


中文词频统计与词云生成
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822
中文词频统计
1. 下载一长篇中文小说。
下载长篇小说《西游记》
本次作业小说保存在txt文档:xyj.txt
2. 从文件读取待分析文本。
xyj = open(r'F:/xyj.txt','r',encoding='utf-8').read() wordsls = jieba.lcut(xyj)
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
jieba.lcut(text)

4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word('天罡北斗阵') #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
jieba.add_word('美猴王')
参考词库下载地址:https://pinyin.sogou.com/dict/
转换代码:scel_to_text
# -*- coding: utf-8 -*- import struct import os # 拼音表偏移, startPy = 0x1540; # 汉语词组表偏移 startChinese = 0x2628; # 全局拼音表 GPy_Table = {} # 解析结果 # 元组(词频,拼音,中文词组)的列表 # 原始字节码转为字符串 def byte2str(data): pos = 0 str = '' while pos < len(data): c = chr(struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]) if c != chr(0): str += c pos += 2 return str # 获取拼音表 def getPyTable(data): data = data[4:] pos = 0 while pos < len(data): index = struct.unpack('H', bytes([data[pos],data[pos + 1]]))[0] pos += 2 lenPy = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] pos += 2 py = byte2str(data[pos:pos + lenPy]) GPy_Table[index] = py pos += lenPy # 获取一个词组的拼音 def getWordPy(data): pos = 0 ret = '' while pos < len(data): index = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] ret += GPy_Table[index] pos += 2 return ret # 读取中文表 def getChinese(data): GTable = [] pos = 0 while pos < len(data): # 同音词数量 same = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表长度 pos += 2 py_table_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表 pos += 2 py = getWordPy(data[pos: pos + py_table_len]) # 中文词组 pos += py_table_len for i in range(same): # 中文词组长度 c_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 中文词组 pos += 2 word = byte2str(data[pos: pos + c_len]) # 扩展数据长度 pos += c_len ext_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 词频 pos += 2 count = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 保存 GTable.append((count, py, word)) # 到下个词的偏移位置 pos += ext_len return GTable def scel2txt(file_name): print('-' * 60) with open(file_name, 'rb') as f: data = f.read() print("词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030') print("词库类型:", byte2str(data[0x338:0x540])) print("描述信息:", byte2str(data[0x540:0xd40])) print("词库示例:", byte2str(data[0xd40:startPy])) getPyTable(data[startPy:startChinese]) getChinese(data[startChinese:]) return getChinese(data[startChinese:]) if __name__ == '__main__': # scel所在文件夹路径 in_path = r"F:\text" #修改为你的词库文件存放文件夹 # 输出词典所在文件夹路径 out_path = r"F:\text" # 转换之后文件存放文件夹 fin = [fname for fname in os.listdir(in_path) if fname[-5:] == ".scel"] for f in fin: try: for word in scel2txt(os.path.join(in_path, f)): file_path=(os.path.join(out_path, str(f).split('.')[0] + '.txt')) # 保存结果 with open(file_path,'a+',encoding='utf-8')as file: file.write(word[2] + '\n') os.remove(os.path.join(in_path, f)) except Exception as e: print(e) pass
5. 生成词频统计
wcdict = {} for word in tokens: if len(word)==1: continue else: wcdict[word] = wcdict.get(word,0)+1
6. 排序
wcls = list(wcdict.items())
wcls.sort(key=lambda x:x[1],reverse=True)
for i in range(20): print(wcls[i])
7. 排除语法型词汇,代词、冠词、连词等停用词。
stops
tt = open(r'F:/stops_chinese.txt','r',encoding='utf-8').read() stops = tt.split()
·排除
wordsls = jieba.lcut(xyj) tokens = [token for token in wordsls if token not in stops]
8. 输出词频最大TOP20,把结果存放到文件里
import jieba xyj = open(r'F:/xyj.txt','r',encoding='utf-8').read() tt = open(r'F:/stops_chinese.txt','r',encoding='utf-8').read() stops = tt.split() #jieba.load_userdict(r'F:\text/xyj.txt') wordsls = jieba.lcut(xyj) tokens = [token for token in wordsls if token not in stops] print(len(wordsls),len(tokens)) wcdict = {} for word in tokens: if len(word)==1: continue else: wcdict[word] = wcdict.get(word,0)+1 wcls = list(wcdict.items()) wcls.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(wcls[i])

9. 生成词云。
(1)词云安装

显示词云:
cut_text = " ".join(tokens) from wordcloud import WordCloud ciyun = WordCloud().generate(cut_text) import matplotlib.pyplot as plt plt.imshow(ciyun) plt.axis("off") plt.show()
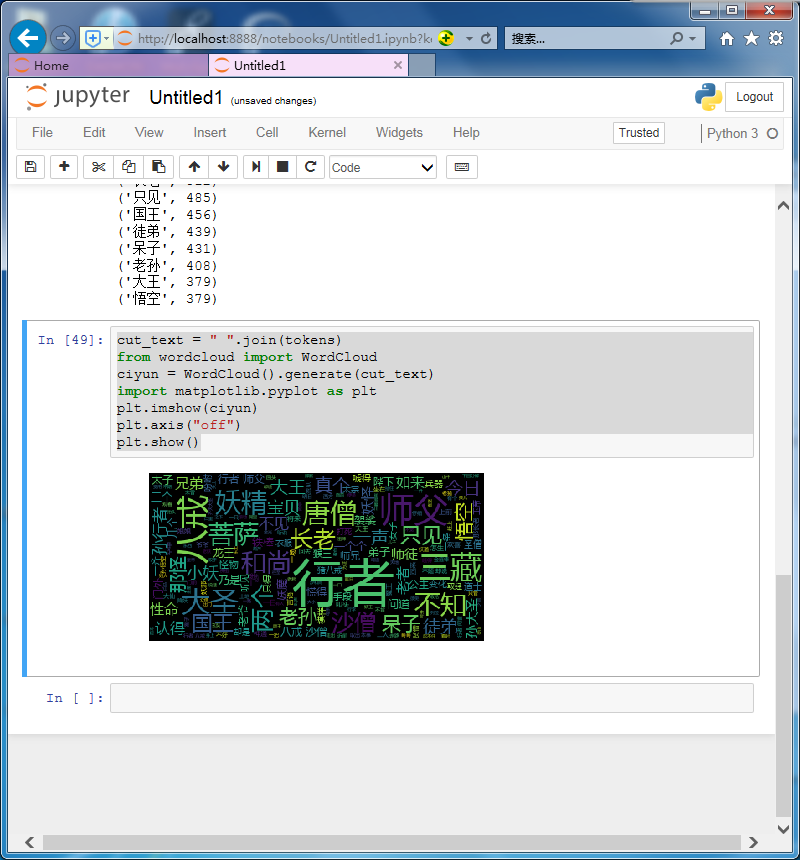
保存词云图片
ciyun.to_file(r'F:\xyj.jpg')
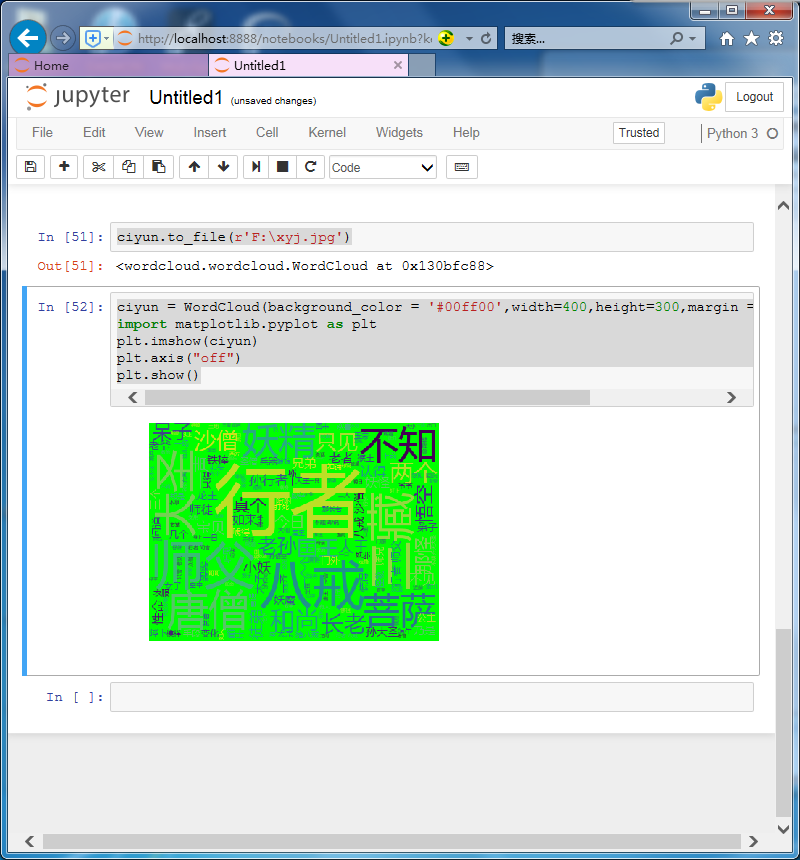
改变词云长度和宽度,背景颜色
ciyun = WordCloud(background_color = '#00ff00',width=400,height=300,margin = 1).generate(cut_text) import matplotlib.pyplot as plt plt.imshow(ciyun) plt.axis("off") plt.show()
改变词云形状
from scipy.misc import imread im = imread(r'F:/1.jpg') ciyun1 = WordCloud(background_color = '#0000FF',mask = im,margin = 2).generate(cut_text) import matplotlib.pyplot as plt plt.imshow(ciyun1) plt.axis("off") plt.show()



