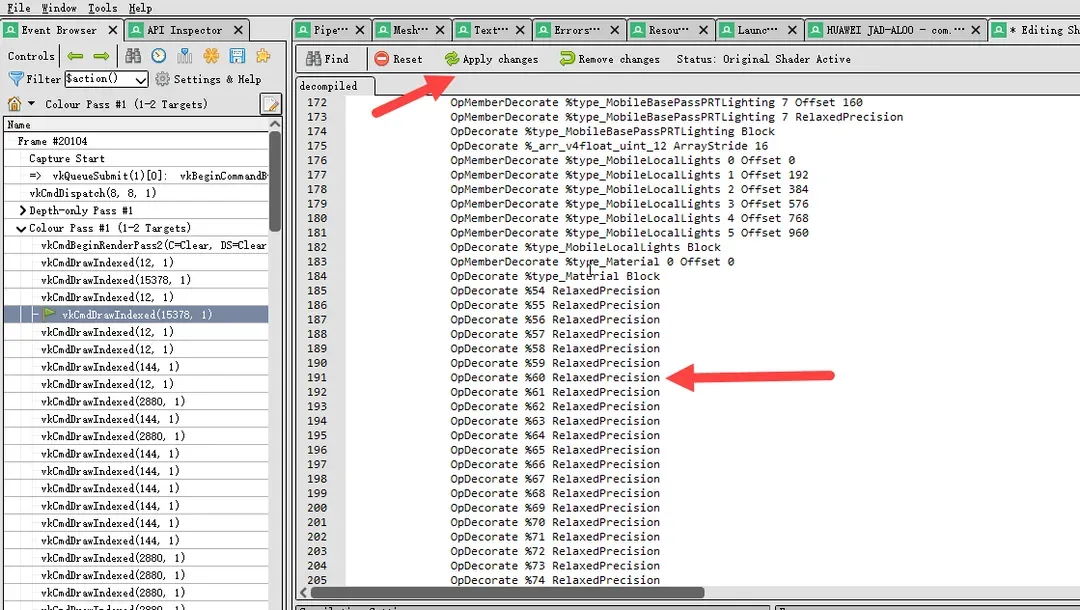
我们经常能遇到半精度引起的渲染异常,因为编辑器上不支持半精度,只有移动平台支持,材质的制作和使用者不能即时的发现问题。如果发现异常的情况,可以用Render Doc截帧调试。以vulkan为例,简单说明下调试方法。
1)启动游戏,找到异常的drawcall,选中FS,点击Edit后的下拉框,会有3个选项:Decompile with SPRIV-Cross,spirv会转换成glsl呈现出来,可读性相对较高;Decompile with spirv-dis,spirv的文本形式。glsl是render doc由spirv翻译来的,spirv是GPU执行的真实代码。偶尔会遇到glsl表现正常,但是spirv表现异常的情况。

2)修改源码,点击“Apply changes”,可以即时看到渲染结果。为了快速排查是否是半精度导致的异常,可以将spirv内所有带RelaxedPrecision的语句删除或者将glsl内所有的mediump修饰符删除。
7
监控机制
离线分析shader的性能工具有adreno offline compiler和mali offline compiler,我们可以在材质编辑器上集成这些工具,将指令数和采样数呈现出来。
我们想要的是什么:
● 监控整体的材质性能数据;
● 及时发现开销过高的材质。
经过前面的分析,材质方面有多个特点:
● 一个材质及其实例,会涵盖大量的变体,选择单一类型变体不具备普适性;
● 引擎层面的改造,影响材质层面的性能监控。
技术策略:
● 指令数数据要落实到每个变体,放到cook生成的变体csv表中;
● 增加基准材质的指令数识别,通过差值就可以统计出材质层面的指令现状,排除引擎层面的影响;
● 增加周期性的性能数据呈现;
● 持续完善检测报警机制,通过自动化的手段,更早的发现并解决问题。例如,我们发现引擎材质内置的Noise函数性能开销极高,那么我们就可以增加一条监测规则,用上Noise函数的材质就报警。
https://mp.weixin.qq.com/s/vuoRsRKWNx0AzA6gupM8Zw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号